New – A Shared File System for Your Lambda Functions
I am very happy to announce that AWS Lambda functions can now mount an Amazon Elastic File System (EFS), a scalable and elastic NFS file system storing data within and across multiple availability zones (AZ) for high availability and durability. In this way, you can use a familiar file system interface to store and share data across all concurrent execution environments of one, or more, Lambda functions. EFS supports full file system access semantics, such as strong consistency and file locking.
To connect an EFS file system with a Lambda function, you use an EFS access point, an application-specific entry point into an EFS file system that includes the operating system user and group to use when accessing the file system, file system permissions, and can limit access to a specific path in the file system. This helps keeping file system configuration decoupled from the application code.
You can access the same EFS file system from multiple functions, using the same or different access points. For example, using different EFS access points, each Lambda function can access different paths in a file system, or use different file system permissions.
You can share the same EFS file system with Amazon Elastic Compute Cloud (EC2) instances, containerized applications using Amazon ECS and AWS Fargate, and on-premises servers. Following this approach, you can use different computing architectures (functions, containers, virtual servers) to process the same files. For example, a Lambda function reacting to an event can update a configuration file that is read by an application running on containers. Or you can use a Lambda function to process files uploaded by a web application running on EC2.
In this way, some use cases are much easier to implement with Lambda functions. For example:
- Processing or loading data larger than the space available in
/tmp(512MB). - Loading the most updated version of files that change frequently.
- Using data science packages that require storage space to load models and other dependencies.
- Saving function state across invocations (using unique file names, or file system locks).
- Building applications requiring access to large amounts of reference data.
- Migrating legacy applications to serverless architectures.
- Interacting with data intensive workloads designed for file system access.
- Partially updating files (using file system locks for concurrent access).
- Moving a directory and all its content within a file system with an atomic operation.
Creating an EFS File System
To mount an EFS file system, your Lambda functions must be connected to an Amazon Virtual Private Cloud that can reach the EFS mount targets. For simplicity, I am using here the default VPC that is automatically created in each AWS Region.
Note that, when connecting Lambda functions to a VPC, networking works differently. If your Lambda functions are using Amazon Simple Storage Service (S3) or Amazon DynamoDB, you should create a gateway VPC endpoint for those services. If your Lambda functions need to access the public internet, for example to call an external API, you need to configure a NAT Gateway. I usually don’t change the configuration of my default VPCs. If I have specific requirements, I create a new VPC with private and public subnets using the AWS Cloud Development Kit, or use one of these AWS CloudFormation sample templates. In this way, I can manage networking as code.
In the EFS console, I select Create file system and make sure that the default VPC and its subnets are selected. For all subnets, I use the default security group that gives network access to other resources in the VPC using the same security group.

In the next step, I give the file system a Name tag and leave all other options to their default values.

Then, I select Add access point. I use 1001 for the user and group IDs and limit access to the /message path. In the Owner section, used to create the folder automatically when first connecting to the access point, I use the same user and group IDs as before, and 750 for permissions. With this permissions, the owner can read, write, and execute files. Users in the same group can only read. Other users have no access.

