NEW – Replicate Existing Objects with Amazon S3 Batch Replication
Starting today, you can replicate existing Amazon Simple Storage Service (Amazon S3) objects and synchronize your buckets using the new Amazon S3 Batch Replication feature.
Amazon S3 Replication supports several customer use cases. For example, you can use it to minimize latency by maintaining copies of your data in AWS Regions geographically closer to your users, to meet compliance and data sovereignty requirements, and to create additional resiliency for disaster recovery planning. S3 Replication is a fully managed, low-cost feature that replicates newly uploaded objects between buckets. The buckets can belong to the same or different accounts. Objects may be replicated to a single destination bucket or to multiple destination buckets. Destination buckets can be in different AWS Regions (Cross-Region Replication) or within the same Region as the source bucket (Same-Region Replication).

But until today, S3 Replication could not replicate existing objects; now you can do it with S3 Batch Replication.
There are many reasons why customers will want to replicate existing objects. For example, customers might want to copy their data to a new AWS Region for a disaster recovery setup. To do that, they will need to populate the new destination bucket with existing data. Another reason to copy existing data comes from organizations that are expanding around the world. For example, imagine a US-based animation company now opens a new studio in Singapore. To reduce latency for their employees, they will need to replicate all the internal files and in-progress media files to the Asia Pacific (Singapore) Region. One other common use case we see is customers going through mergers and acquisitions where they need to transfer ownership of existing data from one AWS account to another.
To replicate existing objects between buckets, customers end up creating complex processes. In addition, copying objects between buckets does not preserve the metadata of objects such as version ID and object creation time.
Today we are happy to launch S3 Batch Replication, a new capability offered through S3 Batch Operations that removes the need for customers to develop their own solutions for copying existing objects between buckets. It provides a simple way to replicate existing data from a source bucket to one or more destinations. With this capability, you can replicate any number of objects with a single job.
When to Use Amazon S3 Batch Replication
S3 Batch Replication can be used to:
- Replicate existing objects – use S3 Batch Replication to replicate objects that were added to the bucket before the replication rules were configured.
- Replicate objects that previously failed to replicate – retry replicating objects that failed to replicate previously with the S3 Replication rules due to insufficient permissions or other reasons.
- Replicate objects that were already replicated to another destination – you might need to store multiple copies of your data in separate AWS accounts or Regions. S3 Batch Replication can replicate objects that were already replicated to new destinations.
- Replicate replicas of objects that were created from a replication rule – S3 Replication creates replicas of objects in destination buckets. Replicas of objects cannot be replicated again with live replication. These replica objects can only be replicated with S3 Batch Replication.
Get started with S3 Batch Replication
There are many ways to get started with S3 Batch Replication from the S3 console. You can create a job from the Replication configuration page or the Batch Operations create job page. You will also get prompted to replicate existing objects when you create a new replication rule or add a new destination bucket.
For this demo, imagine that you are creating a replication rule in a bucket that has existing objects. When you finish creating the rule, you will get prompted with a message asking you if you want to replicate existing objects.

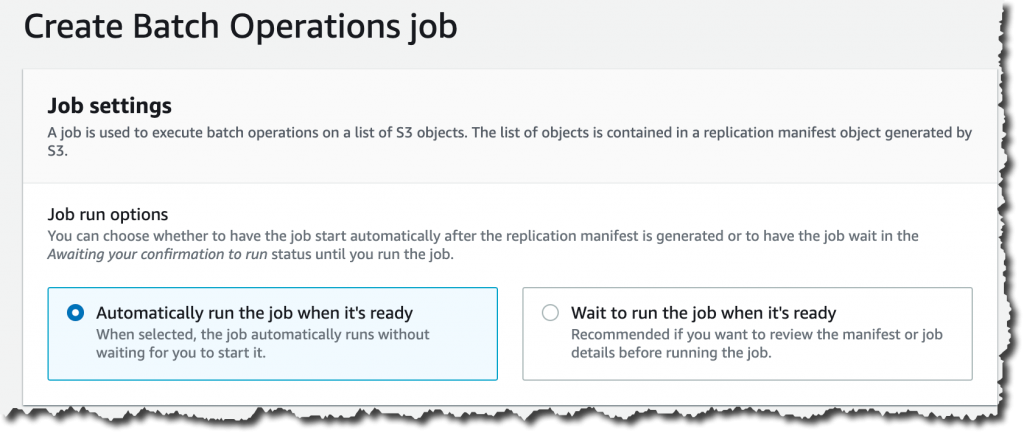
If you answer yes, then you will be directed to a simplified Create Batch Operations job page. If you want this job to execute automatically after the job is ready, you can leave the default option. If you want to review the manifest or the job details before running the job, select Wait to run the job when it’s ready.
This method of creating the job automatically generates the manifest of objects to replicate. A manifest is a list of objects in a given source bucket to apply the replication rules. The generated manifest report has the same format as an Amazon S3 Inventory Report.
S3 Batch Replication creates a Completion report, similar to other Batch Operations jobs, with information on the results of the replication job. It is highly recommended to select this option and to specify a bucket to store this report.

