OpsCenter – A New Feature to Streamline IT Operations
The AWS teams are always listening to customers and trying to understand how they can improve services to make customers more productive. A new feature in AWS Systems Manager called OpsCenter exemplifies this approach by enabling customers to aggregate issues, events and alerts, across services. So customers can go to one place to view, investigate, and remediate issues reducing the need to navigate across multiple different AWS services.
Issues, events and alerts appear as operations items (OpsItems) in this new console and provide contextual information, historical guidance, and quick solution steps. The feature aims to improve the mean time to resolution, making engineers more productive by ensuring key investigation data is available in one place.
Engineers working on an OpsItem get access to information such as:
- Event, resource and account details
- Past OpsItems with similar characteristics
- Related AWS Config changes and relationships
- AWS CloudTrail logs
- Amazon CloudWatch alarms
- AWS CloudFormation Stack information
- Other quick-links to access logs and metrics
- List of runbooks and recommended runbooks
- Additional information passed to OpsCenter through AWS services
This information helps engineers to investigate and remediate operational issues faster. Engineers can use OpsCenter to view and address problems using the Systems Manager console or via the Systems Manager OpsCenter APIs.
I’ll spend the rest of this blog exploring the capabilities of this new feature. To get started, I open the Systems Manager Console, make sure that I am in the region of interest, and click OpsCenter inside the Operations Management menu which is on the far left of the screen.
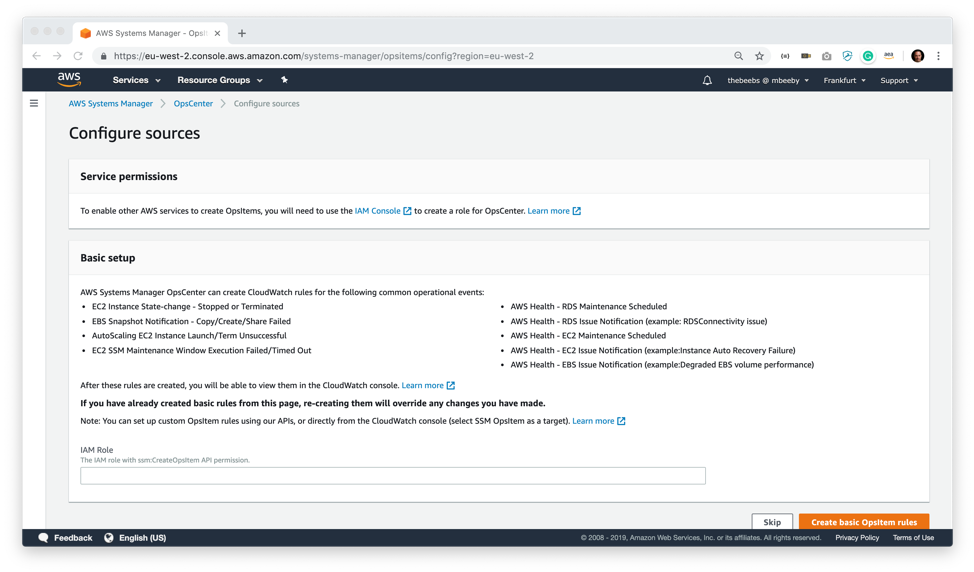
After arriving at the OpsCenter screen for the first time and clicking on “Getting Started” I am prompted with a configure sources screen. This screen sets up the systems with some example CloudWatch rules that will create OpsItems when specific rules trigger. For example, one of the CloudWatch rules will alert if an AutoScaling EC2 instance is stopped or terminated. On this screen, you need to configure and add the ARN of an IAM role that has permission to create OpsItems. This security role is used by the CloudWatch rules to create the OpsItems. You can, of course, create your OpsItems through the API or by creating custom CloudWatch rules.
