Amazon EC2 Trn1 Instances for High-Performance Model Training are Now Available
Deep learning (DL) models have been increasing in size and complexity over the last few years, pushing the time to train from days to weeks. Training large language models the size of GPT-3 can take months, leading to an exponential growth in training cost. To reduce model training times and enable machine learning (ML) practitioners to iterate fast, AWS has been innovating across chips, servers, and data center connectivity.
At AWS re:Invent 2021, we announced the preview of Amazon EC2 Trn1 instances powered by AWS Trainium chips. AWS Trainium is optimized for high-performance deep learning training and is the second-generation ML chip built by AWS, following AWS Inferentia.
Today, I’m excited to announce that Amazon EC2 Trn1 instances are now generally available! These instances are well-suited for large-scale distributed training of complex DL models across a broad set of applications, such as natural language processing, image recognition, and more.
Compared to Amazon EC2 P4d instances, Trn1 instances deliver 1.4x the teraFLOPS for BF16 data types, 2.5x more teraFLOPS for TF32 data types, 5x the teraFLOPS for FP32 data types, 4x inter-node network bandwidth, and up to 50 percent cost-to-train savings. Trn1 instances can be deployed in EC2 UltraClusters that serve as powerful supercomputers to rapidly train complex deep learning models. I’ll share more details on EC2 UltraClusters later in this blog post.
New Trn1 Instance Highlights
Trn1 instances are available today in two sizes and are powered by up to 16 AWS Trainium chips with 128 vCPUs. They provide high-performance networking and storage to support efficient data and model parallelism, popular strategies for distributed training.
Trn1 instances offer up to 512 GB of high-bandwidth memory, deliver up to 3.4 petaFLOPS of TF32/FP16/BF16 compute power, and feature an ultra-high-speed NeuronLink interconnect between chips. NeuronLink helps avoid communication bottlenecks when scaling workloads across multiple Trainium chips.
Trn1 instances are also the first EC2 instances to enable up to 800 Gbps of Elastic Fabric Adapter (EFA) network bandwidth for high-throughput network communication. This second generation EFA delivers lower latency and up to 2x more network bandwidth compared to the previous generation. Trn1 instances also come with up to 8 TB of local NVMe SSD storage for ultra-fast access to large datasets.
The following table lists the sizes and specs of Trn1 instances in detail.
| Instance Name |
vCPUs | AWS Trainium Chips | Accelerator Memory | NeuronLink | Instance Memory | Instance Networking | Local Instance Storage |
| trn1.2xlarge | 8 | 1 | 32 GB | N/A | 32 GB | Up to 12.5 Gbps | 1x 500 GB NVMe |
| trn1.32xlarge | 128 | 16 | 512 GB | Supported | 512 GB | 800 Gbps | 4x 2 TB NVMe |
Trn1 EC2 UltraClusters
For large-scale model training, Trn1 instances integrate with Amazon FSx for Lustre high-performance storage and are deployed in EC2 UltraClusters. EC2 UltraClusters are hyperscale clusters interconnected with a non-blocking petabit-scale network. This gives you on-demand access to a supercomputer to cut model training time for large and complex models from months to weeks or even days.
