Amazon DataZone Now Generally Available – Collaborate on Data Projects across Organizational Boundaries
Today, we’re announcing the general availability of Amazon DataZone, a new data management service to catalog, discover, analyze, share, and govern data between data producers and consumers in your organization.
 At AWS re:Invent 2022, we preannounced Amazon DataZone, and in March 2023, we previewed it publicly.
At AWS re:Invent 2022, we preannounced Amazon DataZone, and in March 2023, we previewed it publicly.
During the keynote of the last re:Invent, Swami Sivasubramanian, vice president of Databases, Analytics, and Machine Learning at AWS said “I have had the benefit of being an early customer of DataZone to run the AWS weekly business review meeting where we assemble data from our sales pipeline and revenue projections to inform our business strategy.”
During the keynote, a demo led by Shikha Verma, head of product for Amazon DataZone, demonstrated how organizations can use the product to create more effective advertising campaigns and get the most out of their data.
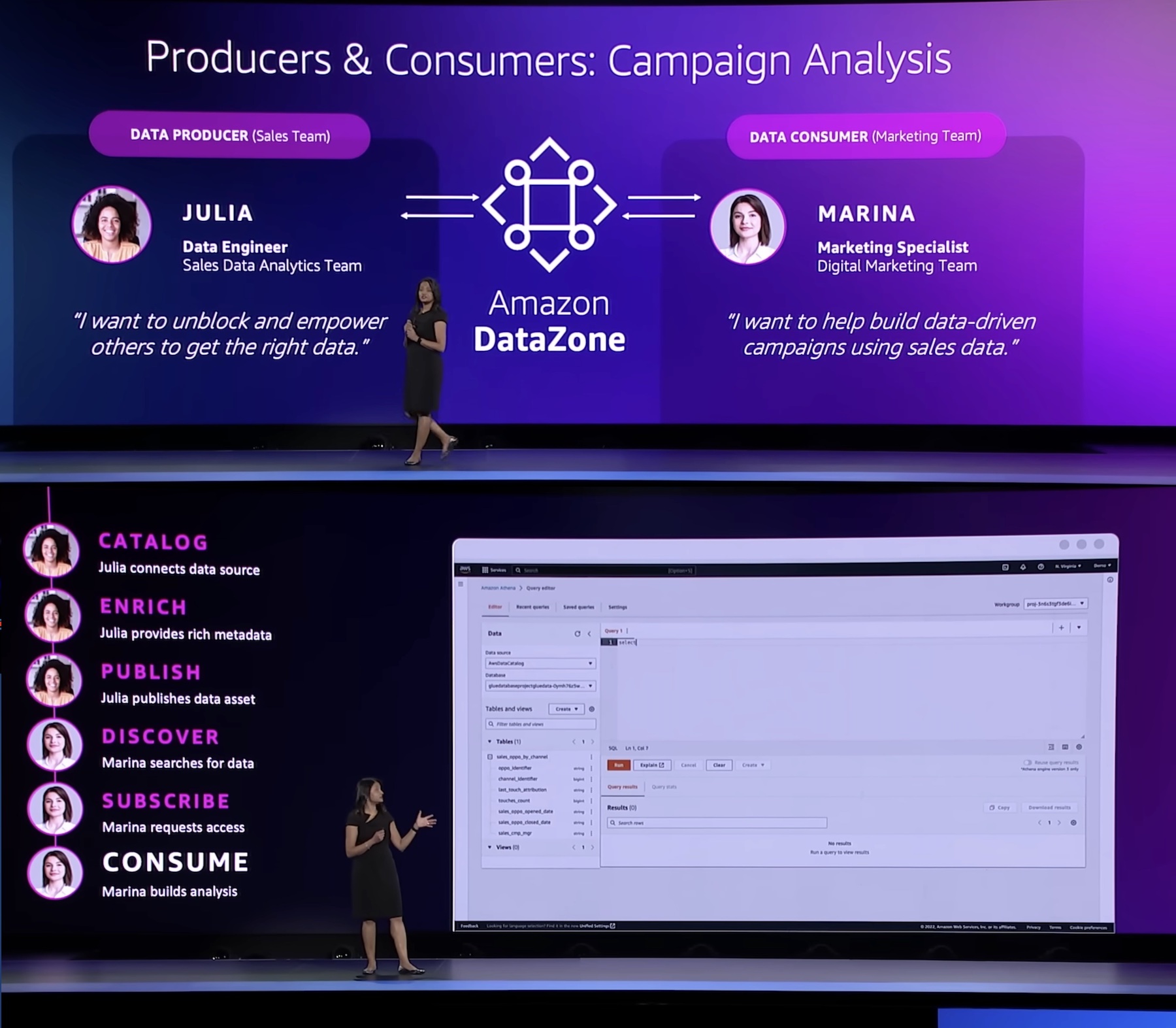
“Every enterprise is made up of multiple teams that own and use data across a variety of data stores. Data people have to pull this data together but do not have an easy way to access or even have visibility to this data. DataZone provides a unified environment where everyone in an organization—from data producers to consumers, can go to access and share data in a governed manner.”
With Amazon DataZone, data producers populate the business data catalog with structured data assets from AWS Glue Data Catalog and Amazon Redshift tables. Data consumers search and subscribe to data assets in the data catalog and share with other business use case collaborators. Consumers can analyze their subscribed data assets with tools—such as Amazon Redshift or Amazon Athena query editors—that are directly accessed from the Amazon DataZone portal. The integrated publishing-and-subscription workflow provides access-auditing capabilities across projects.
Introducing Amazon DataZone
For those of you who aren’t yet familiar with Amazon DataZone, let me introduce you to its key concept and capabilities.
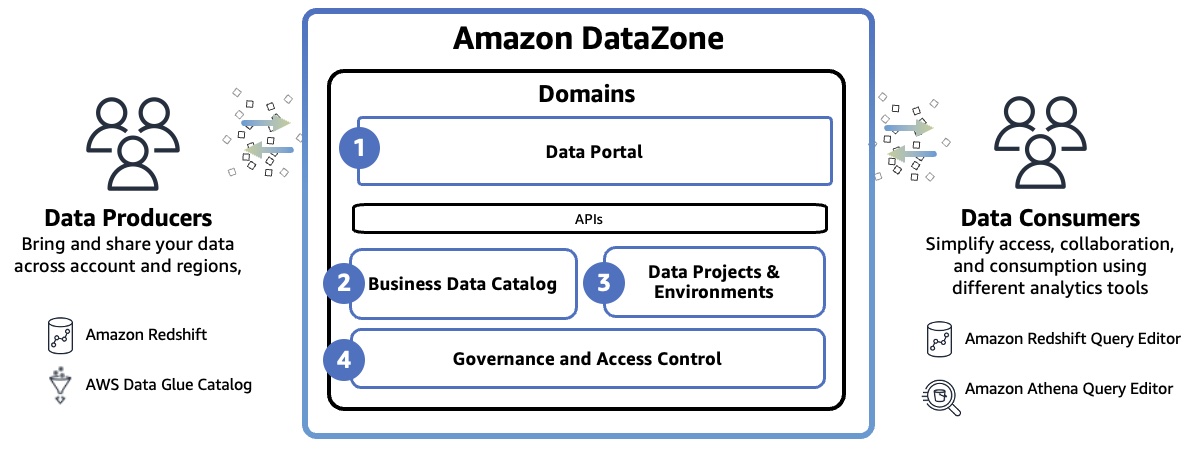
Amazon DataZone Domain represents the distinct boundary of a line of business (LOB) or a business area within an organization that can manage it’s own data, including it’s own data assets and its own definition of data or business terminology, and may have it’s own governing standards. The domain includes all core components such as the data portal, business data catalog, projects and environments, and built-in workflows.
- Data portal (outside the AWS Management Console) – This is a web application where different users can go to catalog, discover, govern, share, and analyze data in a self-service fashion. The data portal authenticates users with AWS Identity and Access Manager (IAM) credentials or existing credentials from your identity provider through the AWS IAM Identity Center.
- Business data catalog – In your catalog, you can define the taxonomy or the business glossary. You can use this component to catalog data across your organization with business context and thus enable everyone in your organization to find and understand data quickly.
- Data projects & environments – You can use projects to simplify access to the AWS analytics by creating business use case–based groupings of people, data assets, and analytics tools. Amazon DataZone projects provide a space where project members can collaborate, exchange data, and share data assets. Within projects, you can create environments that provide the necessary infrastructure to project members such as analytics tools and storage so that project members can easily produce new data or consume data they have access to.
- Governance and access control – You can use built-in workflows that allow users across the organization to request access to data in the catalog and owners of the data to review and approve those subscription requests. Once a subscription request is approved, Amazon DataZone can automatically grant access by managing permission at underlying data stores such as AWS Lake Formation and Amazon Redshift.
To learn more, see Amazon DataZone Terminology and Concepts.
Getting Started with Amazon DataZone
To get started, consider a scenario where a product marketing team wants to run campaigns to drive product adoption. To do this, they need to analyze product sales data owned by a sales team. In this walkthrough, the sales team, which acts as the data producer, publishes sales data in Amazon DataZone. Then the marketing team, which acts as the data consumer, subscribes to sales data and analyzes it in order to build a campaign strategy.
To understand how the DataZone works, let’s walk through a condensed version of the Getting started guide for Amazon DataZone.
1. Create a Domain
When you first start using DataZone, you start by creating a domain and all core components such as business data catalog, projects, and environments in the data portal, then exist within that domain. Go to the Amazon DataZone console and choose Create domain.
