Introducing Amazon MemoryDB for Redis – A Redis-Compatible, Durable, In-Memory Database Service
Interactive applications need to process requests and respond very quickly, and this requirement extends to all the components of their architecture. That is even more important when you adopt microservices and your architecture is composed of many small independent services that communicate with each other.
For this reason, database performance is critical to the success of applications. To reduce read latency to microseconds, you can put an in-memory cache in front of a durable database. For caching, many developers use Redis, an open-source in-memory data structure store. In fact, according to Stack Overflow’s 2021 Developer Survey, Redis has been the most loved database for five years.
To implement this setup on AWS, you can use Amazon ElastiCache for Redis, a fully managed in-memory caching service, as a low latency cache in front of a durable database service such as Amazon Aurora or Amazon DynamoDB to minimize data loss. However, this setup requires you to introduce custom code in your applications to keep the cache in sync with the database. You’ll also incur costs for running both a cache and a database.
Introducing Amazon MemoryDB for Redis
Today, I am excited to announce the general availability of Amazon MemoryDB for Redis, a new Redis-compatible, durable, in-memory database. MemoryDB makes it easy and cost-effective to build applications that require microsecond read and single-digit millisecond write performance with data durability and high availability.
Instead of using a low-latency cache in front of a durable database, you can now simplify your architecture and use MemoryDB as a single, primary database. With MemoryDB, all your data is stored in memory, enabling low latency and high throughput data access. MemoryDB uses a distributed transactional log that stores data across multiple Availability Zones (AZs) to enable fast failover, database recovery, and node restarts with high durability.
MemoryDB maintains compatibility with open-source Redis and supports the same set of Redis data types, parameters, and commands that you are familiar with. This means that the code, applications, drivers, and tools you already use today with open-source Redis can be used with MemoryDB. As a developer, you get immediate access to many data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes, and streams. You also get access to advanced features such as built-in replication, least recently used (LRU) eviction, transactions, and automatic partitioning. MemoryDB is compatible with Redis 6.2 and will support newer versions as they are released in open source.
One question you might have at this point is how MemoryDB compares to ElastiCache because both services give access to Redis data structures and API:
- MemoryDB can safely be the primary database for your applications because it provides data durability and microsecond read and single-digit millisecond write latencies. With MemoryDB, you don’t need to add a cache in front of the database to achieve the low latency you need for your interactive applications and microservices architectures.
- On the other hand, ElastiCache provides microsecond latencies for both reads and writes. It is ideal for caching workloads where you want to accelerate data access from your existing databases. ElastiCache can also be used as a primary datastore for use cases where data loss might be acceptable (for example, because you can quickly rebuild the database from another source).
Creating an Amazon MemoryDB Cluster
In the MemoryDB console, I follow the link on the left navigation pane to the Clusters section and choose Create cluster. This opens Cluster settings where I enter a name and a description for the cluster.

All MemoryDB clusters run in a virtual private cloud (VPC). In Subnet groups I create a subnet group by selecting one of my VPCs and providing a list of subnets that the cluster will use to distribute its nodes.

In Cluster settings, I can change the network port, the parameter group that controls the runtime properties of my nodes and clusters, the node type, the number of shards, and the number of replicas per shard. Data stored in the cluster is partitioned across shards. The number of shards and the number of replicas per shard determine the number of nodes in my cluster. Considering that for each shard there is a primary node plus the replicas, I expect this cluster to have eight nodes.
For Redis version compatibility, I choose 6.2. I leave all other options to their default and choose Next.

