New – Announcing Amazon AppFlow
Software as a service (SaaS) applications are becoming increasingly important to our customers, and adoption is growing rapidly. While there are many benefits to this way of consuming software, one challenge is that data is now living in lots of different places. To get meaningful insights from this data, we need to have a way to analyze it, and that can be hard when our data is spread out across multiple data islands.
Developers spend huge amounts of time writing custom integrations so they can pass data between SaaS applications and AWS services so that it can be analysed; these can be expensive and can often take months to complete. If data requirements change, then costly and complicated modifications have to be made to the integrations. Companies that don’t have the luxury of engineering resources might find themselves manually importing and exporting data from applications, which is time-consuming, risks data leakage, and has the potential to introduce human error.
Today it is my pleasure to announce a new service called Amazon AppFlow that will solve this issue. Amazon AppFlow allows you to automate the data flows between AWS services and SaaS applications such as Salesforce, Zendesk, and ServiceNow. SaaS application administrators, business analysts, and BI specialists can quickly implement most of the integrations they need without waiting months for IT to finish integration projects.
As well as allowing data to flow in from SaaS applications to AWS services, it’s also capable of sending data from AWS services to SaaS applications. Security is our top priority at AWS, and so all of the data is encrypted while in motion. Some of the SaaS applications have integrated with AWS PrivateLink; this adds an extra layer of security and privacy. When the data flows between the SaaS application and AWS with AWS PrivateLink, the traffic stays on the Amazon network rather than using the public internet. If the SaaS application supports it, Amazon AppFlow automatically takes care of this connection, making private data transfer easy for everyone and minimizing the threat from internet-based attacks and the risk of sensitive data leakage.
You can schedule the data transfer to happen on a schedule, in response to a business event, or on demand, giving you speed and flexibility with your data sharing.
To show you the power of this new service, I thought it would be interesting to show you how to set up a simple flow.
I run a Slack workspace in the United Kingdom and Ireland for web community organizers. Since Slack is one of the supported SaaS applications in Amazon AppFlow, I thought it would be nice to try and import some of the conversation data into S3. Once it was in S3 I could then start to analyze it using Amazon Athena and then ultimately create a visualization using Amazon QuickSight.
To get started, I go to the Amazon AppFlow console and click the Create Flow button.
In the next step, I enter the Flow name and a Flow description. There are also some options for data encryption. By default, all data is encrypted in transit, and in the case of S3 it’s also encrypted at rest. You have the option to supply your own encryption key, but for this demo, I’m just going to use the key in my account that is used by default.
On this step you are also given the option to enter Tags for the resource, I have been getting into the habit of tagging demo infrastructure in my account as Demo which makes it easier for me to know which resources I can delete.

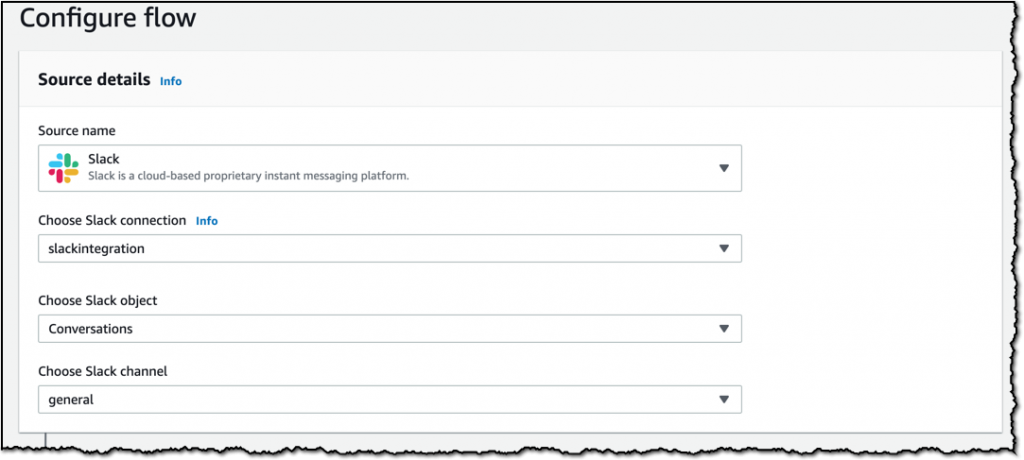
On the next step, I select the source of my data. I pick Slack and go through the wizard to establish a connection with my Slack workspace. I also get to choose what data I want to import from my Slack Workspace. I select the Conversations object in the general slack channel. This will import any messages that are posted to the general channel and then send it to the destination that I configure next.