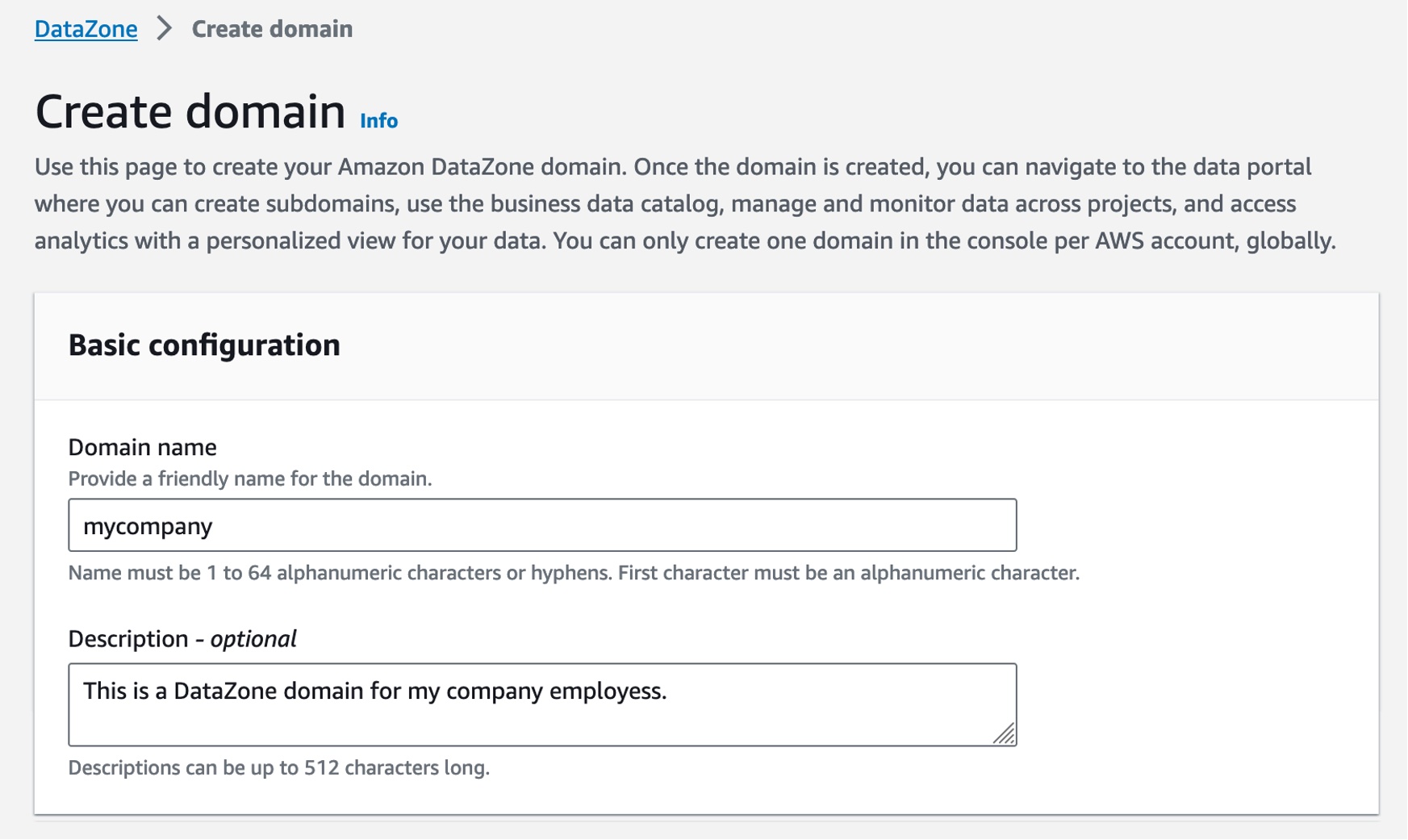
Enter Domain name and a descrption and leave all other values as default.
For example, in the Service access section, if you choose Create and use a new role by default, Amazon DataZone will automatically create a new role with necessary permissions that authorize DataZone to make API calls on behalf of users within the domain. Check the Quick setup option where DataZone can take care of all the setup steps.
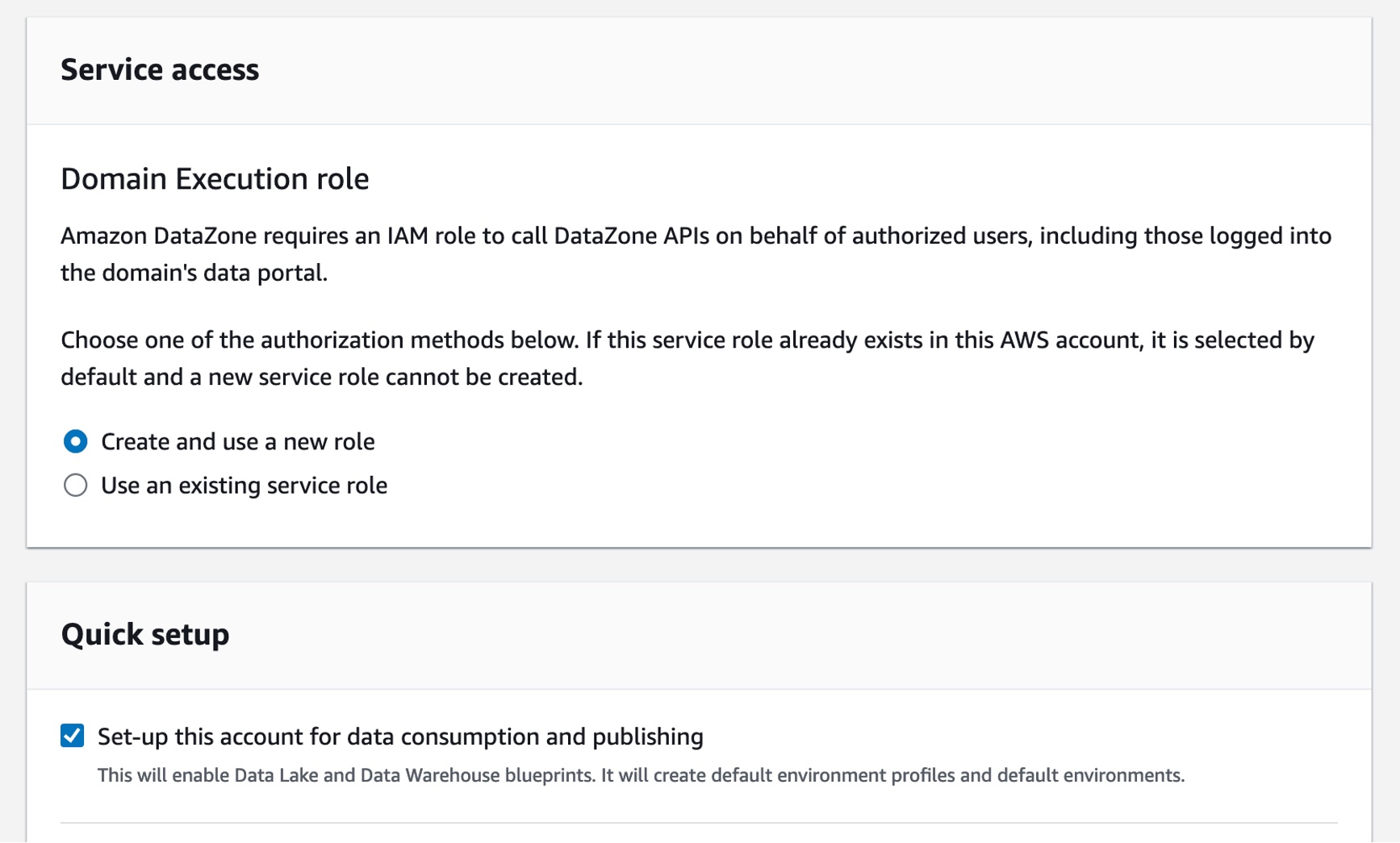
Finally, choose Create domain. Amazon DataZone creates the necessary IAM roles and enables this domain to use resources within your account such as AWS Glue Data Catalog, Amazon Redshift, and Amazon Athena. Domain creation can take several minutes to complete. Wait for the domain to have a status of Available.
2. Create a Project and Environment in the Data Portal
After the domain is successfully created, select it, and on the domain’s summary page, note the data portal URL for the root domain. You can use this URL to access your Amazon DataZone data portal. Choose Open data portal.