I go on, and complete the creation of the file system.
Using EFS with Lambda Functions
To start with a simple use case, let’s build a Lambda function implementing a MessageWall API to add, read, or delete text messages. Messages are stored in a file on EFS so that all concurrent execution environments of that Lambda function see the same content.
In the Lambda console, I create a new MessageWall function and select the Python 3.8 runtime. In the Permissions section, I leave the default. This will create a new AWS Identity and Access Management (IAM) role with basic permissions.
When the function is created, in the Permissions tab I click on the IAM role name to open the role in the IAM console. Here, I select Attach policies to add the AWSLambdaVPCAccessExecutionRole and AmazonElasticFileSystemClientReadWriteAccess AWS managed policies. In a production environment, you can restrict access to a specific VPC and EFS access point.
Back in the Lambda console, I edit the VPC configuration to connect the MessageWall function to all subnets in the default VPC, using the same default security group I used for the EFS mount points.
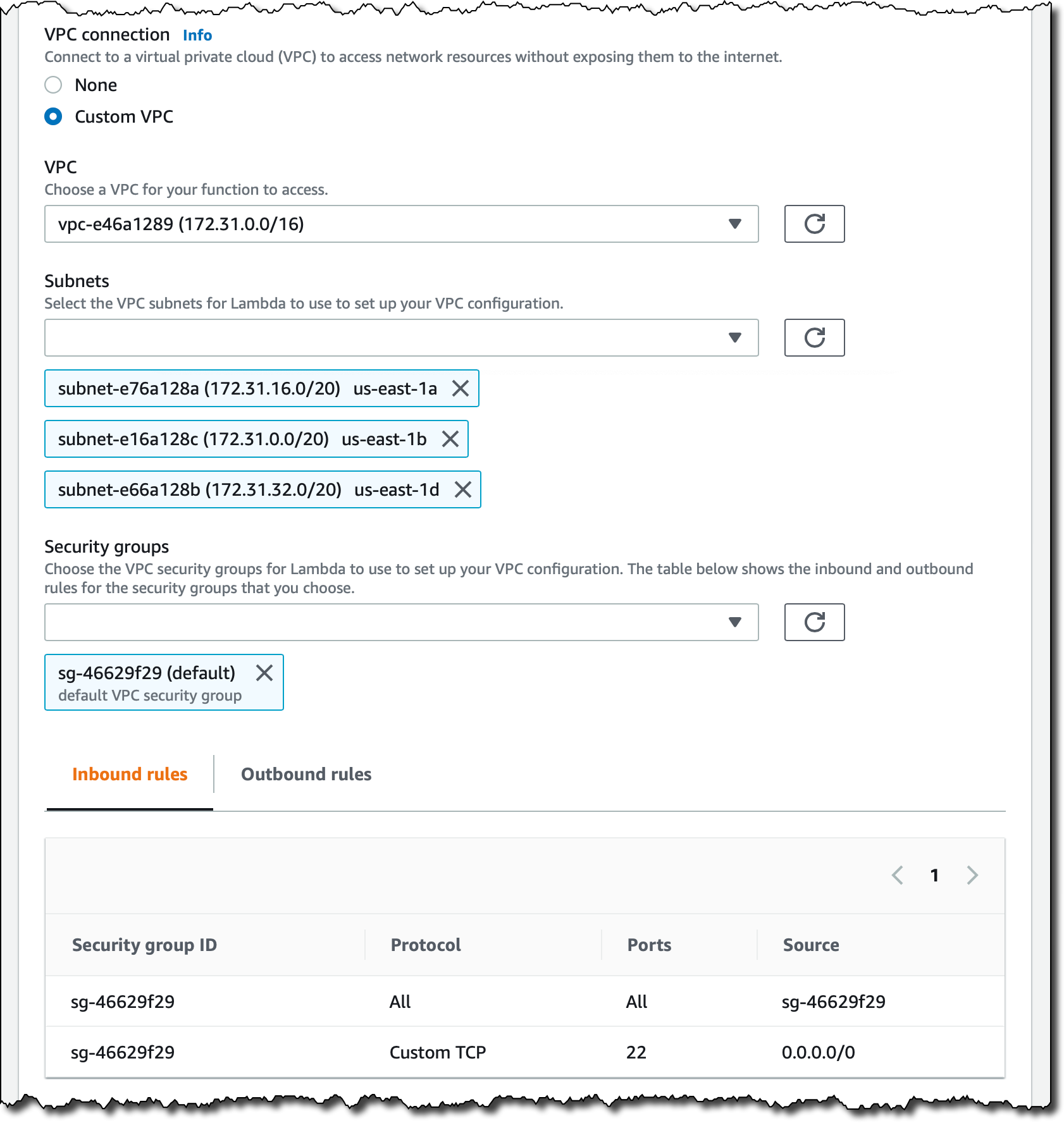
Now, I select Add file system in the new File system section of the function configuration. Here, I choose the EFS file system and accesss point I created before. For the local mount point, I use /mnt/msg and Save. This is the path where the access point will be mounted, and corresponds to the /message folder in my EFS file system.