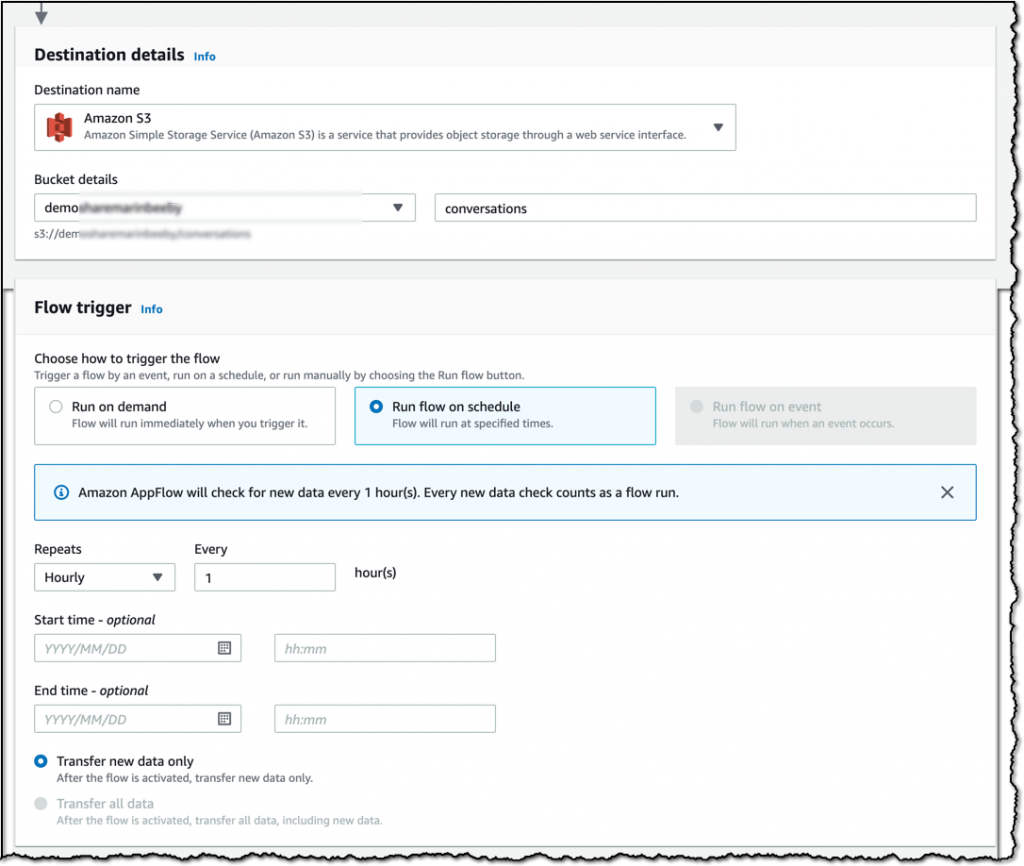
There are a few destinations that I can pick, but to keep things simple, I ask for the data to be sent to an S3 bucket. I also set the frequency that I want to fetch the data on this step. I want the data to be retrieved every hour, so I select Run the flow on schedule and make the necessary configurations. Slack can be triggered on demand or on schedule; some other sources can be triggered by specific events, such as converting a lead in Salesforce.
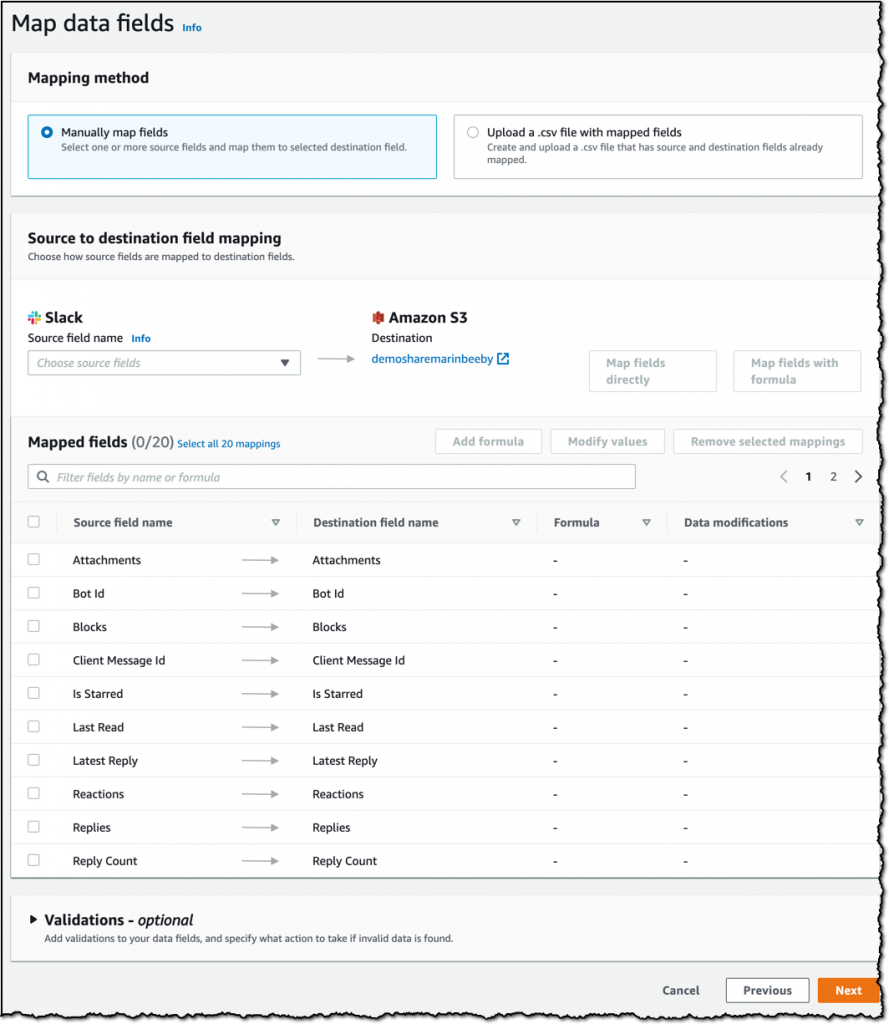
The next step is to map the data fields, I am just going to go with the defaults, but you could customize this and combine fields or take only the specific fields required for analysis.