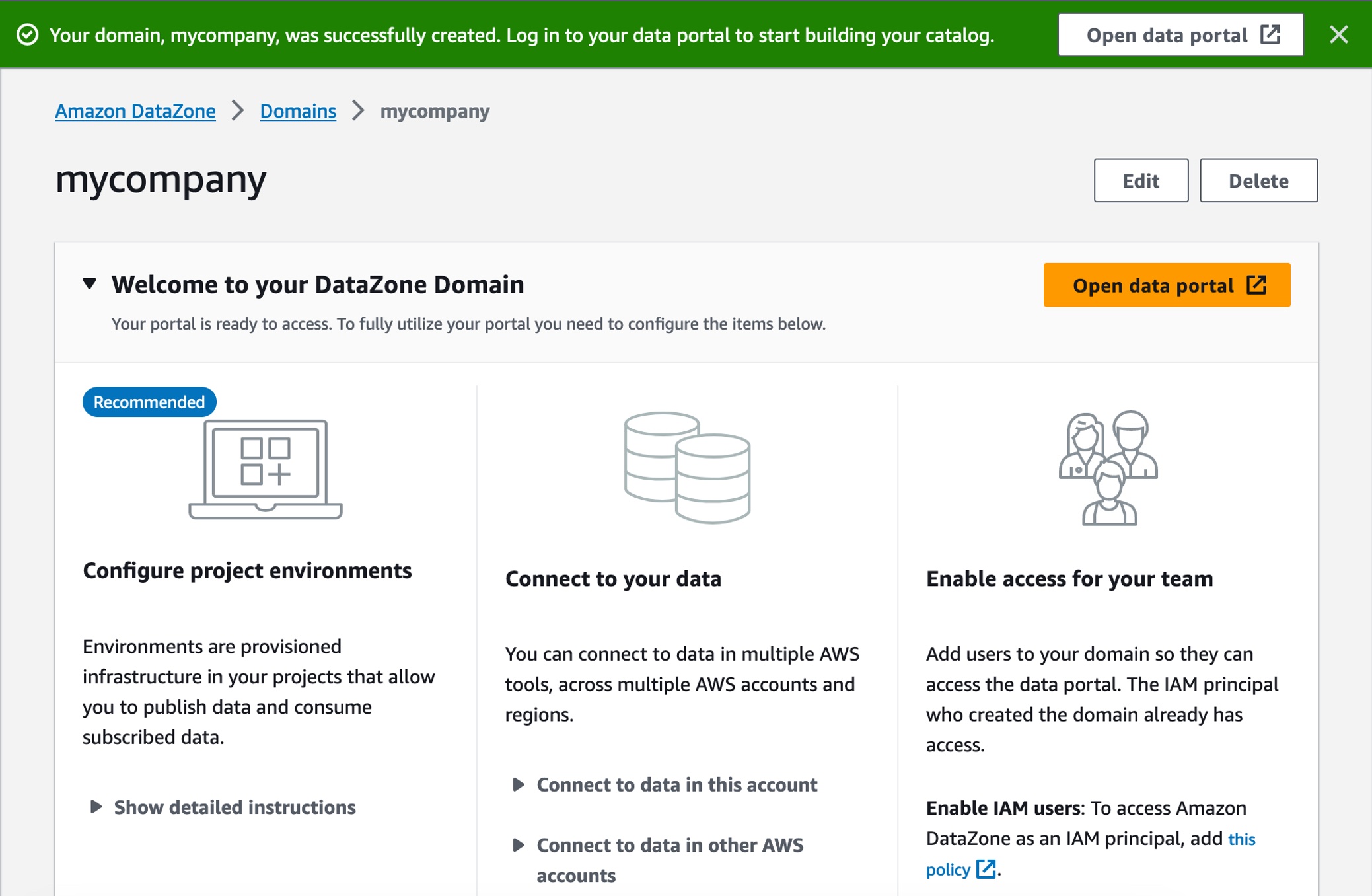
To create a new data project as the sales team to publish sales data, choose Create Project.

In the dialogbox, enter “Sales producer project” as the Name, then enter a Description for this project and choose Create.

Once you have the project, you need to create a environment to work with data and analytics tools such as Amazon Athena or Amazon Redshift in this project. Choose Create environment in the overview page or after clicking the Environment tab.

Enter “publish-environment” as the Name, then enter a Description for this environment and choose Environment profile. An environment profile is a pre-defined template that includes technical details required to create an environment such as which AWS account, Region, VPC details, and resources and tools are added to the project.
You can select a couple of default environment profiles. Choosing DataLakeProfile enables you to publish data from your Amazon S3 and AWS Glue based data lakes. It also simplifies querying the AWS Glue tables that you have access to using Amazon Athena.

Next, ignore all the optional parameters and choose Create environment. It takes about a minute for the environment to create certain resources in your AWS account such as IAM roles, an Amazon S3 suffix, AWS Glue databases, and an Athena workgroup, which makes it easier for members of a project to produce and consume data in the data lake.
3. Publish Data in the Data Portal
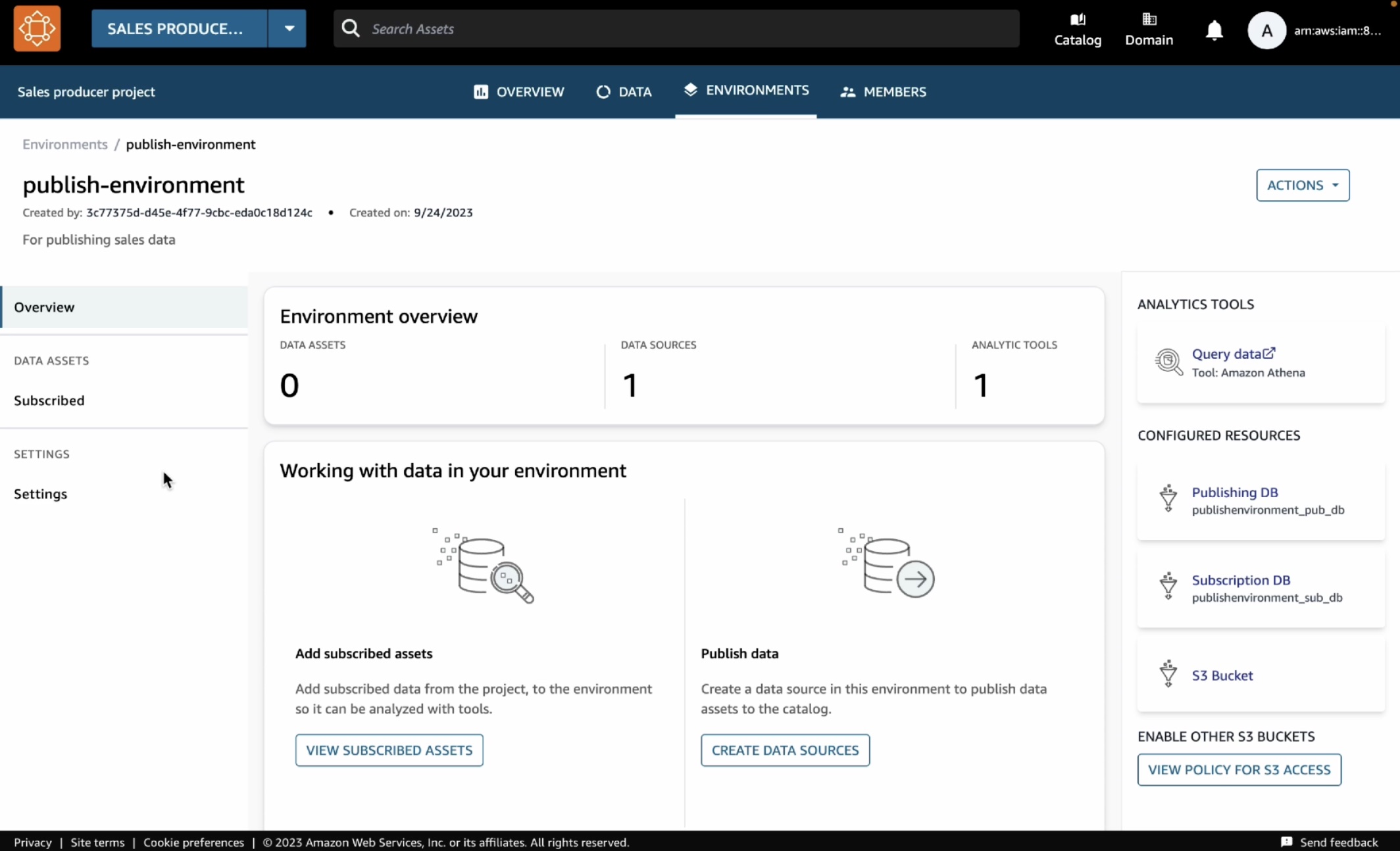
You have the environment to publish your data in your AWS Glue table. To create this table in Amazon Athena, choose Query data with the Athena link on the right-hand side of the Environments page.
This opens the Athena query editor in a new tab. Select publishenvironment_pub_db from the database dropdown and then paste the following query into the query editor. This will create a table called catalog_sales in the environment’s AWS Glue database.
CREATE TABLE catalog_sales AS
SELECT 146776932 AS order_number, 23 AS quantity, 23.4 AS wholesale_cost, 45.0 as list_price, 43.0 as sales_price, 2.0 as discount, 12 as ship_mode_sk,13 as warehouse_sk, 23 as item_sk, 34 as catalog_page_sk, 232 as ship_customer_sk, 4556 as bill_customer_sk
UNION ALL SELECT 46776931, 24, 24.4, 46, 44, 1, 14, 15, 24, 35, 222, 4551
UNION ALL SELECT 46777394, 42, 43.4, 60, 50, 10, 30, 20, 27, 43, 241, 4565
UNION ALL SELECT 46777831, 33, 40.4, 51, 46, 15, 16, 26, 33, 40, 234, 4563
UNION ALL SELECT 46779160, 29, 26.4, 50, 61, 8, 31, 15, 36, 40, 242, 4562
UNION ALL SELECT 46778595, 43, 28.4, 49, 47, 7, 28, 22, 27, 43, 224, 4555
UNION ALL SELECT 46779482, 34, 33.4, 64, 44, 10, 17, 27, 43, 52, 222, 4556
UNION ALL SELECT 46779650, 39, 37.4, 51, 62, 13, 31, 25, 31, 52, 224, 4551
UNION ALL SELECT 46780524, 33, 40.4, 60, 53, 18, 32, 31, 31, 39, 232, 4563
UNION ALL SELECT 46780634, 39, 35.4, 46, 44, 16, 33, 19, 31, 52, 242, 4557
UNION ALL SELECT 46781887, 24, 30.4, 54, 62, 13, 18, 29, 24, 52, 223, 4561You can see the two databases in the dropdown menu. The publishenvironment_pub_db is to provide you with a space to produce new data and choose to publish it to the DataZone catalog. The other one, publishenvironment_sub_db is for project members when they subscribe to or access to data in the catalog within that project.