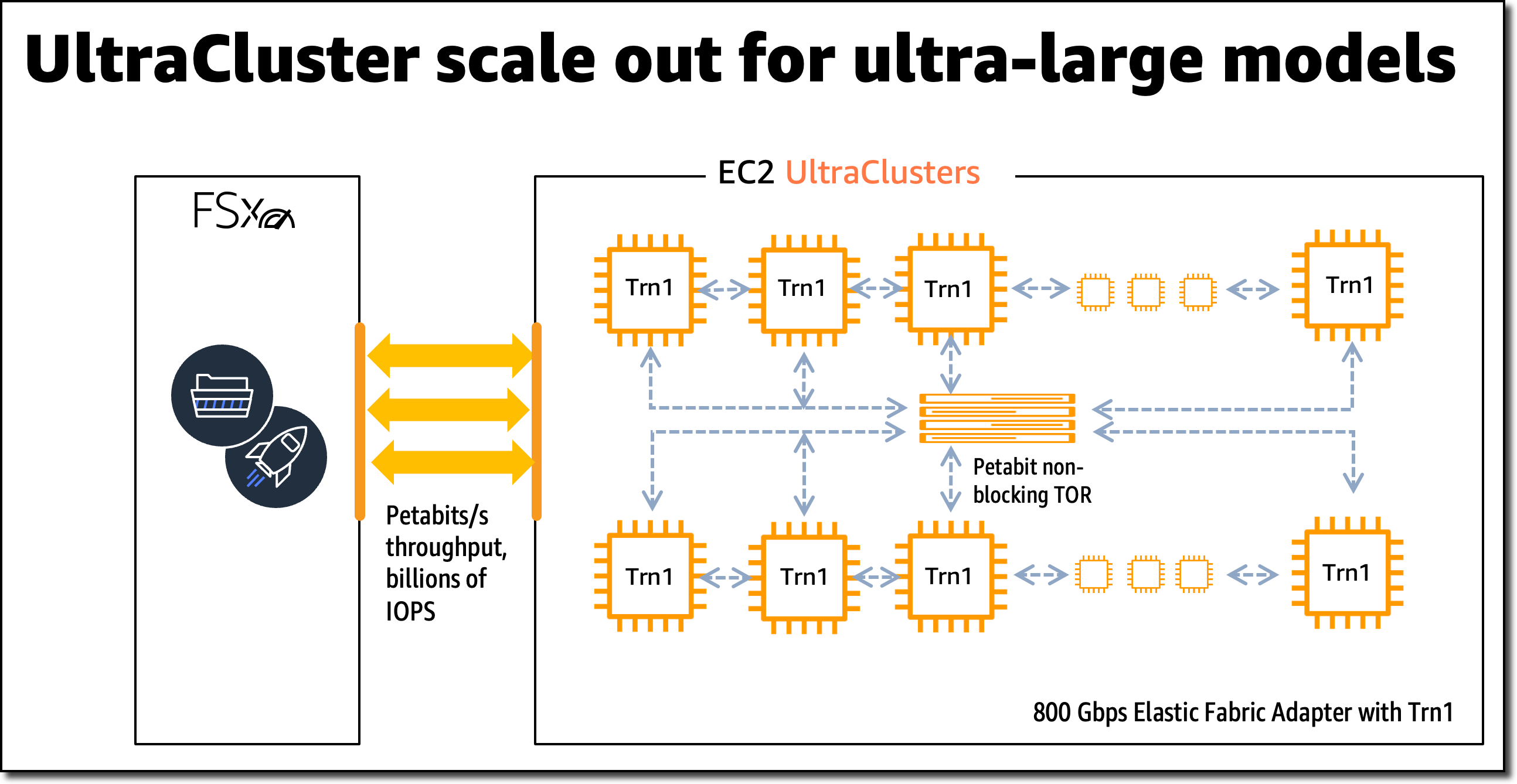
AWS Trainium Innovation
AWS Trainium chips include specific scalar, vector, and tensor engines that are purpose-built for deep learning algorithms. This ensures higher chip utilization as compared to other architectures, resulting in higher performance.
Here is a short summary of additional hardware innovations:
- Data Types: AWS Trainium supports a wide range of data types, including FP32, TF32, BF16, FP16, and UINT8, so you can choose the most suitable data type for your workloads. It also supports a new, configurable FP8 (cFP8) data type, which is especially relevant for large models because it reduces the memory footprint and I/O requirements of the model.
- Hardware-Optimized Stochastic Rounding: Stochastic rounding achieves close to FP32-level accuracy with faster BF16-level performance when you enable auto-casting from FP32 to BF16 data types. Stochastic rounding is a different way of rounding floating-point numbers, which is more suitable for machine learning workloads versus the commonly used Round Nearest Even rounding. By setting the environment variable
NEURON_RT_STOCHASTIC_ROUNDING_EN=1to use stochastic rounding, you can train a model up to 30 percent faster. - Custom Operators, Dynamic Tensor Shapes: AWS Trainium also supports custom operators written in C++ and dynamic tensor shapes. Dynamic tensor shapes are key for models with unknown input tensor sizes, such as models processing text.