In the Function code editor of the Lambda console, I paste the following code and Save.
import os
import fcntl
MSG_FILE_PATH = '/mnt/msg/content'
def get_messages():
try:
with open(MSG_FILE_PATH, 'r') as msg_file:
fcntl.flock(msg_file, fcntl.LOCK_SH)
messages = msg_file.read()
fcntl.flock(msg_file, fcntl.LOCK_UN)
except:
messages = 'No message yet.'
return messages
def add_message(new_message):
with open(MSG_FILE_PATH, 'a') as msg_file:
fcntl.flock(msg_file, fcntl.LOCK_EX)
msg_file.write(new_message + "n")
fcntl.flock(msg_file, fcntl.LOCK_UN)
def delete_messages():
try:
os.remove(MSG_FILE_PATH)
except:
pass
def lambda_handler(event, context):
method = event['requestContext']['http']['method']
if method == 'GET':
messages = get_messages()
elif method == 'POST':
new_message = event['body']
add_message(new_message)
messages = get_messages()
elif method == 'DELETE':
delete_messages()
messages = 'Messages deleted.'
else:
messages = 'Method unsupported.'
return messages
I select Add trigger and in the configuration I select the Amazon API Gateway. I create a new HTTP API. For simplicity, I leave my API endpoint open.

With the API Gateway trigger selected, I copy the endpoint of the new API I just created.
I can now use curl to test the API:
$ curl https://1a2b3c4d5e.execute-api.us-east-1.amazonaws.com/default/MessageWall
No message yet.
$ curl -X POST -H "Content-Type: text/plain" -d 'Hello from EFS!' https://1a2b3c4d5e.execute-api.us-east-1.amazonaws.com/default/MessageWall
Hello from EFS!
$ curl -X POST -H "Content-Type: text/plain" -d 'Hello again :)' https://1a2b3c4d5e.execute-api.us-east-1.amazonaws.com/default/MessageWall
Hello from EFS!
Hello again :)
$ curl https://1a2b3c4d5e.execute-api.us-east-1.amazonaws.com/default/MessageWall
Hello from EFS!
Hello again :)
$ curl -X DELETE https://1a2b3c4d5e.execute-api.us-east-1.amazonaws.com/default/MessageWall
Messages deleted.
$ curl https://1a2b3c4d5e.execute-api.us-east-1.amazonaws.com/default/MessageWall
No message yet.It would be relatively easy to add unique file names (or specific subdirectories) for different users and extend this simple example into a more complete messaging application. As a developer, I appreciate the simplicity of using a familiar file system interface in my code. However, depending on your requirements, EFS throughput configuration must be taken into account. See the section Understanding EFS performance later in the post for more information.
Now, let’s use the new EFS file system support in AWS Lambda to build something more interesting. For example, let’s use the additional space available with EFS to build a machine learning inference API processing images.
Building a Serverless Machine Learning Inference API
To create a Lambda function implementing machine learning inference, I need to be able, in my code, to import the necessary libraries and load the machine learning model. Often, when doing so, the overall size of those dependencies goes beyond the current AWS Lambda limits in the deployment package size. One way of solving this is to accurately minimize the libraries to ship with the function code, and then download the model from an S3 bucket straight to memory (up to 3 GB, including the memory required for processing the model) or to /tmp (up 512 MB). This custom minimization and download of the model has never been easy to implement. Now, I can use an EFS file system.
The Lambda function I am building this time needs access to the public internet to download a pre-trained model and the images to run inference on. So I create a new VPC with public and private subnets, and configure a NAT Gateway and the route table used by the the private subnets to give access to the public internet. Using the AWS Cloud Development Kit, it’s just a few lines of code.
I create a new EFS file system and an access point in the new VPC using similar configurations as before. This time, I use /ml for the access point path.
Then, I create a new MLInference Lambda function with the same set up as before for permissions and connect the function to the private subnets of the new VPC. Machine learning inference is quite a heavy workload, so I select 3 GB for memory and 5 minutes for timeout. In the File system configuration, I add the new access point and mount it under /mnt/inference.
The machine learning framework I am using for this function is PyTorch, and I need to put the libraries required to run inference in the EFS file system. I launch an Amazon Linux EC2 instance in a public subnet of the new VPC. In the instance details, I select one of the availability zones where I have an EFS mount point, and then Add file system to automatically mount the same EFS file system I am using for the function. For the security groups of the EC2 instance, I select the default security group (to be able to mount the EFS file system) and one that gives inbound access to SSH (to be able to connect to the instance).
I connect to the instance using SSH and create a requirements.txt file containing the dependencies I need:
torch
torchvision
numpy
The EFS file system is automatically mounted by EC2 under /mnt/efs/fs1. There, I create the /ml directory and change the owner of the path to the user and group I am using now that I am connected (ec2-user).
$ sudo mkdir /mnt/efs/fs1/ml
$ sudo chown ec2-user:ec2-user /mnt/efs/fs1/mlI install Python 3 and use pip to install the dependencies in the /mnt/efs/fs1/ml/lib path:
$ sudo yum install python3
$ pip3 install -t /mnt/efs/fs1/ml/lib -r requirements.txt
Finally, I give ownership of the whole /ml path to the user and group I used for the EFS access point:
$ sudo chown -R 1001:1001 /mnt/efs/fs1/ml
Overall, the dependencies in my EFS file system are using about 1.5 GB of storage.
I go back to the MLInference Lambda function configuration. Depending on the runtime you use, you need to find a way to tell where to look for dependencies if they are not included with the deployment package or in a layer. In the case of Python, I set the PYTHONPATH environment variable to /mnt/inference/lib.
I am going to use PyTorch Hub to download this pre-trained machine learning model to recognize the kind of bird in a picture. The model I am using for this example is relatively small, about 200 MB. To cache the model on the EFS file system, I set the TORCH_HOME environment variable to /mnt/inference/model.