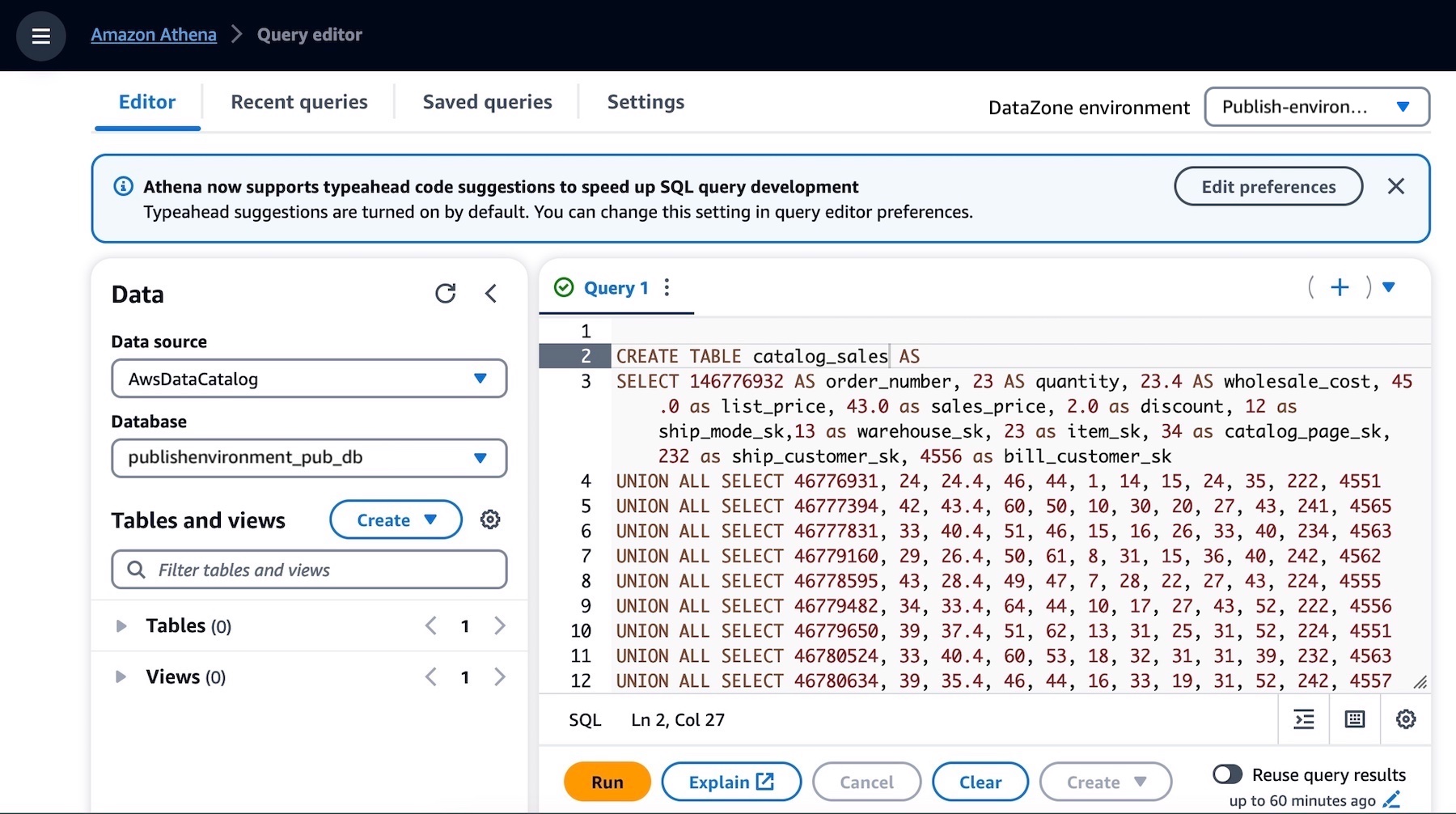
Make sure that the catalog_sales table is successfully created. Now you have a data asset that can be published into the Amazon DataZone catalog.
As the data producer, you can now go back to the data portal and publish this table into the DataZone catalog. Choose the Data tab in the top menu and Data sources in the left navigation pane.
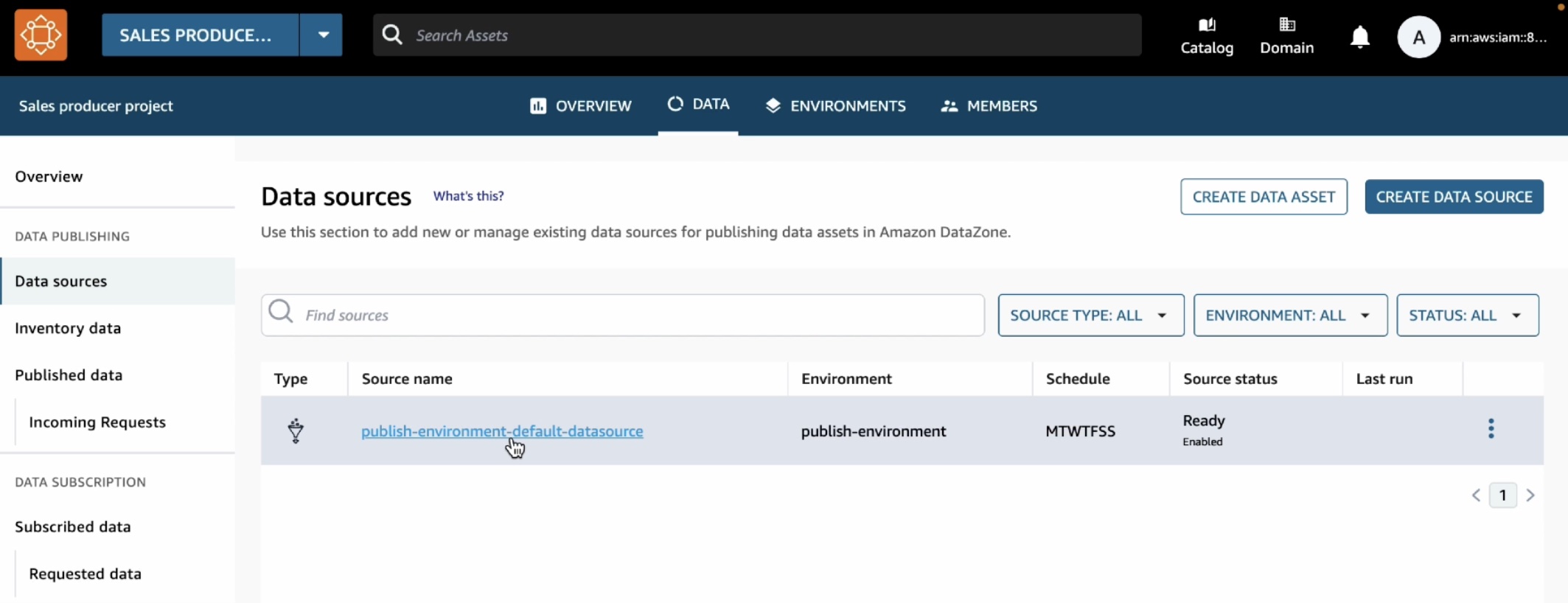
You can see a default data source automatically created in your environment. When you open this data source, you will see your environments’ publishing database where we just created the catalog_sales table.