Now the flow has been created, and I have activated it; it runs automatically every hour, adding new data to my S3 bucket.

I won’t go into the specifics of Amazon Athena or Amazon QuickSight, but I used both of these AWS services to take my data stored in S3 and produce a word cloud of the most common words that are used in my Slack Channel.
The cool thing about Athena is that you can run SQL queries directly over the encrypted data in S3 without needing any additional data warehouse. You can see the results in the image below. I could now easily share this as a dashboard with anyone in my organization.
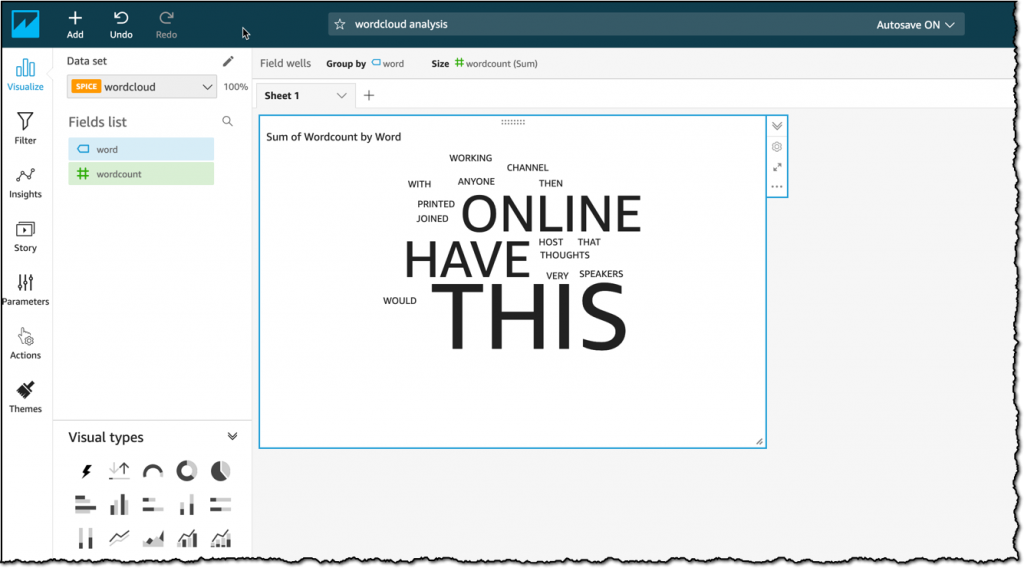
Amazon AppFlow is launching today with support for S3 and 13 SaaS applications as sources of data, and S3, Amazon Redshift, Salesforce, and Snowflake as destinations, and you will see us add hundreds more as the service develops.
The service automatically scales up or down to meet the demands you place on it, it also allows you to transfer 100GB in a single flow which means you don’t need to break data down into batches. You can trust Amazon AppFlow with your most valuable data as we have architected to be highly available and resilient.
Amazon AppFlow is available from today in US East (Northern Virginia), US East (Ohio), US West (Northern California), US West (Oregon), Canada (Central), Asia Pacific (Singapore), Asia Pacific (Toyko), Asia Pacific (Sydney), Asia Pacific (Seoul), Asia Pacific (Mumbai), Europe (Paris), Europe (Ireland), Europe (Frankfurt), Europe (London), and South America (São Paulo) with more regions to come.
Happy Data Flowing



Source: AWS News