AWS Trainium shares the same AWS Neuron SDK as AWS Inferentia, making it easy for everyone who is already using AWS Inferentia to get started with AWS Trainium.
For model training, the Neuron SDK consists of a compiler, framework extensions, a runtime library, and developer tools. The Neuron plugin natively integrates with popular ML frameworks, such as PyTorch and TensorFlow.
The AWS Neuron SDK supports just-in-time (JIT) compilation, in addition to ahead-of-time (AOT) compilation, to speed up model compilation, and Eager Debug Mode, for a step-by-step execution.
To compile and run your model on AWS Trainium, you need to change only a few lines of code in your training script. You don’t need to tweak your model or think about data type conversion.
Get Started with Trn1 Instances
In this example, I train a PyTorch model on an EC2 Trn1 instance using the available PyTorch Neuron packages. PyTorch Neuron is based on the PyTorch XLA software package and enables conversion of PyTorch operations to AWS Trainium instructions.
Each AWS Trainium chip includes two NeuronCore accelerators, which are the main neural network compute units. With only a few changes to your training code, you can train your PyTorch model on AWS Trainium NeuronCores.
SSH into the Trn1 instance and activate a Python virtual environment that includes the PyTorch Neuron packages. If you’re using a Neuron-provided AMI, you can activate the preinstalled environment by running the following command:
source aws_neuron_venv_pytorch_p36/bin/activateBefore you can run your training script, you need to make a few modifications. On Trn1 instances, the default XLA device should be mapped to a NeuronCore.
Let’s start by adding the PyTorch XLA imports to your training script:
import torch, torch_xla
import torch_xla.core.xla_model as xmThen, place your model and tensors onto an XLA device:
model.to(xm.xla_device())
tensor.to(xm.xla_device())When the model is moved to the XLA device (NeuronCore), subsequent operations on the model are recorded for later execution. This is XLA’s lazy execution which is different from PyTorch’s eager execution. Within the training loop, you have to mark the graph to be optimized and run on the XLA device using xm.mark_step(). Without this mark, XLA cannot determine where the graph ends.
...
for data, target in train_loader:
output = model(data)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
xm.mark_step()
...You can now run your training script using torchrun <my_training_script>.py.
When running the training script, you can configure the number of NeuronCores to use for training by using torchrun –nproc_per_node.
For example, to run a multi-worker data parallel model training on all 32 NeuronCores in one trn1.32xlarge instance, run torchrun --nproc_per_node=32 <my_training_script>.py.
Data parallel is a strategy for distributed training that allows you to replicate your script across multiple workers, with each worker processing a portion of the training dataset. The workers then share their result with each other.
For more details on supported ML frameworks, model types, and how to prepare your model training script for large-scale distributed training across trn1.32xlarge instances, have a look at the AWS Neuron SDK documentation.