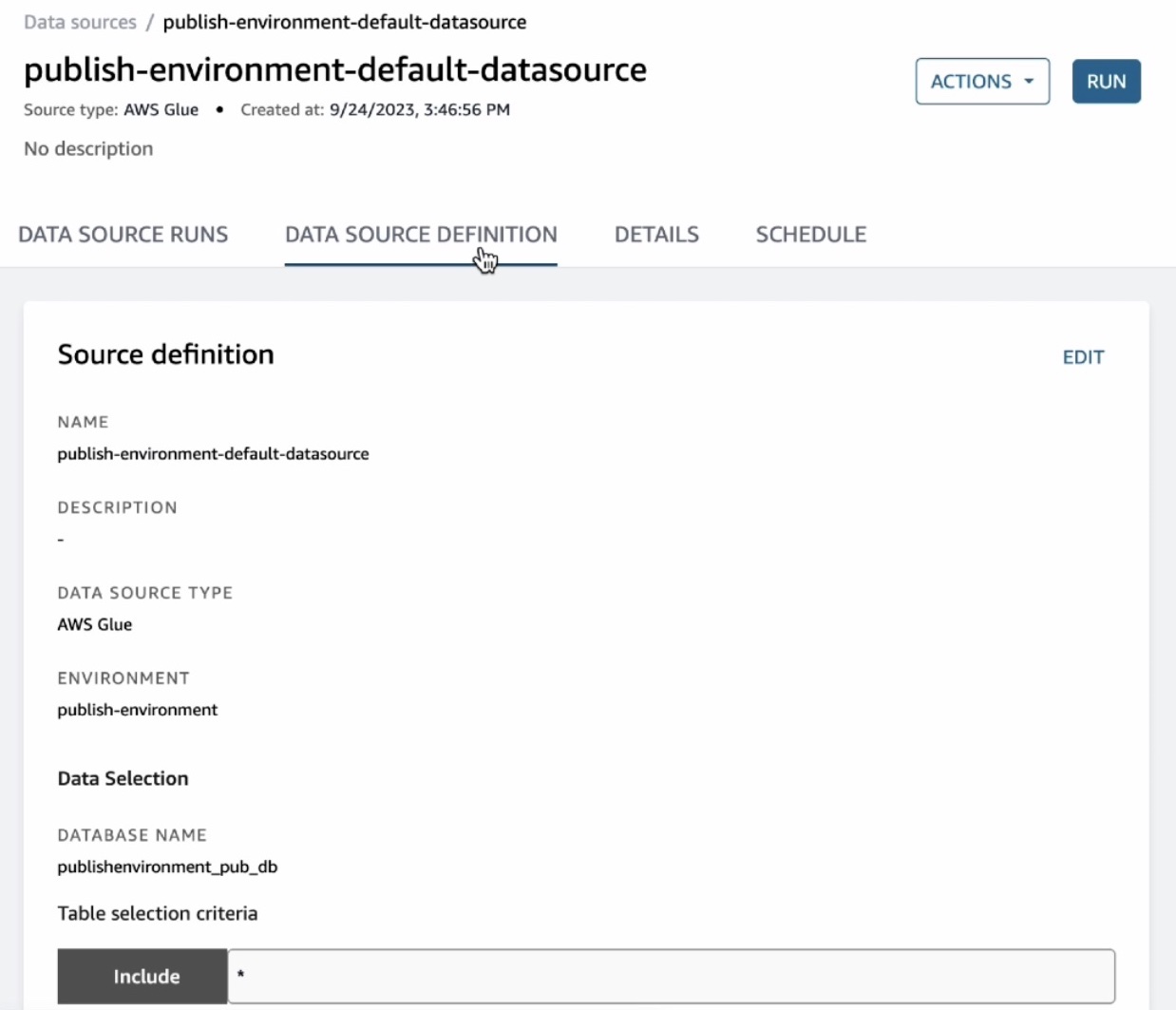
This data source will bring in all the tables it finds in the publishing database into the DataZone. By default, automated metadata generation is enabled, which means that any asset that the data source bring into the DataZone will automatically generate the business names of the table and columns for that asset. Choose Run in this data source.
Once the data source has finished running, you can see the catalog sales table in the Data Source Runs.
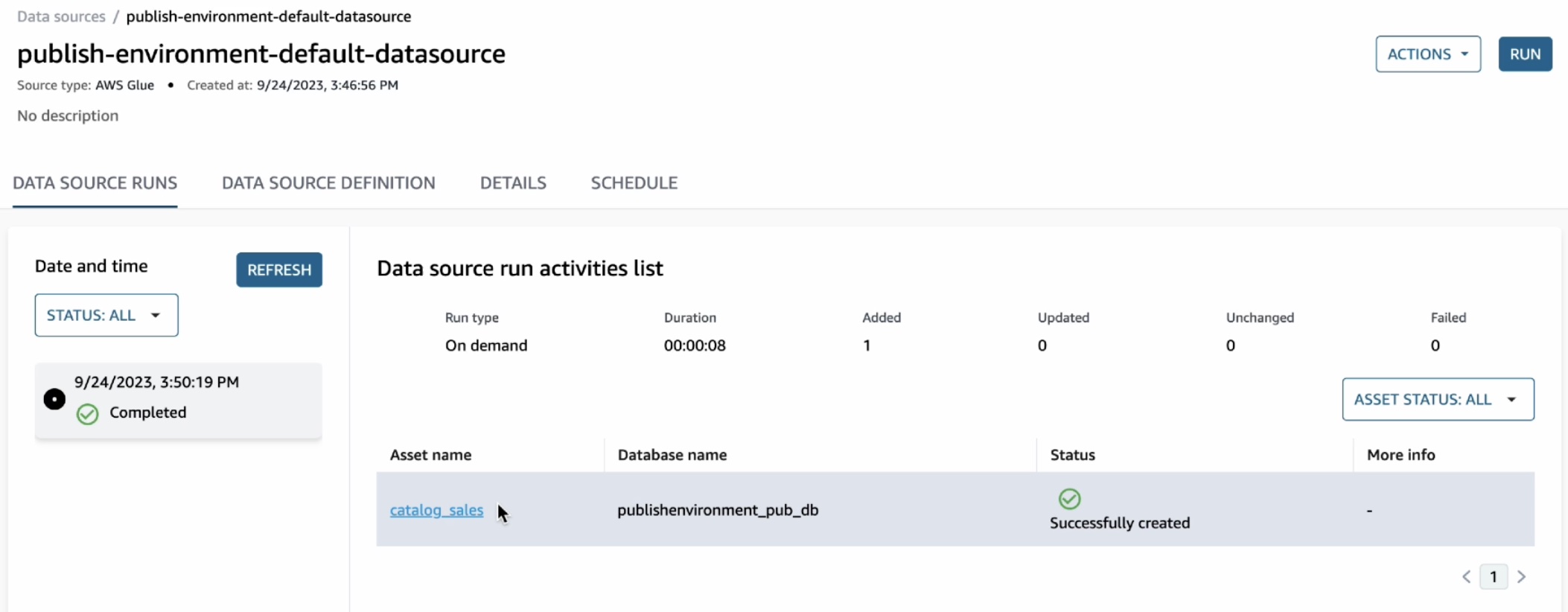
You can open this asset and see that the publishing job could automatically extract the technical metadata including the schema of the table and several other technical details such as AWS account, Region, and physical location of the data.
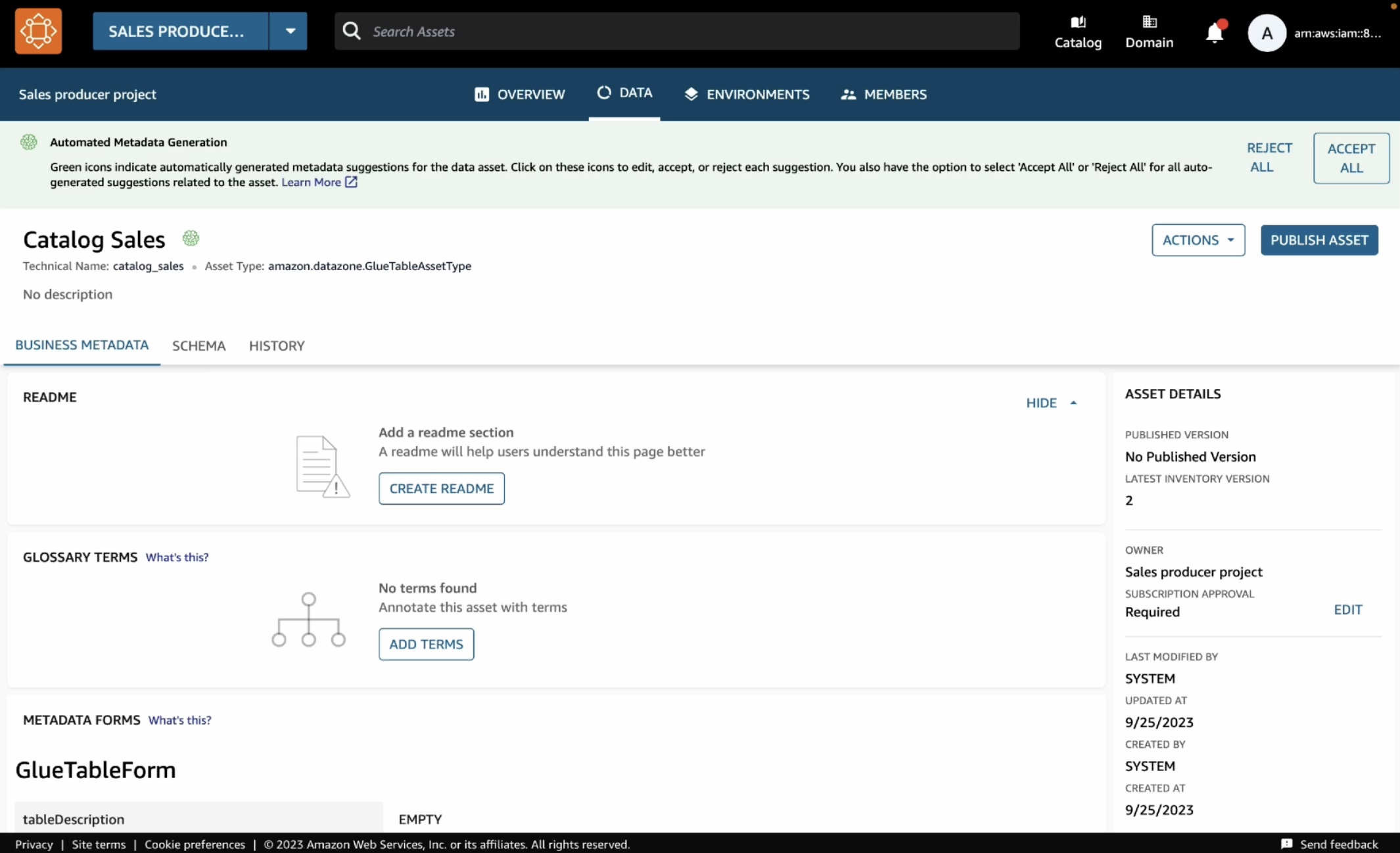
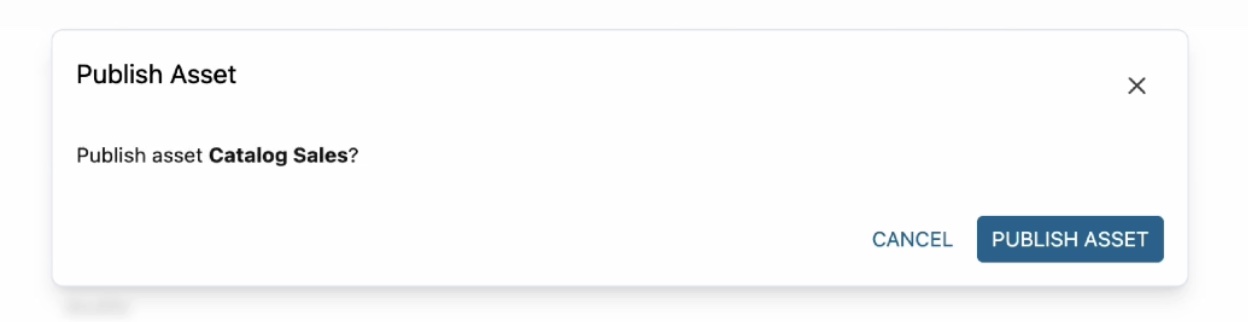
If they look correct, you can simply accept these recommendations either by clicking the brain icon in each recommended item or the Accept all button for all recommendations. When you are ready to publish, choose Publish asset and reconfirm in the dialog box.