Now the system has set me up some CloudWatch rules I thought I would test it out by triggering an alert. In the EC2 console, I will intentionally deregister (delete) the Amazon Machine Image that is associated with my AutoScaling Group. I will then increase the Desired Capacity of my AutoScaling group from 2 to 4. The AutoScaling group will later try to create new instances; however, it will fail because I have deleted the AMI.

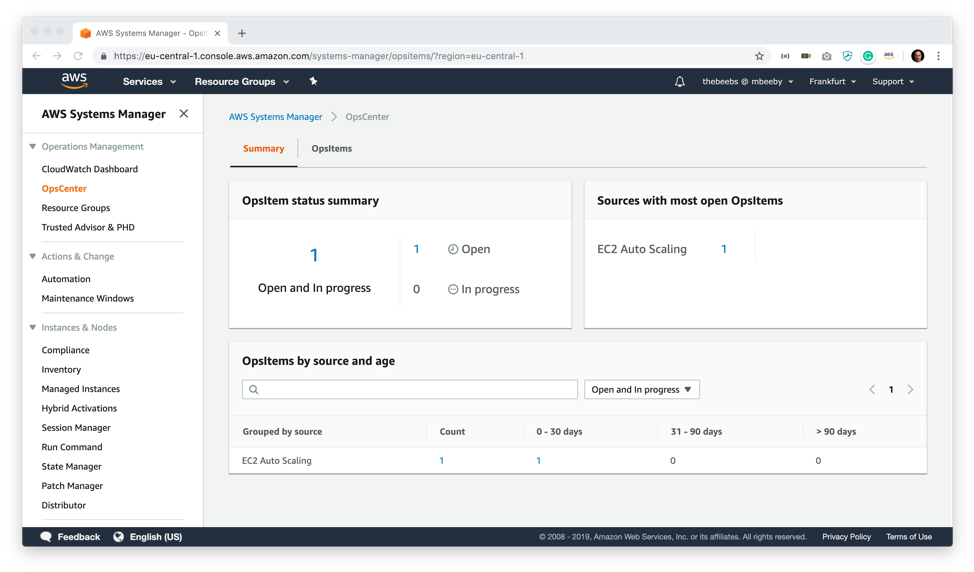
As I expected this triggered the CloudWatch rule to create an OpsItem in OpsCenter console. There is now one item open in the OpsItem status summary dashboard. I click on this to get more detail on the open OpsItems.
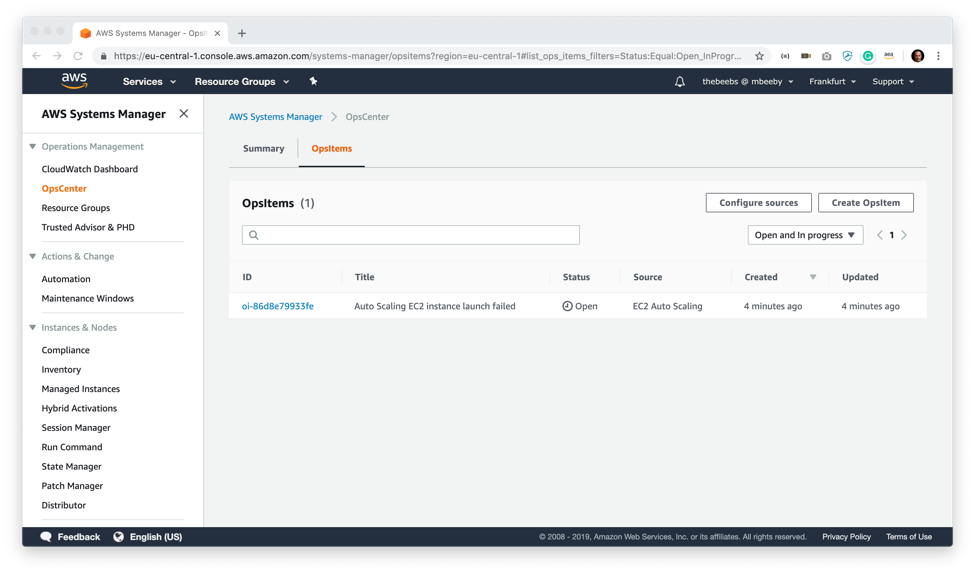
This gives me a list of all the open OpsItems, and I can see that I have one with the title “Auto Scaling EC2 instance launch failed” which has been created by CloudWatch rules because I deleted the AMI associated with the AutoScaling group. Clicking on that OpsItems takes me to more detail of the OpsItem.
