Building Serverless Pipelines with Amazon CloudWatch Events
Guest post by AWS Serverless Hero Forrest Brazeal. Forrest is a senior cloud architect at Trek10, Inc., host of the Think FaaS serverless podcast at Trek10, and a regular speaker at workshops and events in the serverless community.
Events and serverless go together like baked beans and barbecue. The serverless mindset says to focus on code and configuration that provide business value. It turns out that much of the time, this means working with events: structured data corresponding to things that happen in the outside world. Rather than maintaining long-running server tasks that chew up resources while polling, I can create serverless applications that do work only in response to event triggers.
I have lots of options when working with events in AWS: Amazon Kinesis Data Streams, Amazon Simple Notification Service (SNS), Amazon Simple Queue Service (SQS), and more, depending on my requirements. Lately, I’ve been using a service more often that has the word ‘event’ right in the name: Amazon CloudWatch Events.
CloudWatch Events: The best-kept secret in serverless event processing
I first knew CloudWatch as the service that collects my Lambda logs and lets me run functions on a schedule. But CloudWatch Events also lets me publish my own custom events using the CloudWatch API. It has similar pricing and delivery guarantees to SNS, and supports a whole bunch of AWS services as targets.
Best of all, I don’t even have to provision the event bus—it’s just there in the CloudWatch console. I can publish an event now, using the boto3 AWS SDK for Python:
In short, CloudWatch Events gives me a fully managed event pipe that supports an arbitrary number of consumers, where I can drop any kind of JSON string that I want. And this is super useful for building serverless apps.
Event-driven architectures in action
I build cloud-native solutions for clients at Trek10 daily. I frequently use event-driven architectures as a powerful way to migrate legacy systems to serverless, enable easier downstream integrations, and more. Here are just a couple of my favorite patterns:
• Strangling legacy databases
• Designing event-sourced applications
Strangling legacy databases
The “strangler pattern” hides a legacy system behind a wrapper API, while gradually migrating users to the new interface. Trek10 has written about this before. Streaming changes to the cloud as events is a great way to open up reporting and analytics use cases while taking load off a legacy database. The following diagram shows writing a legacy database to events.

This pattern can also work the other way: I can write new data to CloudWatch Events, consume it into a modern data source, and create a second consumer that syncs the data back to my legacy system.
Designing event-sourced applications
Event sourcing simply means treating changes in the system state as events, publishing them on a ledger or bus where they can be consumed by different downstream applications.
Using CloudWatch Events as a centralized bus, I can make a sanitized record of events available as shown in the following event validation flow diagram.
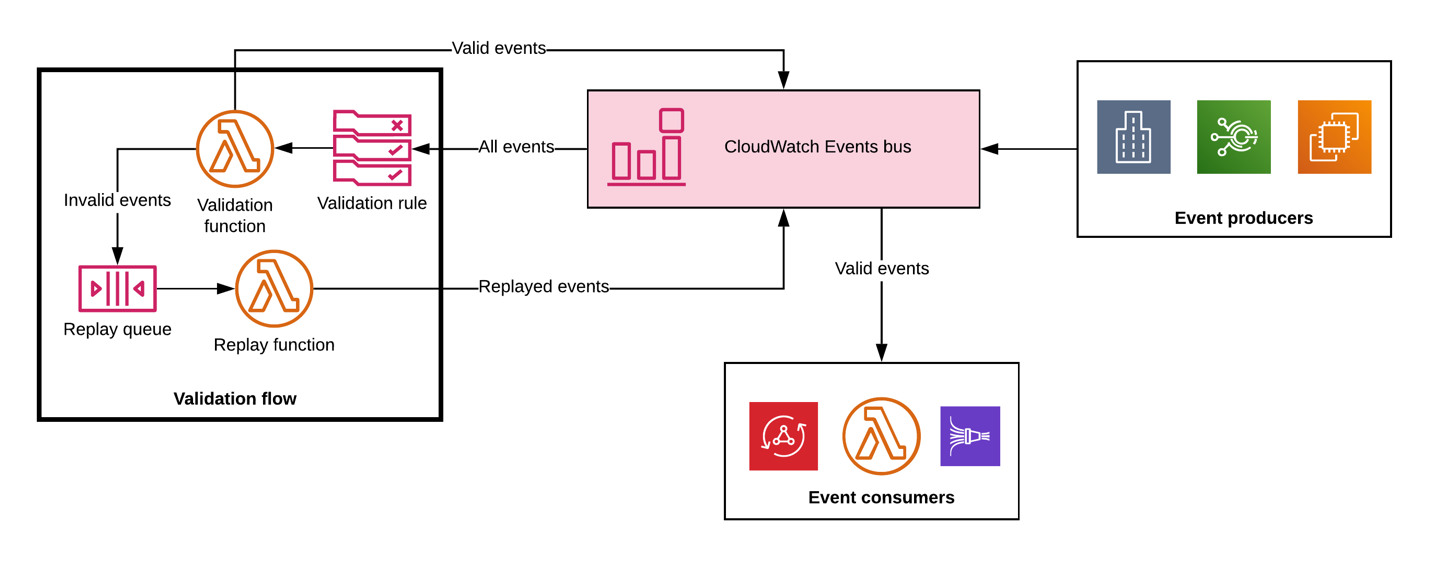
The validation function ensures that only events that match my application’s standards get tagged as “valid” and are made available to downstream consumers. The default bus handles lots of events (remember, service logs go here!), so it’s important to set up rules that only match the events that I care about.
CloudWatch Events simplifies these patterns by providing a single bus where I can apply filters and subscribe consumers, all without having to provision or maintain any infrastructure. And that’s just the beginning.
Use case: Multi-account event processing with CloudWatch Events
CloudWatch Events gets most interesting when I start connecting multiple AWS accounts. It’s easy to set up a trust relationship between CloudWatch Event buses in different accounts, using filtering rules to choose which events get forwarded.