4. Subscribe Data as a Data Consumer
Now let’s switch the role to a marketing team and see how you can subscribe to or request access this table. Repeat to create a new project called “Marketing consumer project” and a new environment called “subscriber-environment” as the data consumer using the same steps as before.
In the new created project, when you type “catalog sales” in the search bar, you can see the published table in the search results. Choose the Catalog Sales Data.
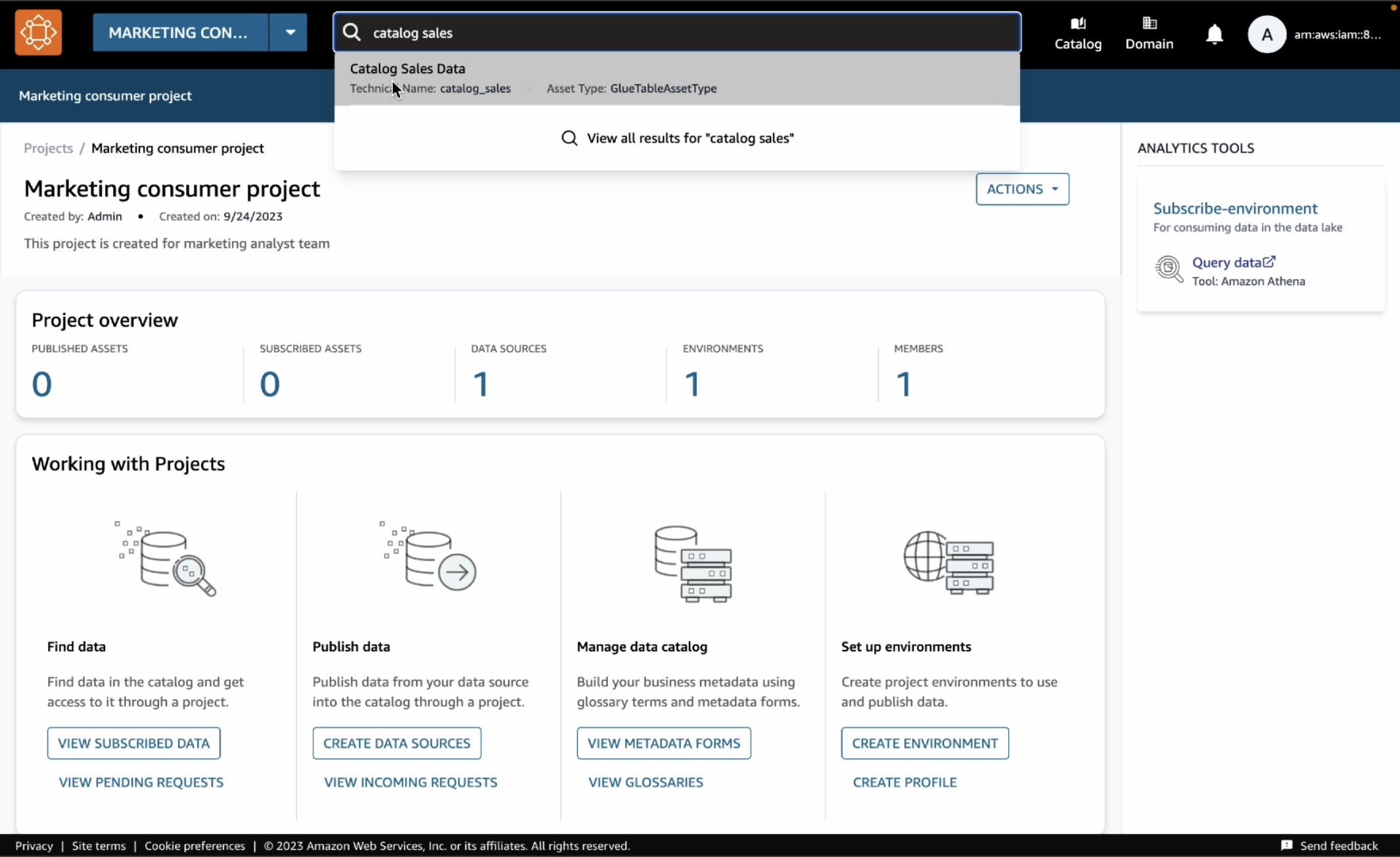
In the catalog, choose Subscribe.
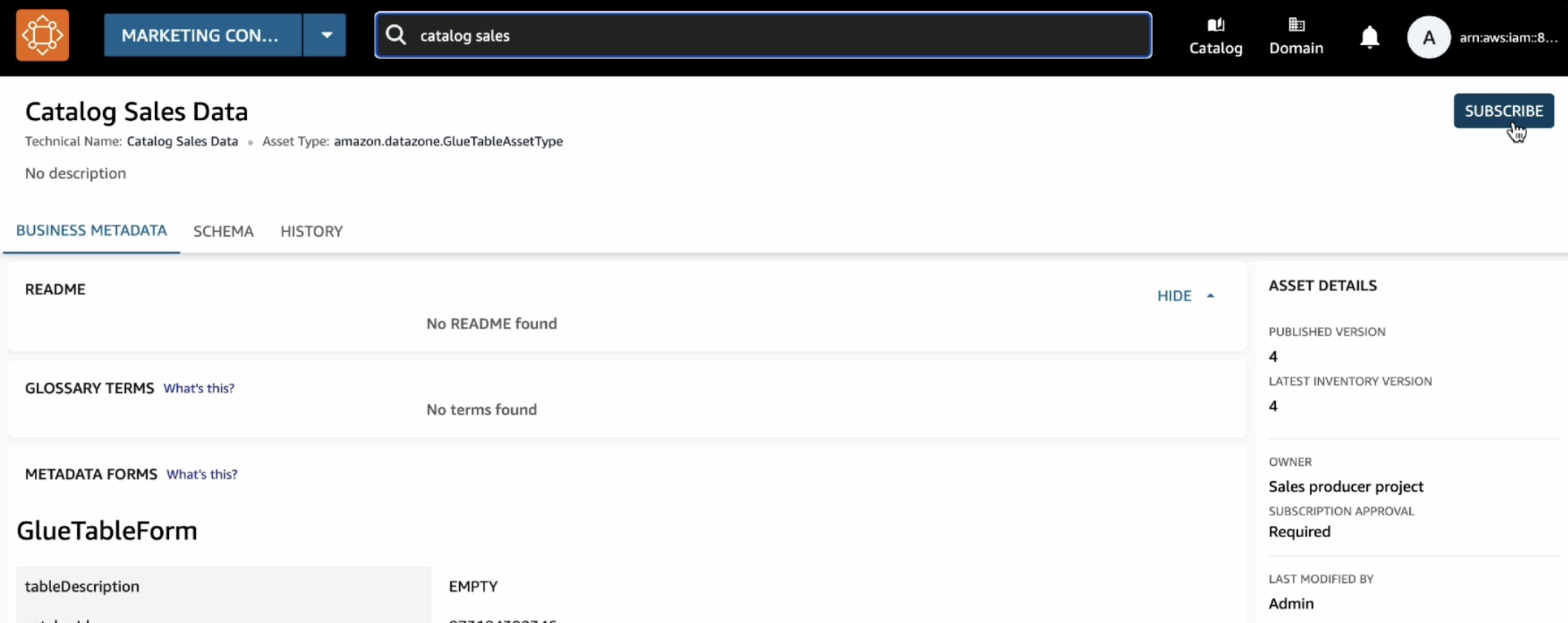
In the Subscribe to Catalog Sales Data window, select your marketing consumer project, provide a reason for the subscription request, and then choose Subscribe.