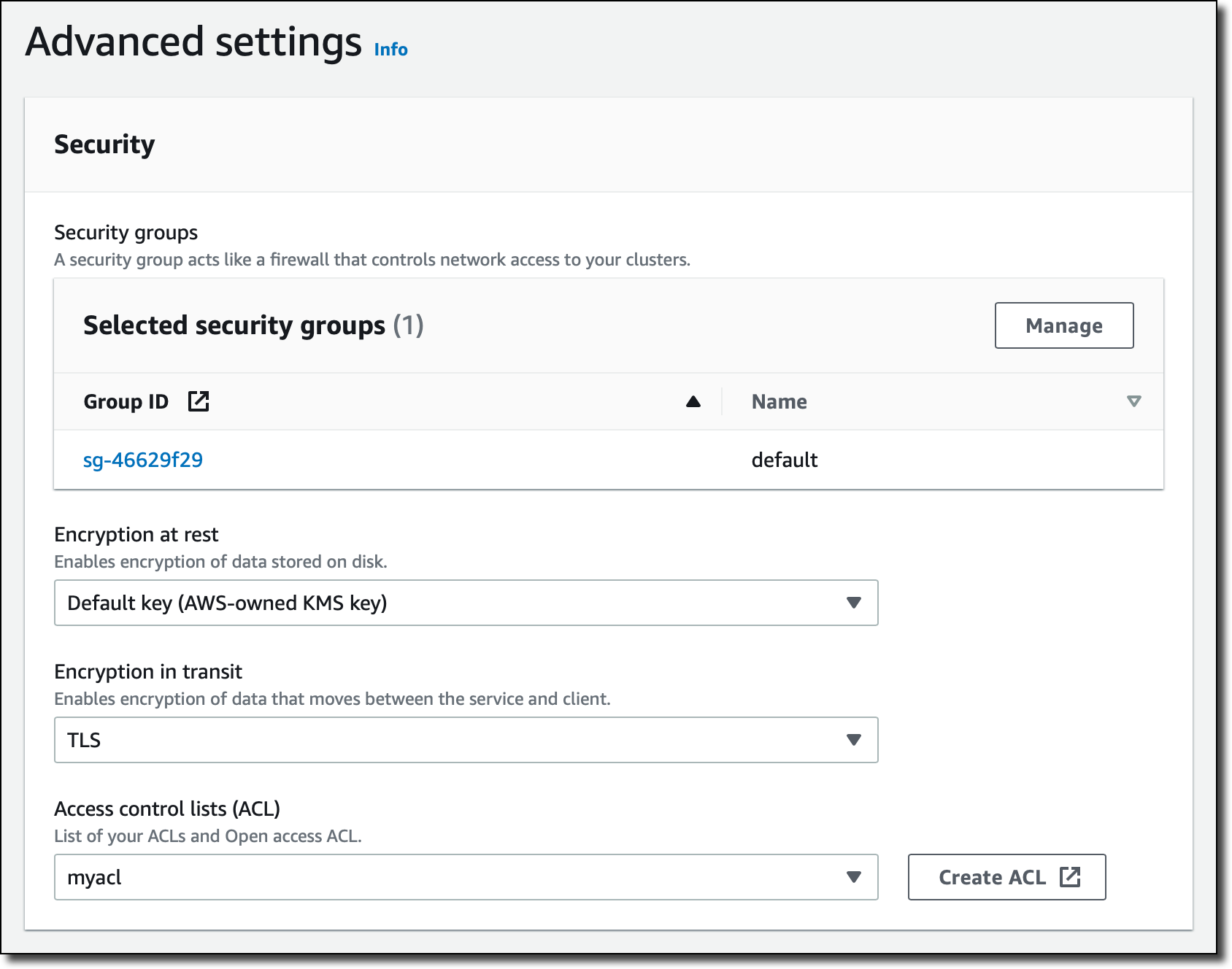
In the Security section of Advanced settings I add the default security group for the VPC I used for the subnet group and choose an access control list (ACL) that I created before. MemoryDB ACLs are based on Redis ACLs and provide user credentials and permissions to connect to the cluster.
In the Snapshot section, I leave the default to have MemoryDB automatically create a daily snapshot and select a retention period of 7 days.