I can from this overview screen start to explore the item. Looking around this screen, I can find out more information about this OpsItem and see it is collecting data from numerous services and presenting it in one place.
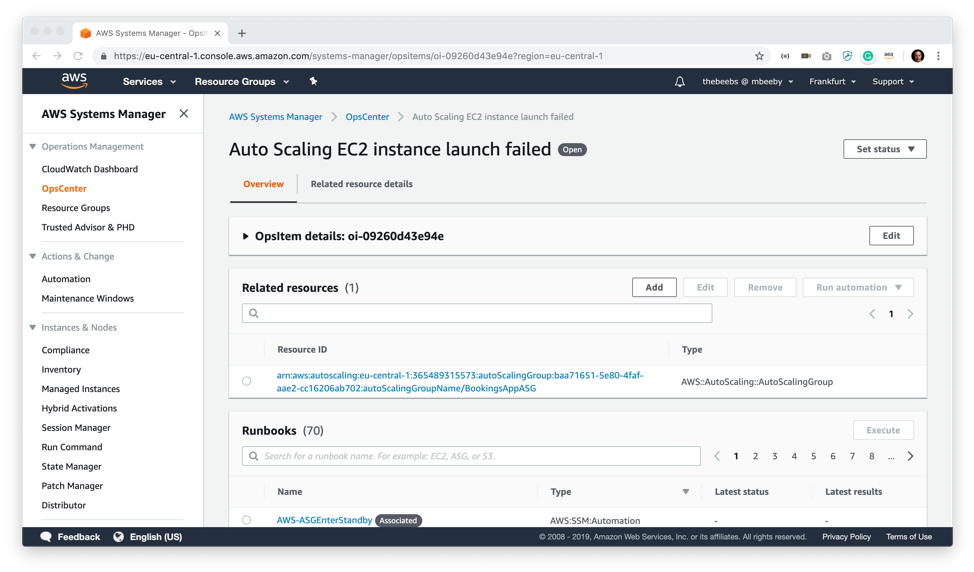
Further down the screen I can see other Similar OpsItems and can explore them. In a real situation, this might give me contextual information as to how similar problems were solved in the past, ensuring that operations teams learn from their previous collective experience. I can also manually add a relationship between OpsItems if they are connected. Importantly the Operational data section gives me information about the cause. The status message is particularly useful since it’s calling out the issue: that the AMI does not exist.