Profiling Tools
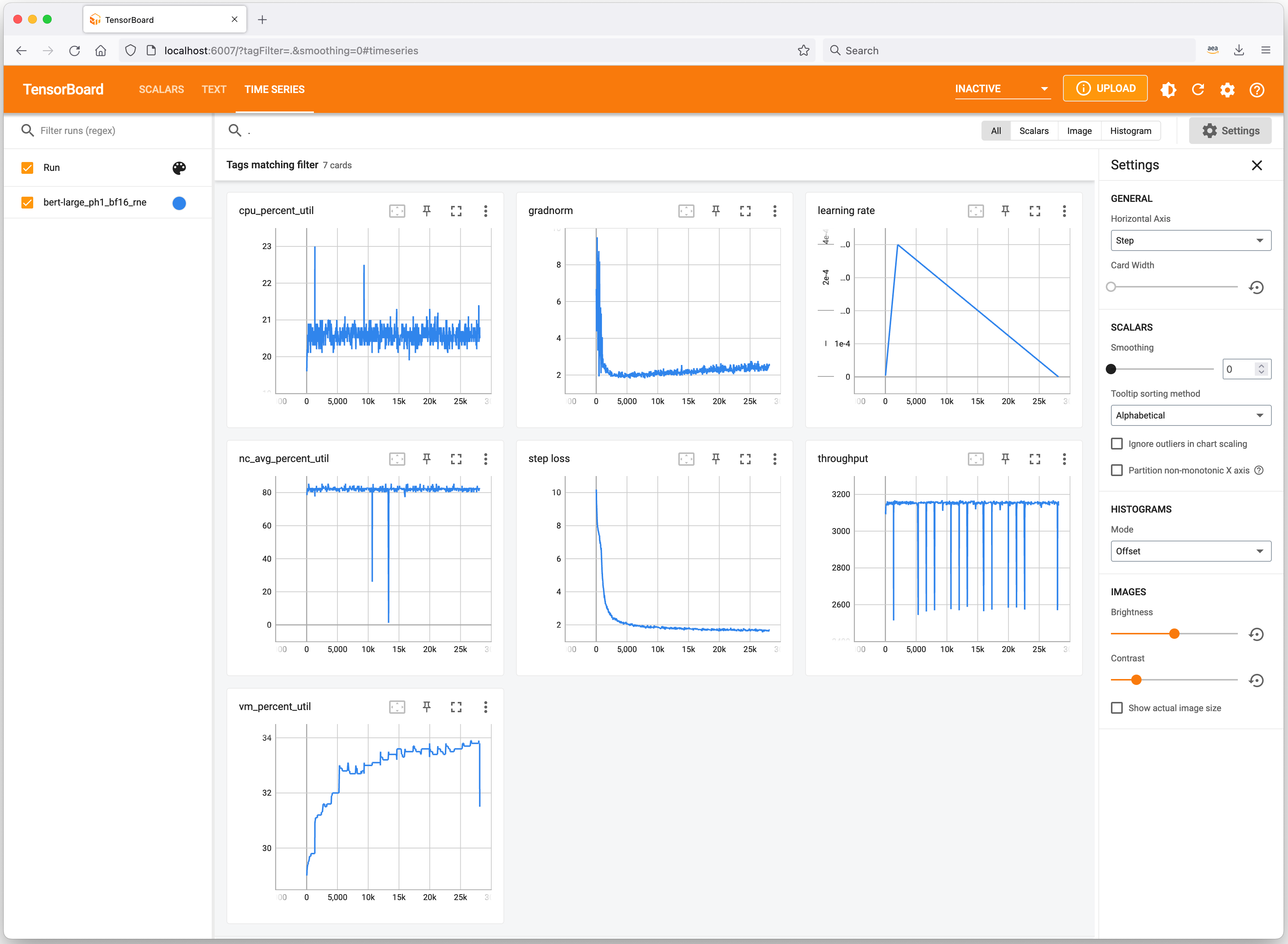
Let’s have a quick look at useful tools to keep track of your ML experiments and profile Trn1 instance resource consumption. Neuron integrates with TensorBoard to track and visualize your model training metrics.