For Maintenance, I leave the defaults and then choose Create. In this section I can also provide an Amazon Simple Notification Service (SNS) topic to be notified of important cluster events.
After a few minutes, the cluster is running and I can connect using the Redis command line interface or any Redis client.
Using Amazon MemoryDB as Your Primary Database
Managing customer data is a critical component of many business processes. To test the durability of my new Amazon MemoryDB cluster, I want to use it as a customer database. For simplicity, let’s build a simple microservice in Python that allows me to create, update, delete, and get one or all customer data from a Redis cluster using a REST API.
Here’s the code of my server.py implementation:
from flask import Flask, request
from flask_restful import Resource, Api, abort
from rediscluster import RedisCluster
import logging
import os
import uuid
host = os.environ['HOST']
port = os.environ['PORT']
db_host = os.environ['DBHOST']
db_port = os.environ['DBPORT']
db_username = os.environ['DBUSERNAME']
db_password = os.environ['DBPASSWORD']
logging.basicConfig(level=logging.INFO)
redis = RedisCluster(startup_nodes=[{"host": db_host, "port": db_port}],
decode_responses=True, skip_full_coverage_check=True,
ssl=True, username=db_username, password=db_password)
if redis.ping():
logging.info("Connected to Redis")
app = Flask(__name__)
api = Api(app)
class Customers(Resource):
def get(self):
key_mask = "customer:*"
customers = []
for key in redis.scan_iter(key_mask):
customer_id = key.split(':')[1]
customer = redis.hgetall(key)
customer['id'] = customer_id
customers.append(customer)
print(customer)
return customers
def post(self):
print(request.json)
customer_id = str(uuid.uuid4())
key = "customer:" + customer_id
redis.hset(key, mapping=request.json)
customer = request.json
customer['id'] = customer_id
return customer, 201
class Customers_ID(Resource):
def get(self, customer_id):
key = "customer:" + customer_id
customer = redis.hgetall(key)
print(customer)
if customer:
customer['id'] = customer_id
return customer
else:
abort(404)
def put(self, customer_id):
print(request.json)
key = "customer:" + customer_id
redis.hset(key, mapping=request.json)
return '', 204
def delete(self, customer_id):
key = "customer:" + customer_id
redis.delete(key)
return '', 204
api.add_resource(Customers, '/customers')
api.add_resource(Customers_ID, '/customers/<customer_id>')
if __name__ == '__main__':
app.run(host=host, port=port)This is the requirements.txt file, which lists the Python modules required by the application:
The same code works with MemoryDB, ElastiCache, or any Redis Cluster database.
I start a Linux Amazon Elastic Compute Cloud (Amazon EC2) instance in the same VPC as the MemoryDB cluster. To be able to connect to the MemoryDB cluster, I assign the default security group. I also add another security group that gives me SSH access to the instance.
I copy the server.py and requirements.txt files onto the instance and then install the dependencies:
Now, I start the microservice:
In another terminal connection, I use curl to create a customer in my database with an HTTP POST on the /customers resource:
The result confirms that the data has been stored and a unique ID (a UUIDv4 generated by the Python code) has been added to the fields:
All the fields are stored in a Redis Hash with a key formed as customer:<id>.
I repeat the previous command a couple of times to create three customers. The customer data is the same, but each one has a unique ID.
Now, I get a list of all customer with an HTTP GET to the /customers resource:
In the code there is an iterator on the matching keys using the SCAN command. In the response, I see the data for the three customers:
One of the customers has just spent all his balance. I update the field with an HTTP PUT on the URL of the customer resource that includes the ID (/customers/<id>):
The code is updating the fields of the Redis Hash with the data of the request. In this case, it’s setting the balance to zero. I verify the update by getting the customer data by ID:
In the response, I see that the balance has been updated:
That’s the power of Redis! I was able to create the skeleton of a microservice with just a few lines of code. On top of that, MemoryDB gives me the durability and the high availability I need in production without the need to add another database in the backend.
Depending on my workload, I can scale my MemoryDB cluster horizontally, by adding or removing nodes, or vertically, by moving to larger or smaller node types. MemoryDB supports write scaling with sharding and read scaling by adding replicas. My cluster continues to stay online and support read and write operations during resizing operations.
Availability and Pricing
Amazon MemoryDB for Redis is available today in US East (N. Virginia), EU (Ireland), Asia Pacific (Mumbai), and South America (Sao Paulo) with more AWS Regions coming soon.
You can create a MemoryDB cluster in minutes using the AWS Management Console, AWS Command Line Interface (CLI), or AWS SDKs. AWS CloudFormation support will be coming soon. For the nodes, MemoryDB currently supports R6g Graviton2 instances.
To migrate from ElastiCache for Redis to MemoryDB, you can take a backup of your ElastiCache cluster and restore it to a MemoryDB cluster. You can also create a new cluster from a Redis Database Backup (RDB) file stored on Amazon Simple Storage Service (Amazon S3).
With MemoryDB, you pay for what you use based on on-demand instance hours per node, volume of data written to your cluster, and snapshot storage. For more information, see the MemoryDB pricing page.
Learn More
Check out the video below for a quick overview.
Start using Amazon MemoryDB for Redis as your primary database today.
— Danilo



Source: AWS News