All dependencies are now in the file system mounted by the function, and I can type my code straight in the Function code editor. I paste the following code to have a machine learning inference API:
import urllib
import json
import os
import torch
from PIL import Image
from torchvision import transforms
transform_test = transforms.Compose([
transforms.Resize((600, 600), Image.BILINEAR),
transforms.CenterCrop((448, 448)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
model = torch.hub.load('nicolalandro/ntsnet-cub200', 'ntsnet', pretrained=True,
**{'topN': 6, 'device': 'cpu', 'num_classes': 200})
model.eval()
def lambda_handler(event, context):
url = event['queryStringParameters']['url']
img = Image.open(urllib.request.urlopen(url))
scaled_img = transform_test(img)
torch_images = scaled_img.unsqueeze(0)
with torch.no_grad():
top_n_coordinates, concat_out, raw_logits, concat_logits, part_logits, top_n_index, top_n_prob = model(torch_images)
_, predict = torch.max(concat_logits, 1)
pred_id = predict.item()
bird_class = model.bird_classes[pred_id]
print('bird_class:', bird_class)
return json.dumps({
"bird_class": bird_class,
})I add the API Gateway as trigger, similarly to what I did before for the MessageWall function. Now, I can use the serverless API I just created to analyze pictures of birds. I am not really an expert in the field, so I looked for a couple of interesting images on Wikipedia:
- An atlantic puffin.

- A western grebe.



