Amazon EMR Serverless Now Generally Available – Run Big Data Applications without Managing Servers
At AWS re:Invent 2021, we introduced three new serverless options for our data analytics services – Amazon EMR Serverless, Amazon Redshift Serverless, and Amazon MSK Serverless – that make it easier to analyze data at any scale without having to configure, scale, or manage the underlying infrastructure.
Today we announce the general availability of Amazon EMR Serverless, a serverless deployment option for customers to run big data analytics applications using open-source frameworks like Apache Spark and Hive without configuring, managing, and scaling clusters or servers.

With EMR Serverless, you can run analytics workloads at any scale with automatic scaling that resizes resources in seconds to meet changing data volumes and processing requirements. EMR Serverless automatically scales resources up and down to provide just the right amount of capacity for your application, and you only pay for what you use.
During the preview, we heard from customers that EMR Serverless is cost-effective because they do not incur cost from having to overprovision resources to deal with demand spikes. They do not have to worry about right-sizing instances or applying OS updates, and can focus on getting products to market faster.
Amazon EMR provides various deployment options to run applications to fit varied needs such as EMR clusters on Amazon Elastic Compute Cloud (Amazon EC2), Amazon Elastic Kubernetes Service (Amazon EKS) clusters, AWS Outposts, or EMR Serverless.
- EMR on Amazon EC2 clusters is suitable for customers that need maximum control and flexibility over how to run their application. With EMR clusters, customers can choose the EC2 instance type to enhance the performance of certain applications, customize the Amazon Machine Image (AMI), choose EC2 instance configuration, customize, and extend open-source frameworks and install additional custom software on cluster instances.