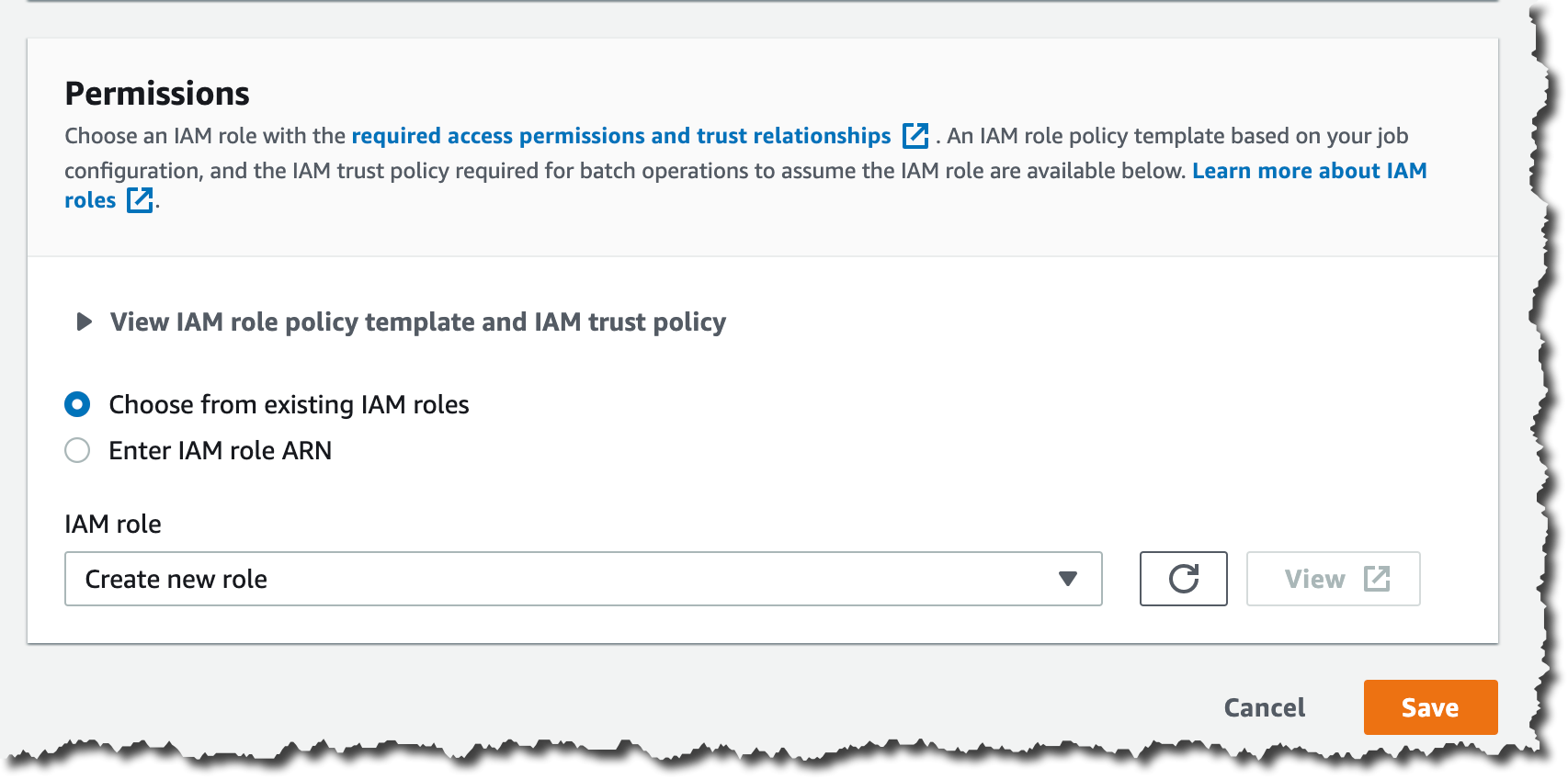
The final step is to configure permissions for creating this batch job. If you keep the default settings, Amazon S3 will create a new AWS Identity and Access Management (IAM) role for you.
After you save this job, check the status of the job on the Batch Operations page. You will see the job changing status as it progresses, the percentage of files that have been replicated, and the total number of files that have failed the replication.
Keep in mind that existing objects can take longer to replicate than new objects, and the replication speed largely depends on the AWS Regions, size of data, object count, and encryption type.

When the Batch Replication job completes, you can navigate to the bucket where you saved the completion report to check the status of object replication. The reports have the same format as an Amazon S3 Inventory Report.

Pricing and availability
When using this feature, you will be charged replication fees for request and data transfer for cross Region, for the
batch operations, and a manifest generation fee if you opted for it.
Additionally, you will be charged the storage cost of storing the replicated data in the destination bucket and AWS KMS charges if your objects are replicated with AWS KMS. Check the Replication tab on the S3 pricing page to learn all the details.
S3 Batch Replication is available in all AWS Regions, including the AWS GovCloud Regions, the AWS China (Beijing) Region, operated by Sinnet, and the AWS China (Ningxia) Region, operated by NWCD. And you can get started using the Amazon S3 console, CLI, S3 API, or AWS SDKs client.
To learn more about S3 Batch Replication, check out the Amazon S3 User Guide.
— Marcia



Source: AWS News