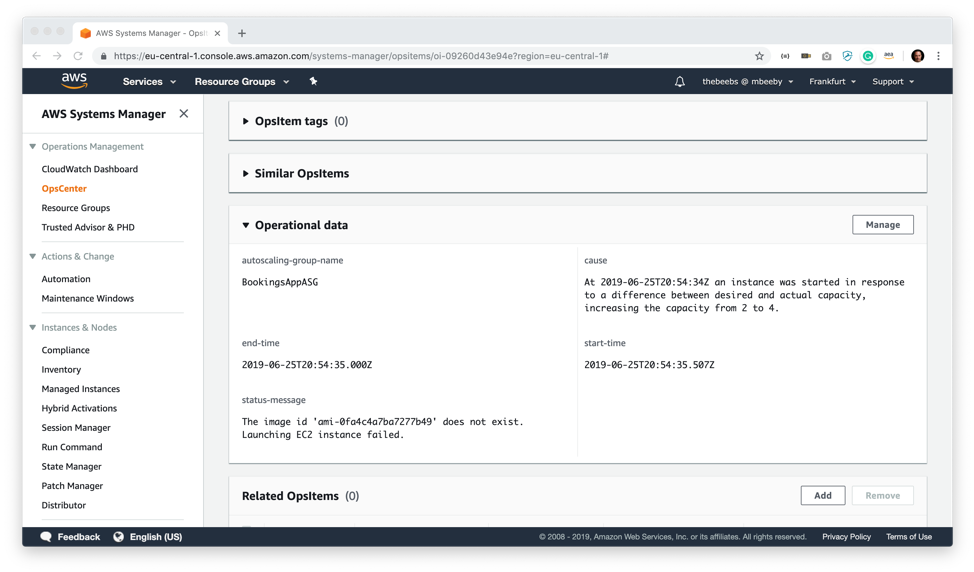
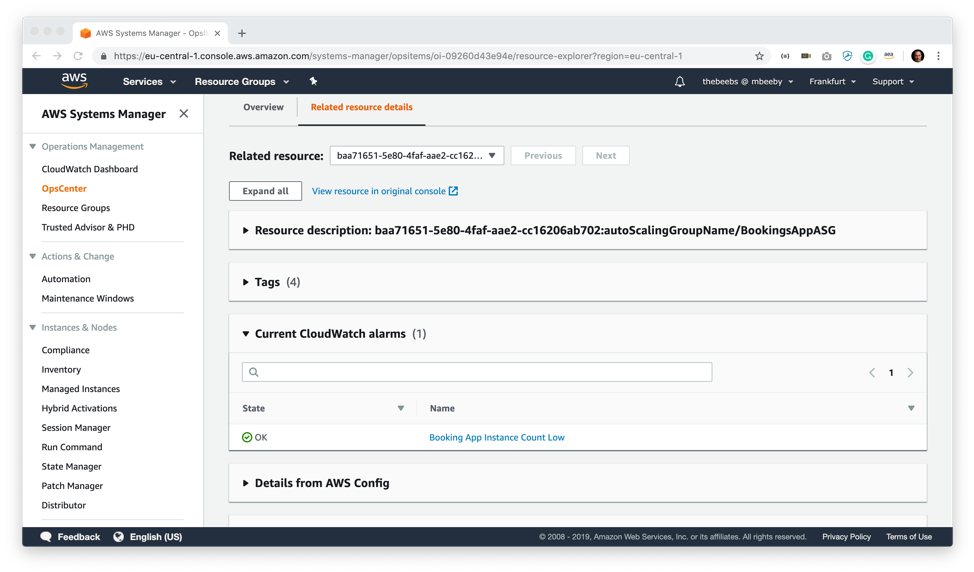
On the related resources details screen, I can find out more information about this OpsItem. For example, I can see tag information about the resources alongside relevant CloudWatch alarms. I can explore details from AWS config as well as drill into CloudTrail logs. I can even see if the resources are associated with any CloudFormation stacks.