- EMR on Amazon EKS is suitable for customers that want to standardize on EKS to manage clusters across applications or use different versions of an open-source framework on the same cluster.
- EMR on AWS Outposts is for customers who want to run EMR closer to their data center within an Outpost.
- EMR Serverless is suitable for customers that want to avoid managing and operating clusters, and simply want to run applications using open-source frameworks.
Also, when you build an application using an EMR release (for example, a Spark job using EMR release 6.4), you can choose to run it on an EMR cluster, EMR on EKS, or EMR Serverless without having to rewrite the application. This allows you to build applications for a given framework version and retain the flexibility to change the deployment model based on future operational needs.
Getting Started with Amazon EMR Serverless
To get started with EMR Serverless, you can use Amazon EMR Studio, a free EMR feature which provides an end to end development and debugging experience. With EMR Studio, you can create EMR Serverless applications (Spark or Hive), choose the version of open-source software for your application, submit jobs, check the status of running jobs, and invoke Spark UI or Tez UI for job diagnostics.
When you select the Get started button in the EMR Serverless Console, you can create and set up EMR Studio with preconfigured EMR Serverless applications.
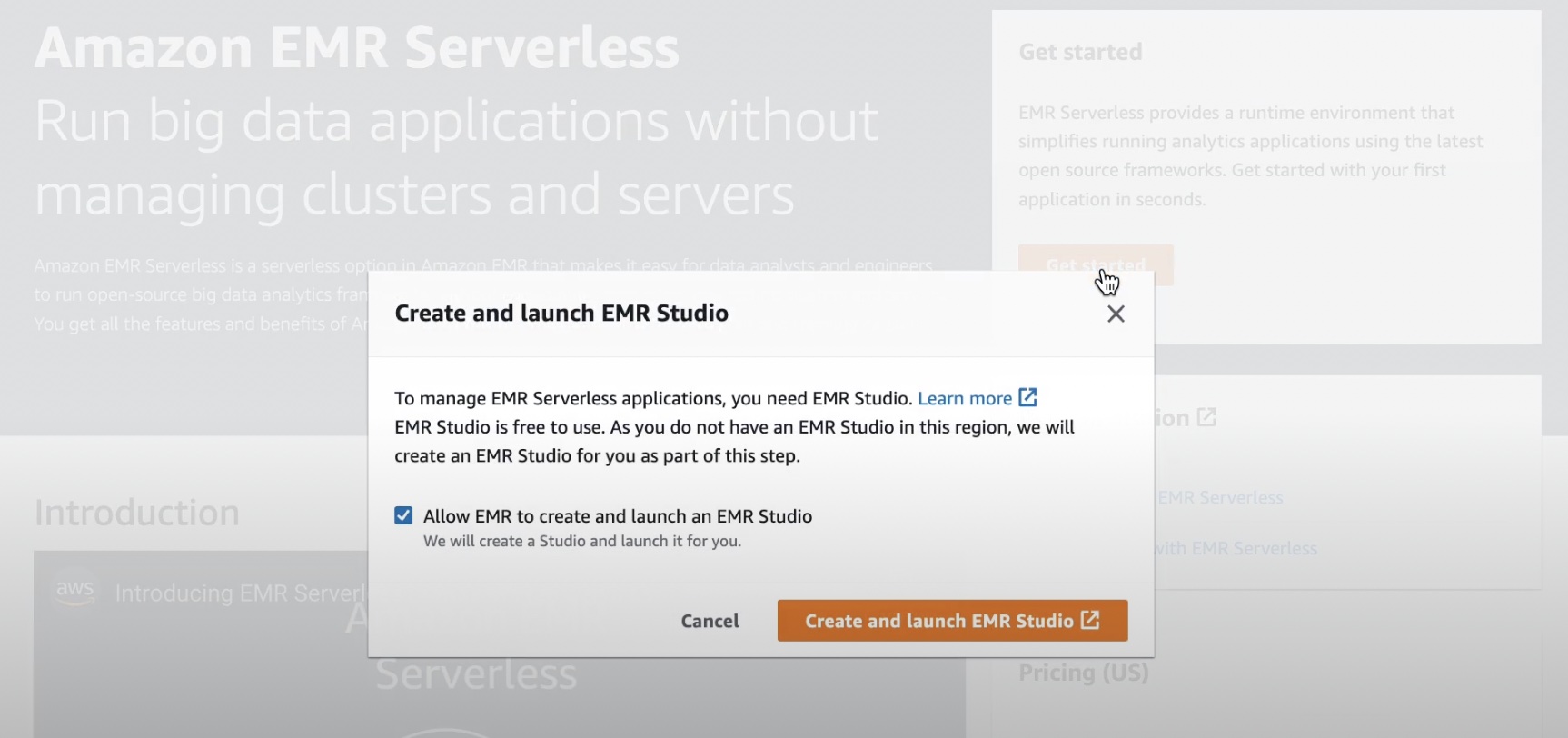
In EMR Studio, when you choose Applications in the Serverless menu, you can create one or more EMR Serverless applications and choose the open source framework and version for your use case. If you want separate logical environments for test and production or for different line-of-business use cases, you can create separate applications for each logical environment.
An EMR Serverless application is a combination of (a) the EMR release version for the open-source framework version you want to use and (b) the specific runtime that you want your application to use, such as Apache Spark or Apache Hive.