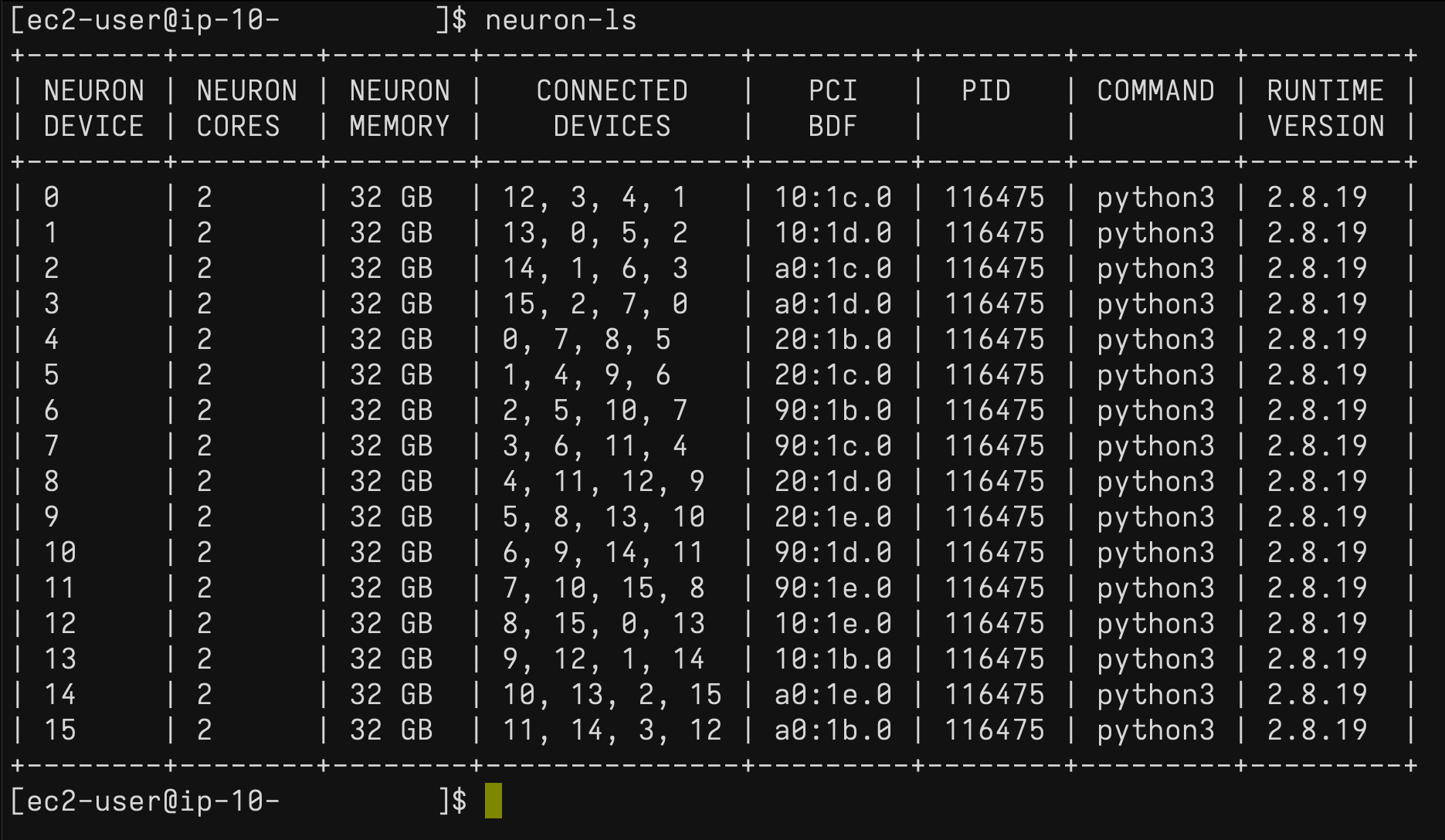
On the Trn1 instance, you can use the neuron-ls command to describe the number of Neuron devices present in the system, along with the associated NeuronCore count, memory, connectivity/topology, PCI device information, and the Python process that currently has ownership of the NeuronCores:
Similarly, you can use the neuron-top command to see a high-level view of the Neuron environment. This shows the utilization of each of the NeuronCores, any models that are currently loaded onto one or more NeuronCores, process IDs for any processes that are using the Neuron runtime, and basic system statistics relating to vCPU and memory usage.

Available Now
You can launch Trn1 instances today in the AWS US East (N. Virginia) and US West (Oregon) Regions as On-Demand, Reserved, and Spot Instances or as part of a Savings Plan. As usual with Amazon EC2, you pay only for what you use. For more information, see Amazon EC2 pricing.
Trn1 instances can be deployed using AWS Deep Learning AMIs, and container images are available via managed services such as Amazon SageMaker, Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Elastic Container Service (Amazon ECS), and AWS ParallelCluster.
To learn more, visit our Amazon EC2 Trn1 instances page, and please send feedback to AWS re:Post for EC2 or through your usual AWS Support contacts.
— Antje
Source: AWS News