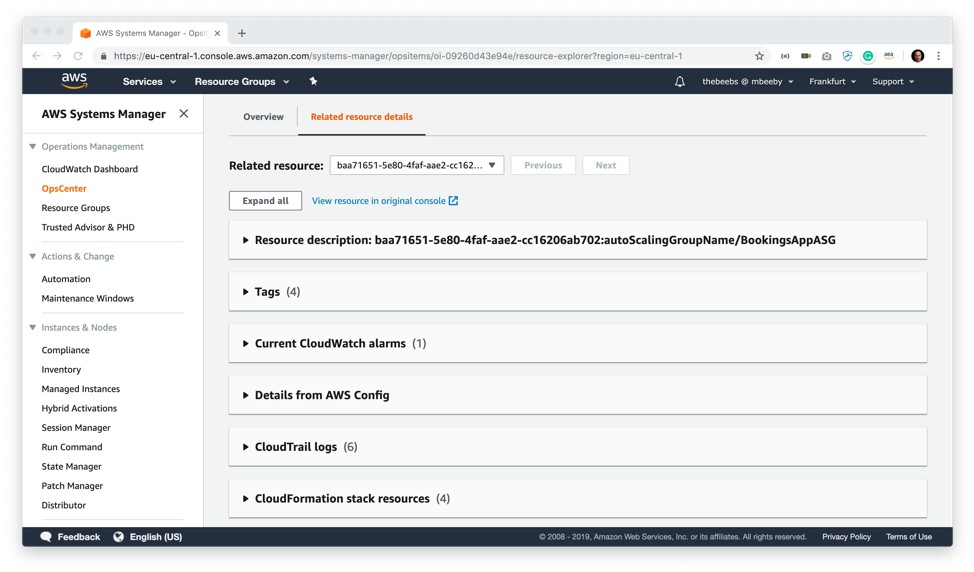
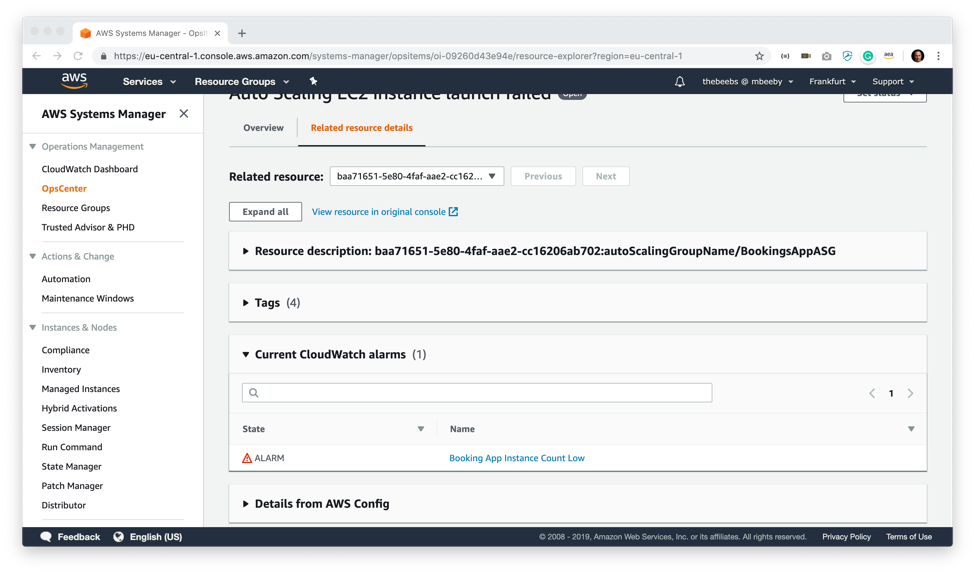
Earlier on, I created a CloudWatch alarm that will alert when the number of instances on my AutoScaling group falls below the desired instance threshold (4 Instances). As you can see, I don’t need to go into the CloudWatch console to view this, I can see right from this screen that I have an Alarm State for Booking App Instance Count Low.
