Pick the Right Tool for your IT Challenge
This guest post is by AWS Community Hero Markus Ostertag. As CEO of the Munich-based ad-tech company Team Internet AG, Markus is always trying to find the best ways to leverage the cloud, loves to work with cutting-edge technologies, and is a frequent speaker at AWS events and the AWS user group Munich that he co-founded in 2014.
Picking the right tools or services for a job is a huge challenge in IT—every day and in every kind of business. With this post, I want to share some strategies and examples that we at Team Internet used to leverage the huge “tool box” of AWS to build better solutions and solve problems more efficiently.
Use existing resources or build something new? A hard decision
The usual day-to-day work of an IT engineer, architect, or developer is building a solution for a problem or transferring a business process into software. To achieve this, we usually tend to use already existing architectures or resources and build an “add-on” to it.
With the rise of microservices, we all learned that modularization and decoupling are important for being scalable and extendable. This brought us to a different type of software architecture. In reality, we still tend to use already existing resources, like the same database of existing (maybe not fully used) Amazon EC2 instances, because it seems easier than building up new stuff.
Stacks as “next level microservices”?
We at Team Internet are not using the vocabulary of microservices but tend to speak about stacks and building blocks for the different use cases. Our approach is matching the idea of microservices to everything, including the database and other resources that are necessary for the specific problem we need to address.
It’s not about “just” dividing the software and code into different modules. The whole infrastructure is separated based on different needs. Each of those parts of the full architecture is our stack, which is as independent as possible from everything else in the whole system. It only communicates loosely with the other stacks or parts of the infrastructure.
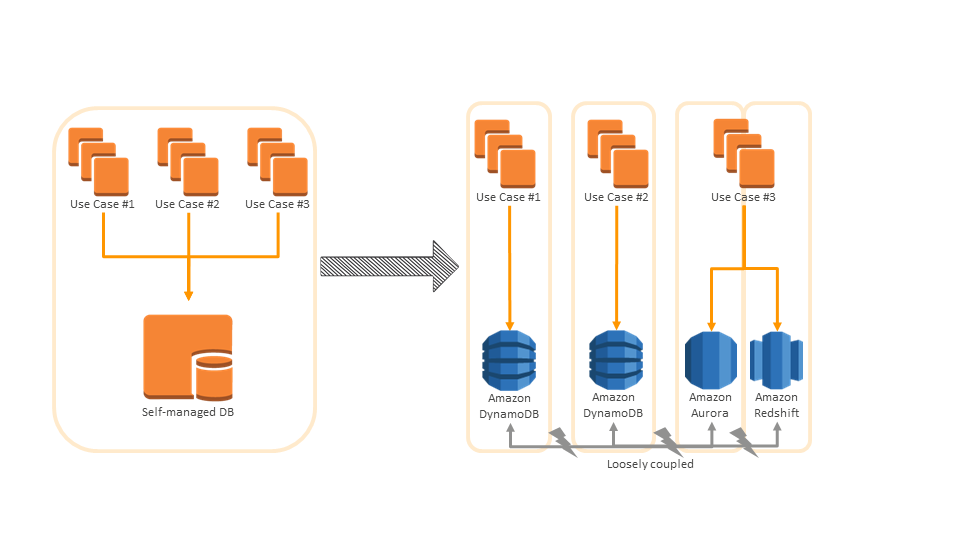
Benefits of this mindset = independence and flexibility
- Choosing the right parts. For every use case, we can choose the components or services that are best suited for the specific challenges and don’t need to work around limitations. This is especially true for databases, as we can choose from the whole palette instead of trying to squeeze requirements into a DBMS that isn’t built for that. We can differentiate the different needs of workloads like write-heavy vs. read-heavy or structured vs. unstructured data.
- Rebuilding at will. We’re flexible in rebuilding whole stacks as they’re only loosely coupled. Because of this, a team can build a proof-of-concept with new ideas or services and run them in parallel on production workload without interfering or harming the production system.
- Lowering costs. Because the operational overhead of running multiple resources is done by AWS (“No undifferentiated heavy lifting”), we just need to look at the service pricing. Most of the price schemes at AWS are supporting the stacks. For databases, you either pay for throughput (Amazon DynamoDB) or per instance (Amazon RDS, etc.). On the throughput level, it’s simple as you just split the throughput you did on one table to several tables without any overhead. On the instance level, the pricing is linear so that an r4.xlarge is half the price of an r4.2xlarge. So why not run two r4.xlarge and split the workload?
- Designing for resilience. This approach also helps your architecture to be more reliable and resilient by default. As the different stacks are independent from each other, the scaling is much more granular. Scaling on larger systems is often provided with a higher “security buffer,” and failures (hardware, software, fat fingers, etc.) only happen on a small part of the whole system.
- Taking ownership. A nice side effect we’re seeing now as we use this methodology is the positive effect on ownership and responsibility for our teams. Because of those stacks, it is easier to pinpoint and fix issues but also to be transparent and clear on who is responsible for which stack.
Benefits demand efforts, even with the right tool for the job
Every approach has its downsides. Here, it is obviously the additional development and architecture effort that needs to be taken to build such systems.
Therefore, we decided to always have the goal of a perfect system with independent stacks and reliable and loosely coupled processes between them in our mind. In reality, we sometimes break our own rules and cheat here and there. Even if we do, to have this approach helps us to build better systems and at least know exactly at what point we take a risk of losing the benefits. I hope the explanation and insights here help you to pick the right tool for the job.



Source: AWS News