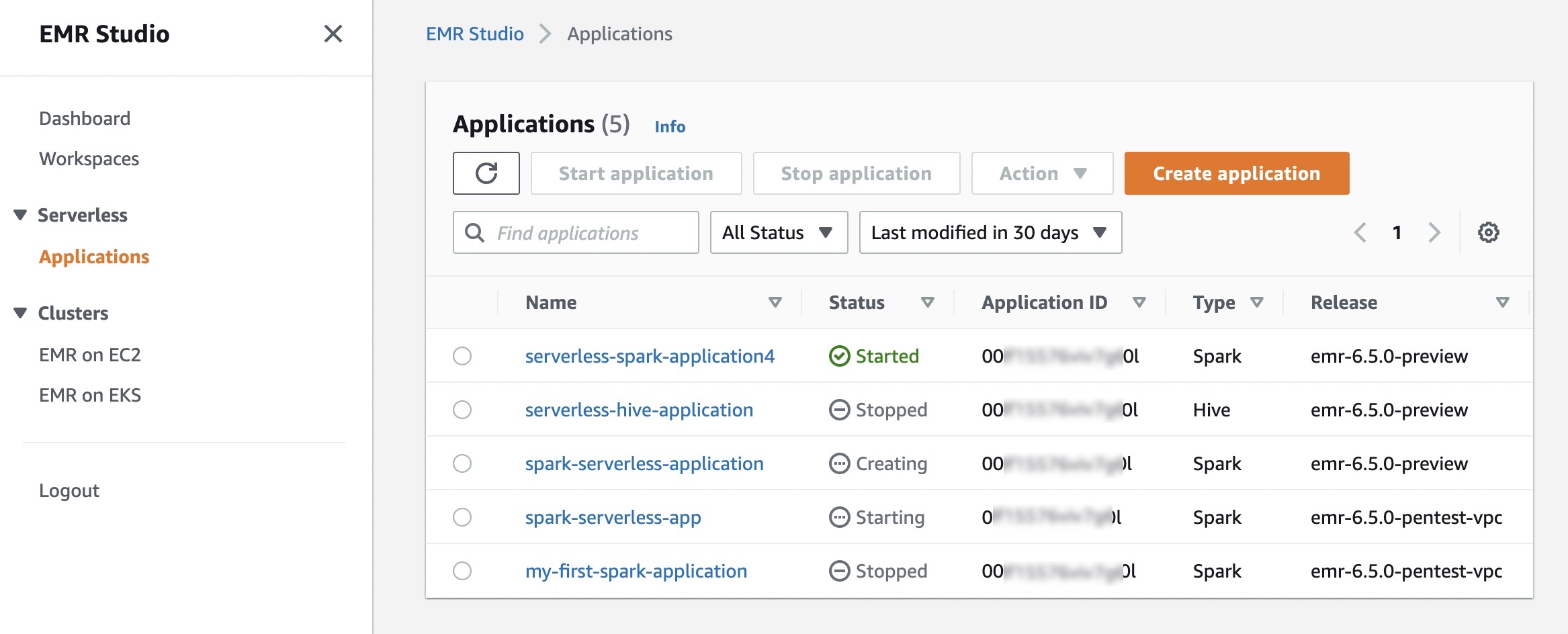
When you choose Create application, you can set your application Name, Type of either Spark or Hive, and supported Release version. You can also select the option of default or custom settings for pre-initialized capacity, application limits, and Amazon Virtual Private Cloud (Amazon VPC) connectivity options. Each EMR Serverless application is isolated from other applications and runs within a secure VPC.
Use the default option if you want jobs to start immediately. But charges apply for each worker when the application is started. To learn more about pre-initialized capacity, see Configuring and managing pre-initialized capacity.
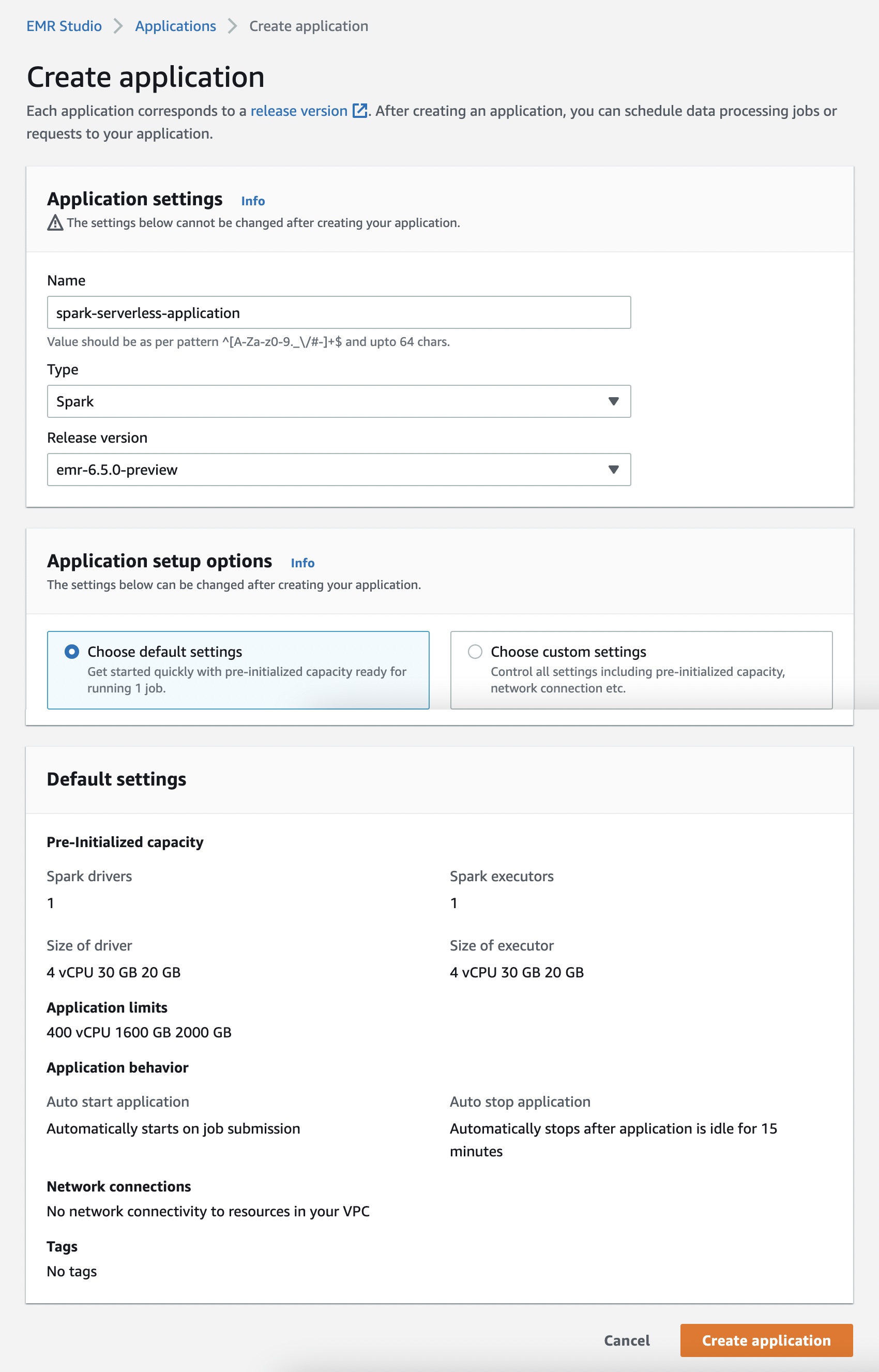
When you select Start application, your application is setup to start with pre-initialized capacity of 1 Spark driver and 1 Spark executor. Your application is by default configured to start when jobs are submitted and stop when the application is idle for more than 15 minutes.