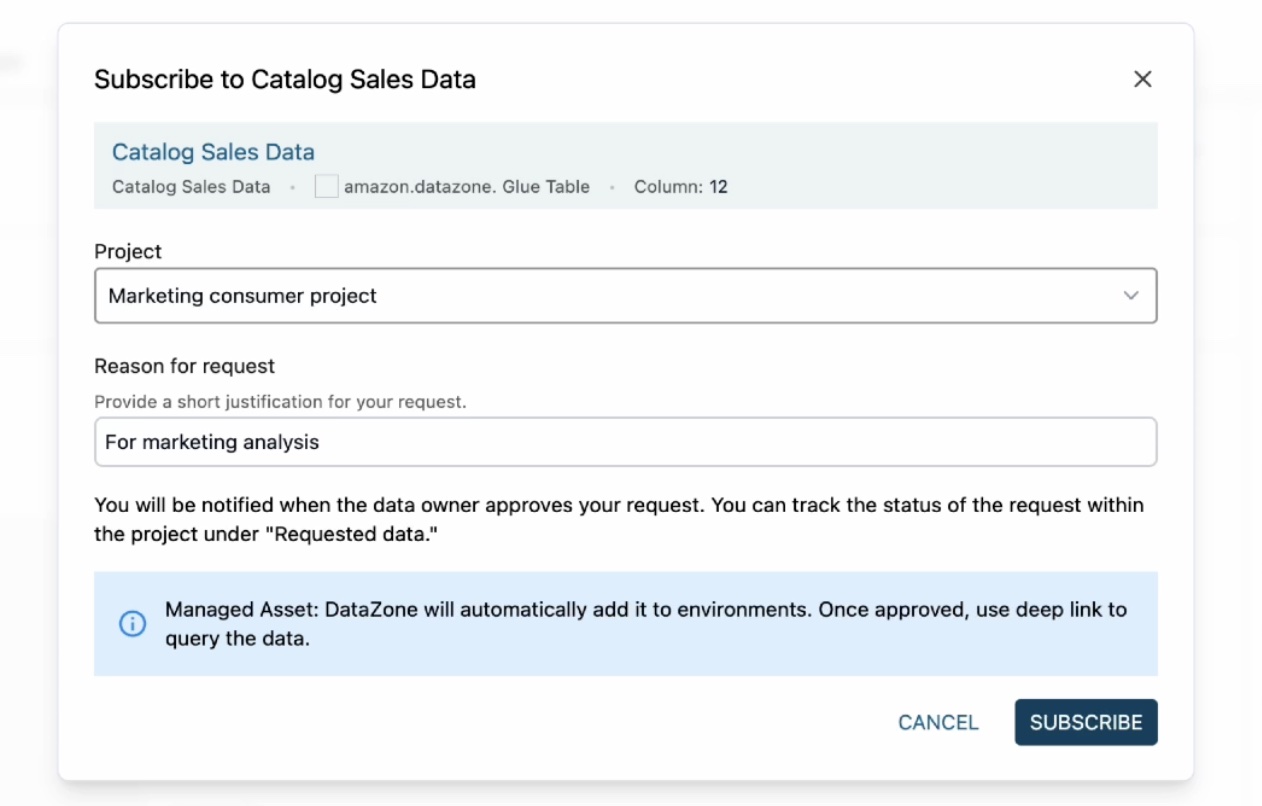
When you get a subscription request as a data producer, it will notify you through a task in the sales producer project. Since you are acting as both subscriber and publisher here, you will see a notification.
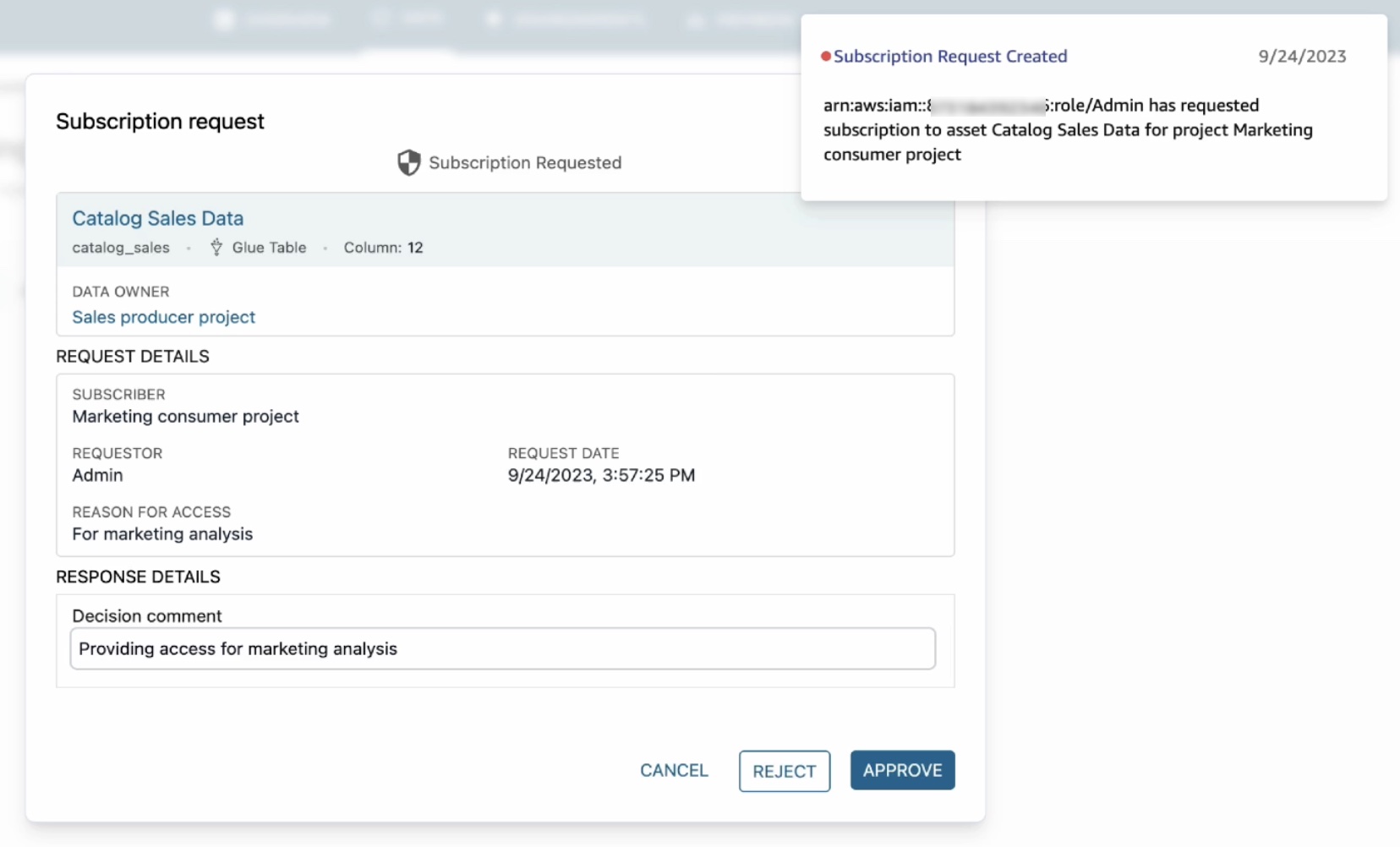
When you click on this notification, it will open the subscription request including which project has requested access, who the requestor is, and why they need access. Choose Approve and provide a reason for approval.
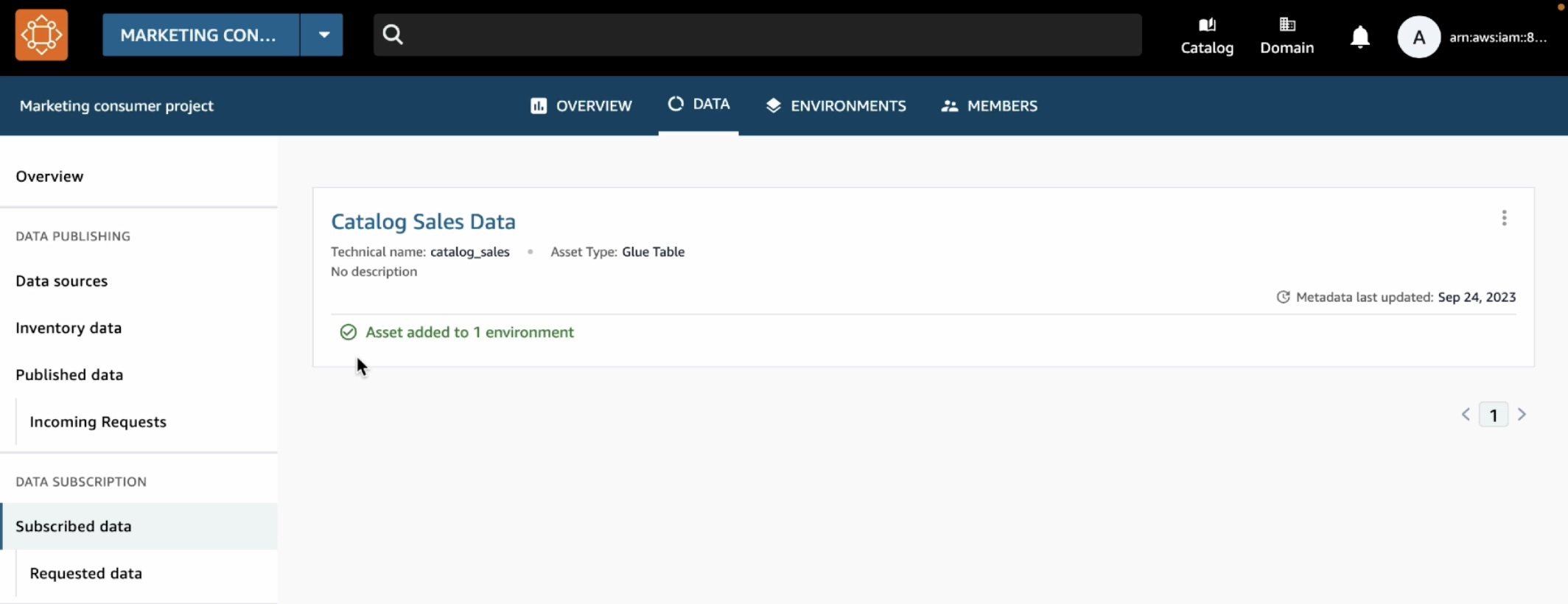
Now that subscription has been approved, you can see catalog sales data in your marketing consumer project. To confirm this, choose the Data tab in the top menu and Data sources in the left navigation pane.