I call the API to get a prediction for these two pictures:
$ curl https://1a2b3c4d5e.execute-api.us-east-1.amazonaws.com/default/MLInference?url=https://path/to/image/atlantic-puffin.jpg
{"bird_class": "106.Horned_Puffin"}
$ curl https://1a2b3c4d5e.execute-api.us-east-1.amazonaws.com/default/MLInference?url=https://path/to/image/western-grebe.jpg
{"bird_class": "053.Western_Grebe"}It works! Looking at Amazon CloudWatch Logs for the Lambda function, I see that the first invocation, when the function loads and prepares the pre-trained model for inference on CPUs, takes about 30 seconds. To avoid a slow response, or a timeout from the API Gateway, I use Provisioned Concurrency to keep the function ready. The next invocations take about 1.8 seconds.
Understanding EFS Performance
When using EFS with your Lambda function, is very important to understand how EFS performance works. For throughput, each file system can be configured to use bursting or provisioned mode.
When using bursting mode, all EFS file systems, regardless of size, can burst at least to 100 MiB/s of throughput. Those over 1 TiB in the standard storage class can burst to 100 MiB/s per TiB of data stored in the file system. EFS uses a credit system to determine when file systems can burst. Each file system earns credits over time at a baseline rate that is determined by the size of the file system that is stored in the standard storage class. A file system uses credits whenever it reads or writes data. The baseline rate is 50 KiB/s per GiB of storage.
You can monitor the use of credits in CloudWatch, each EFS file system has a BurstCreditBalance metric. If you see that you are consuming all credits, and the BurstCreditBalance metric is going to zero, you should enable provisioned throughput mode for the file system, from 1 to 1024 MiB/s. There is an additional cost when using provisioned throughput, based on how much throughput you are adding on top of the baseline rate.
To avoid running out of credits, you should think of the throughput as the average you need during the day. For example, if you have a 10GB file system, you have 500 KiB/s of baseline rate, and every day you can read/write 500 KiB/s * 3600 seconds * 24 hours = 43.2 GiB.
If the libraries and everything you function needs to load during initialization are about 2 GiB, and you only access the EFS file system during function initialization, like in the MLInference Lambda function above, that means you can initialize your function (for example because of updates or scaling up activities) about 20 times per day. That’s not a lot, and you would probably need to configure provisioned throughput for the EFS file system.
If you have 10 MiB/s of provisioned throughput, then every day you have 10 MiB/s * 3600 seconds * 24 hours = 864 GiB to read or write. If you only use the EFS file system at function initialization to read about 2 GB of dependencies, it means that you can have 400 initializations per day. That may be enough for your use case.
In the Lambda function configuration, you can also use the reserve concurrency control to limit the maximum number of execution environments used by a function.
If, by mistake, the BurstCreditBalance goes down to zero, and the file system is relatively small (for example, a few GiBs), there is the possibility that your function gets stuck and can’t execute fast enough before reaching the timeout. In that case, you should enable (or increase) provisioned throughput for the EFS file system, or throttle your function by setting the reserved concurrency to zero to avoid all invocations until the EFS file system has enough credits.
Understanding Security Controls
When using EFS file systems with AWS Lambda, you have multiple levels of security controls. I’m doing a quick recap here because they should all be considered during the design and implementation of your serverless applications. You can find more info on using IAM authorization and access points with EFS in this post.
To connect a Lambda function to an EFS file system, you need:
- Network visibility in terms of VPC routing/peering and security group.
- IAM permissions for the Lambda function to access the VPC and mount (read only or read/write) the EFS file system.
- You can specify in the IAM policy conditions which EFS access point the Lambda function can use.
- The EFS access point can limit access to a specific path in the file system.
- File system security (user ID, group ID, permissions) can limit read, write, or executable access for each file or directory mounted by a Lambda function.
The Lambda function execution environment and the EFS mount point uses industry standard Transport Layer Security (TLS) 1.2 to encrypt data in transit. You can provision Amazon EFS to encrypt data at rest. Data encrypted at rest is transparently encrypted while being written, and transparently decrypted while being read, so you don’t have to modify your applications. Encryption keys are managed by the AWS Key Management Service (KMS), eliminating the need to build and maintain a secure key management infrastructure.
Available Now
This new feature is offered in all regions where AWS Lambda and Amazon EFS are available, with the exception of the regions in China, where we are working to make this integration available as soon as possible. For more information on availability, please see the AWS Region table. To learn more, please see the documentation.
EFS for Lambda can be configured using the console, the AWS Command Line Interface (CLI), the AWS SDKs, and the Serverless Application Model. This feature allows you to build data intensive applications that need to process large files. For example, you can now unzip a 1.5 GB file in a few lines of code, or process a 10 GB JSON document. You can also load libraries or packages that are larger than the 250 MB package deployment size limit of AWS Lambda, enabling new machine learning, data modelling, financial analysis, and ETL jobs scenarios.
Amazon EFS for Lambda is supported at launch in AWS Partner Network solutions, including Epsagon, Lumigo, Datadog, HashiCorp Terraform, and Pulumi.
There is no additional charge for using EFS from Lambda functions. You pay the standard price for AWS Lambda and Amazon EFS. Lambda execution environments always connect to the right mount target in an AZ and not across AZs. You can connect to EFS in the same AZ via cross account VPC but there can be data transfer costs for that. We do not support cross region, or cross AZ connectivity between EFS and Lambda.
— Danilo



Source: AWS News