You can customize these settings and setup different application limits by selecting Choose custom settings.
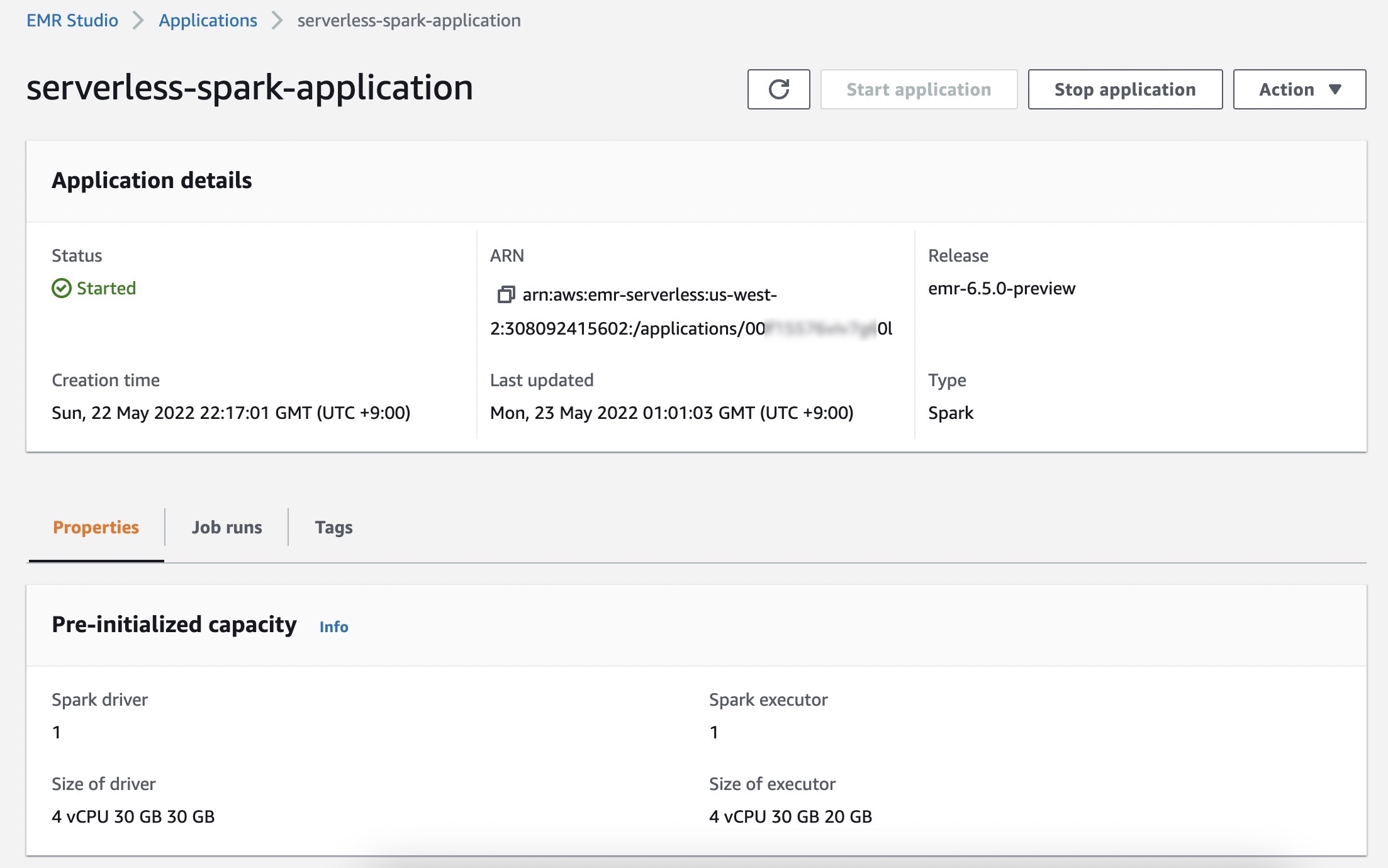
In the Job runs menu, you can see a list of run jobs for your application.
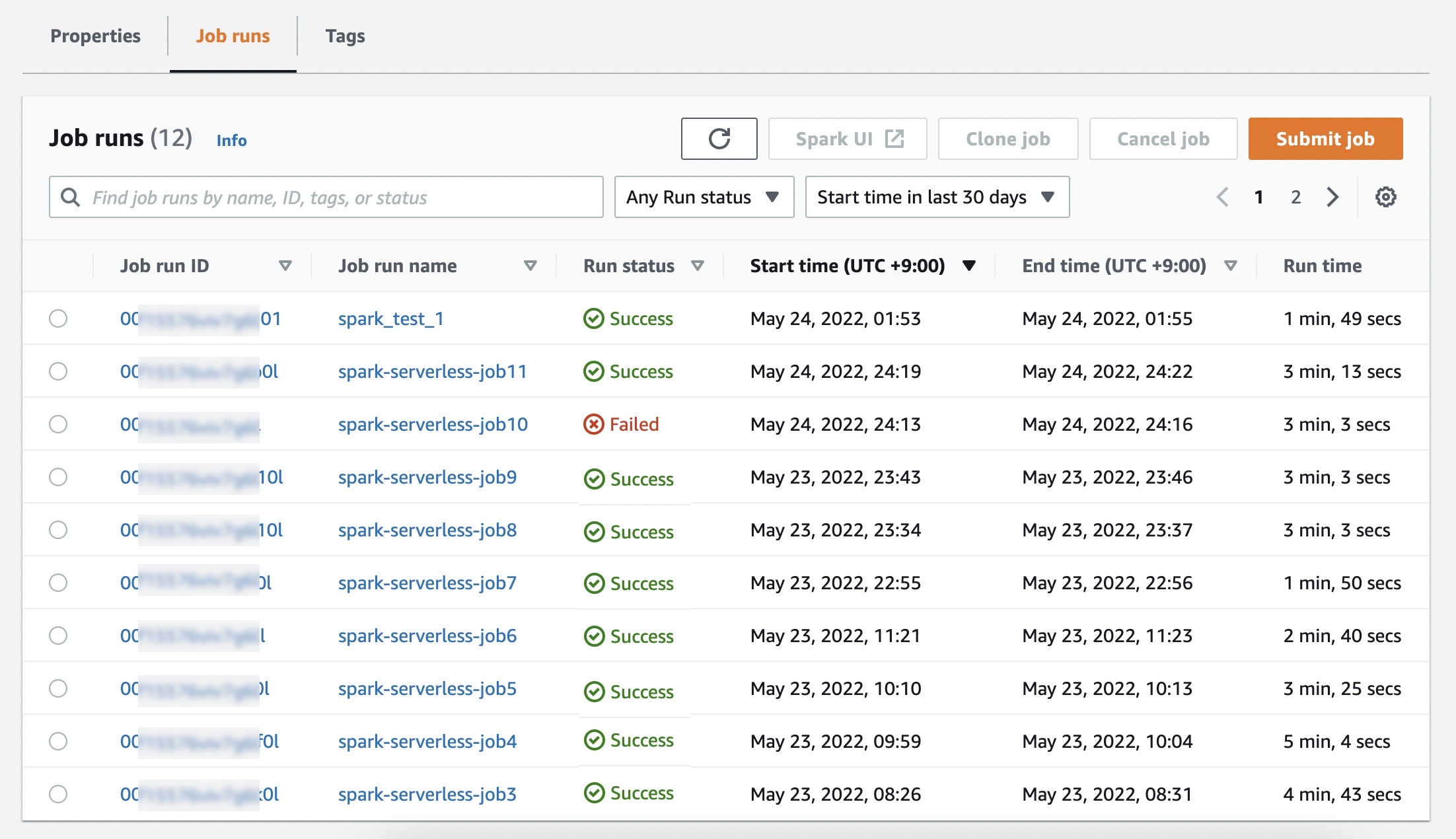
Choose Submit job and set up job details such as the name, AWS Identity and Access Management (IAM) role used by the job, script location, and arguments of the JAR or Python script in the Amazon Simple Storage Service (Amazon S3) bucket that you want to run.
If you want logs for your Spark or Hive jobs to be submitted to your S3 bucket, you will need to setup the S3 bucket in the same Region where you are running EMR Serverless jobs.
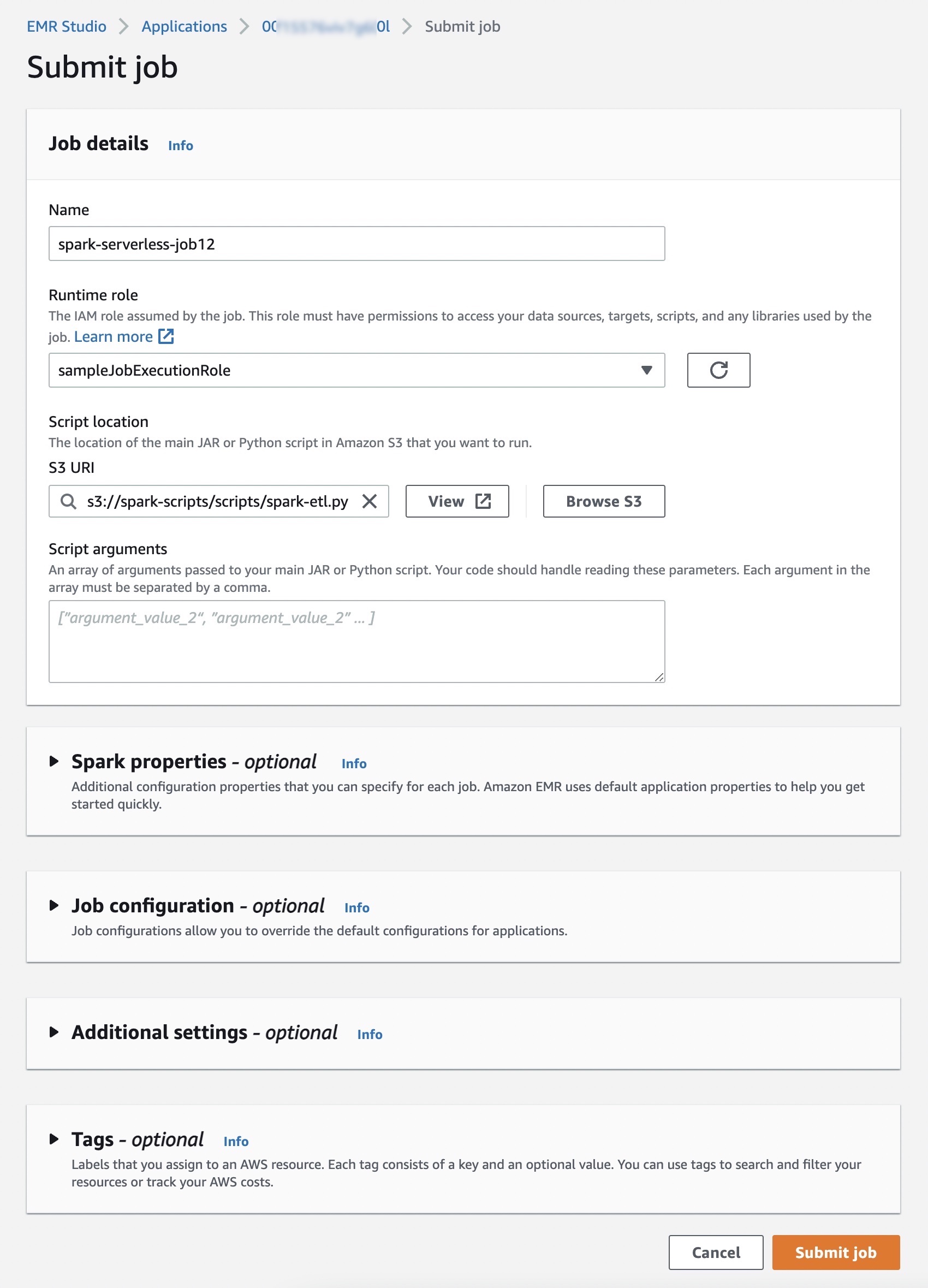
Optionally, you can set additional configuration properties that you can specify for each job, such as Spark properties, job configurations to override the default configurations for applications (such as using the AWS Glue Data Catalog as its metastore), storing logs to Amazon S3, and retaining logs for 30 days.
The following is an example of running a Python script using the StartJobRun API.
$ aws emr-serverless start-job-run
--application-id <application_id>
--execution-role-arn <iam_role_arn>
--job-driver '{
"sparkSubmit": {
"entryPoint": "s3://spark-scripts/scripts/spark-etl.py",
"entryPointArguments": "s3://spark-scripts/output",
"sparkSubmitParameters": "--conf spark.executor.cores=1 --conf spark.executor.memory=4g --conf spark.driver.cores=1 --conf spark.driver.memory=4g --conf spark.executor.instances=1"
}
}'
--configuration-overrides '{
"monitoringConfiguration": {
"s3MonitoringConfiguration": {
"logUri": "s3://spark-scripts/logs/"
}
}
}'You can check on job results in your S3 bucket. For details, you can use Spark UI for Spark Application, and Hive/Tez UI in the Job runs menu to understand how the job ran or to debug it if it failed.