To analyze your subscribe data, choose the Environments tab in the top menu and Subscribe-environment you created in the marketing consumer project. It shows a new Query Data link in the right pane.
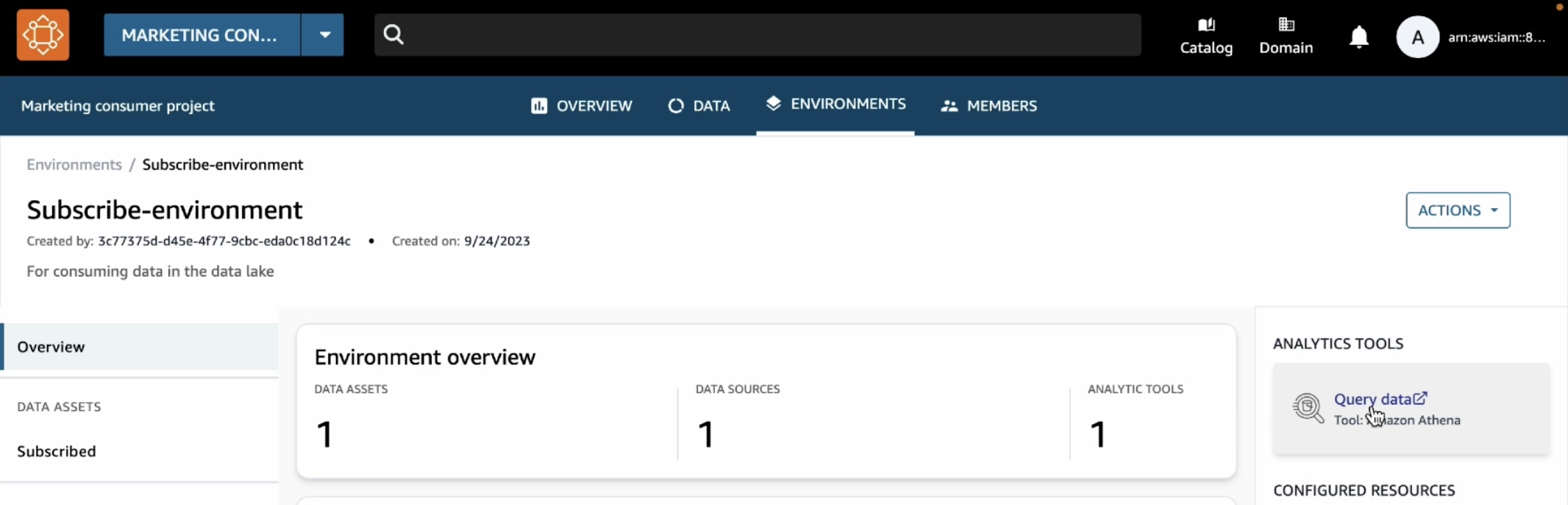
We can see that the catalog sales table is showing up under subscription database.
To make sure that we have access to this table, we can preview it and we can see that the query executes successfully.
This opens the Athena query editor in a new tab. Select subscribeenvironment_sub_db from the database dropdown, and then enter your query into the query editor.
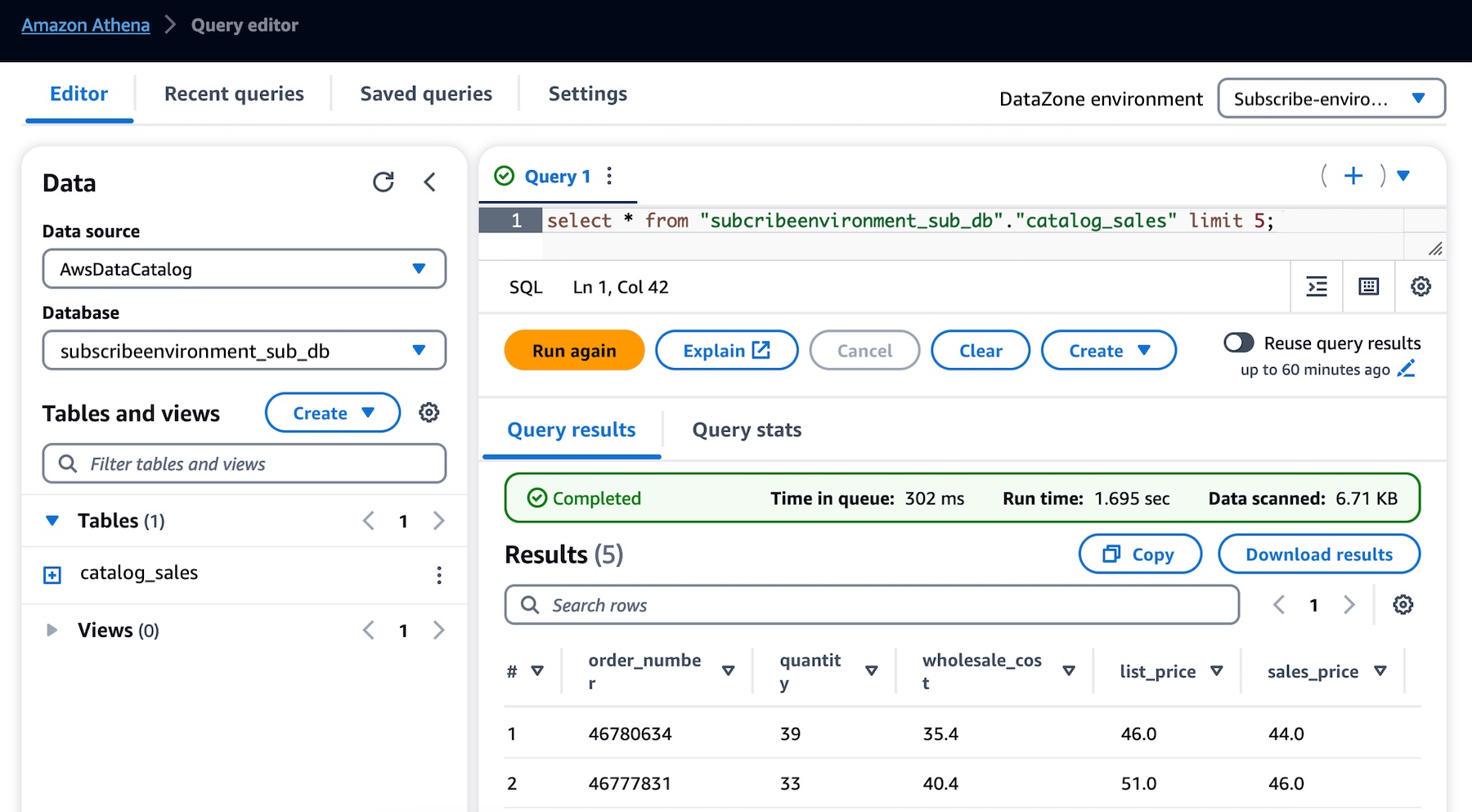
You can now run any queries on the sales data table that you have subscribed to as a consumer (marketing team) and that was published into the business data catalog by a producer (sales team).
For more detailed demos such as publishing AWS Glue tables and Amazon Redshift tables and view, see the YouTube playlist.
What’s New at GA?
During the preview, we had lots of interest and great feedback from customers. I want to quickly review the features and introduce some improvements:
Enterprise-Ready Business Catalog – To add business context and make data discoverable by everyone in the organization, you can customize the catalog with automated metadata generation which uses machine learning to automatically generate business names of data assets and columns within those assets. We also improved metadata curation functionality. At GA, you can attach multiple business glossary terms to assets and glossary terms to individual columns in the asset.
Self-Service for Data Users – To provide data autonomy for users to publish and consume data, you can customize and bring any type of asset to the catalog using APIs. Data publishers can automate metadata discovery through ingestion jobs or manually publish files from Amazon Simple Storage Service (Amazon S3). Data consumers can use faceted search to quickly find and understand the data. Users can be notified of updates in the system or actions to be taken. These events are emitted to the customer’s event bus using Amazon EventBridge to customize actions.
Simplified Access to analysis – At GA, projects will serve as business use case-based logical containers. You can create a project and collaborate on specific business use case-based groupings of people, data, and analytics tools. Within the project, you can create an environment that provides the necessary infrastructure to project members such as analytics tools and storage so that project members can easily produce new data or consume data they have access to. This allows users to add multiple capabilities and analytics tools to the same project depending on their needs.
Governed Data Sharing – Data producers own and manage access to data with a subscription approval workflow that allows consumers to request access and data owners to approve. You can now set up subscription terms to be attached to assets when published and automate subscription grant fulfillment for AWS managed data lakes and Amazon Redshift with customizations using EventBridge events for other sources.
Now Available
Amazon DataZone is now generally available in eleven AWS Regions: US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Canada (Central), Europe (Frankfurt), Europe (Ireland), Europe (Stockholm), and South America (São Paulo).
You can use the free trial of Amazon DataZone, which includes 50 users at no additional cost for the first 3 calendar months of usage. The free trial starts when you first create an Amazon DataZone domain in an AWS account. If you exceed the number of monthly users during your trial, you will be charged at the standard pricing.
To learn more, visit the product page and user guide. You can send feedback to AWS re:Post for Amazon DataZone or through your usual AWS Support contacts.
— Channy
Source: AWS News