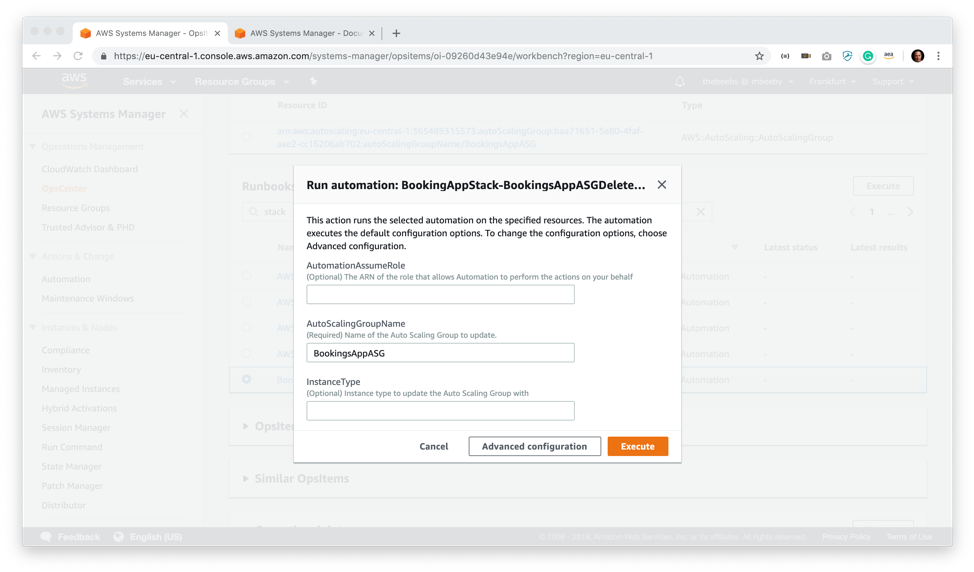
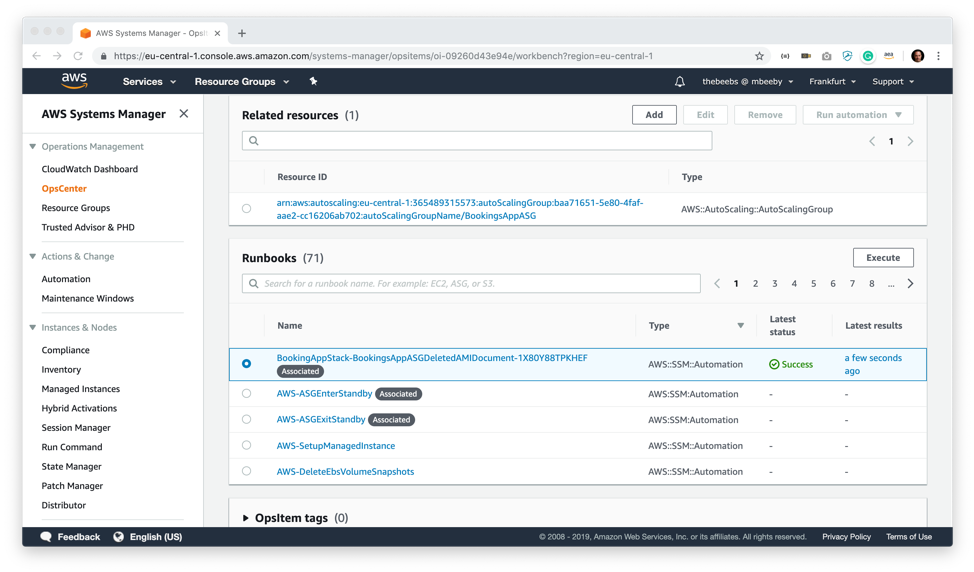
The Runbooks section is fascinating; what it is offering me is automated ways in which I can resolve this issue. There are several built-in Runbooks; however, I have a custom one which, luckily enough, automates the fix for this exact problem. It will create a new AMI based upon one of the healthy instances in my AutoScaling Group and then update the config to use that new AMI when it creates instances. To run this automation, I select the runbook and press execute.

It asks me to provide some parameters for the automation job. I paste the AutoScaling Group Name (BookingsAppASG) as the only required parameter and press Execute.
After a minute or so a green success signifier appears in the Latest Status column of the runbook and I am now able to view the logs and even save the output to operation data on the OpsItem so that other engineers can clearly see what I have done.
Back in the OpsCenter OpsItem related resource details screen, I can now see that my CloudWatch alarm is green and in an OK state, signifying that my AutoScalling group currently has four instances running and I am safe to resolve the OpsItem.
This service is available now, and you can start using it today in all public AWS regions so why not open up the console and start exploring all the ways that you can save you and your team valuable time.



Source: AWS News