As an example, imagine a widget processing system for a large enterprise, AnyCompany. AnyCompany has many different development teams, each using their own AWS account. Some services are producing information about widgets as they check into warehouses or travel across the country. Others need that data to run reports or innovate new products.
Suppose that Service A produces information about new widgets, Service B wants to view aggregates about widgets in real time, and Service C needs historical data about widgets for reporting. The full event flow might look like the following diagram.
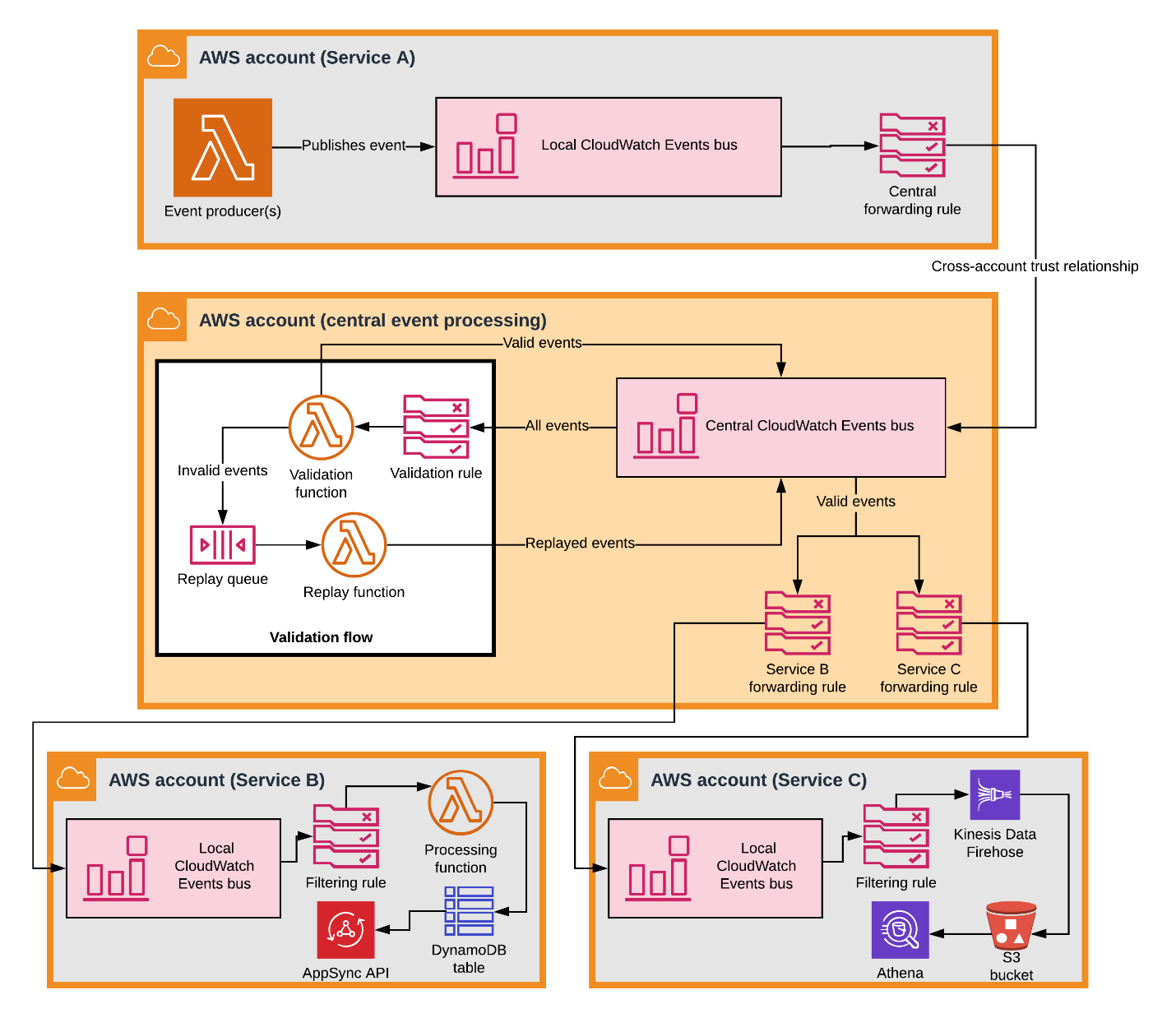
1. Service A publishes the new widget event to CloudWatch Events in their AWS account with the following event body:
2. A filtering rule forwards events tagged with cwi.servicea to the central event processing account. Using CloudFormation, they could define the rule as follows:
3. The event is validated according to their standards.
4. The valid event is republished on the central event bus with a new source, valid.cw.servicea. This is important because, to avoid infinite loops, an individual event can only be forwarded one time.
5. A filtering rule forwards the valid event to Service B’s AWS account, where it updates a DynamoDB table connected to an AWS AppSync API.
6. A second rule forwards the same event to the Service C account, where it flows through Kinesis Data Firehose to an Amazon S3 bucket for analysis using Amazon Athena.
What CloudWatch Events provides here is a decoupled system that uses mostly “plug-and-play” services, and yet opens up flexibility for future innovation.
Taking full advantage of the cloud
The biggest reason I love CloudWatch Events? It’s a fantastically cloud-native service. There’s little code required, and no operational responsibilities beyond watching AWS service limits. I don’t even have to deploy anything to start using it. And yet, under the hood, I’m using a powerful piece of AWS infrastructure that can support complex distributed applications without breaking a sweat.
That’s pretty close to the platonic ideal of serverless apps. Anytime I’m cooking up an event-driven application, I make sure to consider what CloudWatch Events can bring to the table.



Source: AWS News