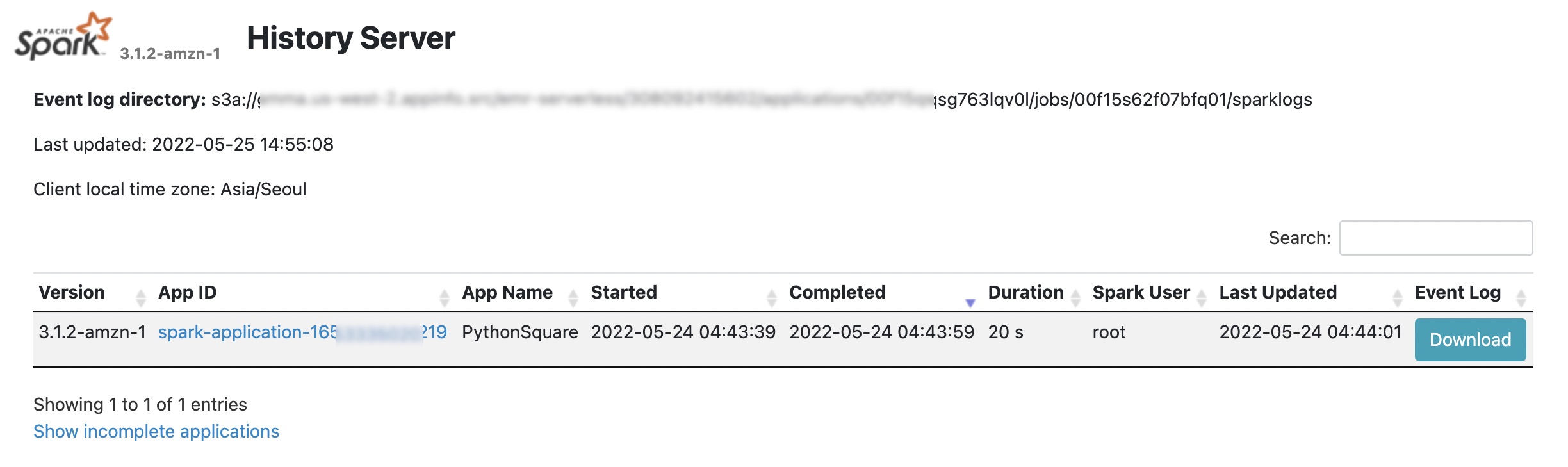
For more debugging, EMR Serverless will push event logs to the sparklogs folder in your S3 log destination for Spark applications. In the case of Hive applications, EMR Serverless will continuously upload the Hive driver and Tez tasks logs to the HIVE_DRIVER or TEZ_TASK folders of your S3 log destination. To learn more, see Logging in the AWS documentation.
Things to Know
With EMR Serverless, you can get all the benefits of running Amazon EMR. I want to quote some things to know about EMR Serverless from an AWS Big Data Blog post of preview announcements:
- Automatic and fine-grained scaling – EMR Serverless automatically scales up workers at each stage of processing your job and scales them down when they’re not required. You’re charged for aggregate vCPU, memory, and storage resources used from the time a worker starts running until it stops, rounded up to the nearest second with a 1-minute minimum. For example, your job may require 10 workers for the first 10 minutes of processing the job and 50 workers for the next 5 minutes. With fine-grained automatic scaling, you only incur cost for 10 workers for 10 minutes and 50 workers for 5 minutes. As a result, you don’t have to pay for underutilized resources.
- Resilience to Availability Zone failures – EMR Serverless is a Regional service. When you submit jobs to an EMR Serverless application, it can run in any Availability Zone in the Region. In case an Availability Zone is impaired, a job submitted to your EMR Serverless application is automatically run in a different (healthy) Availability Zone. When using resources in a private VPC, EMR Serverless recommends that you specify the private VPC configuration for multiple Availability Zones so that EMR Serverless can automatically select a healthy Availability Zone.
- Enable shared applications – When you submit jobs to an EMR Serverless application, you can specify the IAM role that must be used by the job to access AWS resources such as S3 objects. As a result, different IAM principals can run jobs on a single EMR Serverless application, and each job can only access the AWS resources that the IAM principal is allowed to access. This enables you to set up scenarios where a single application with a pre-initialized pool of workers is made available to multiple tenants wherein each tenant can submit jobs using a different IAM role but use the common pool of pre-initialized workers to immediately process requests.
Now Available
Amazon EMR Serverless is available in US East (N. Virginia), US West (Oregon), Europe (Ireland), and Asia Pacific (Tokyo) Regions. With EMR Serverless, there are no upfront costs, and you pay only for the resources you use. You pay for the amount of vCPU, memory, and storage resources consumed by your applications. For pricing details, see the EMR Serverless pricing page.
To learn more, visit the Amazon EMR Serverless User Guide. Please send feedback to AWS re:Post for Amazon EMR Serverless or through your usual AWS support contacts.
Learn all the details about Amazon EMR Serverless and get started today.
– Channy



Source: AWS News