Amazon Managed Streaming for Apache Kafka (MSK) – Now Generally Available
I am always amazed at how our customers are using streaming data. For example, Thomson Reuters, one of the world’s most trusted news organizations for businesses and professionals, built a solution to capture, analyze, and visualize analytics data to help product teams continuously improve the user experience. Supercell, the social game company providing games such as Hay Day, Clash of Clans, and Boom Beach, is delivering in-game data in real-time, handling 45 billion events per day.
Since we launched Amazon Kinesis at re:Invent 2013, we have continually expanded the ways in in which customers work with streaming data on AWS. Some of the available tools are:
- Kinesis Data Streams, to capture, store, and process data streams with your own applications.
- Kinesis Data Firehose, to transform and collect data into destinations such as Amazon S3, Amazon Elasticsearch Service, and Amazon Redshift.
- Kinesis Data Analytics, to continuously analyze data using SQL or Java (via Apache Flink applications), for example to detect anomalies or for time series aggregation.
- Kinesis Video Streams, to simplify processing of media streams.
At re:Invent 2018, we introduced in open preview Amazon Managed Streaming for Apache Kafka (MSK), a fully managed service that makes it easy to build and run applications that use Apache Kafka to process streaming data.
I am excited to announce that Amazon MSK is generally available today!
How it works
Apache Kafka (Kafka) is an open-source platform that enables customers to capture streaming data like click stream events, transactions, IoT events, application and machine logs, and have applications that perform real-time analytics, run continuous transformations, and distribute this data to data lakes and databases in real time. You can use Kafka as a streaming data store to decouple applications producing streaming data (producers) from those consuming streaming data (consumers).
While Kafka is a popular enterprise data streaming and messaging framework, it can be difficult to setup, scale, and manage in production. Amazon MSK takes care of these managing tasks and makes it easy to set up, configure, and run Kafka, along with Apache ZooKeeper, in an environment following best practices for high availability and security.
Your MSK clusters always run within an Amazon VPC managed by the MSK service. Your MSK resources are made available to your own VPC, subnet, and security group through elastic network interfaces (ENIs) which will appear in your account, as described in the following architectural diagram:
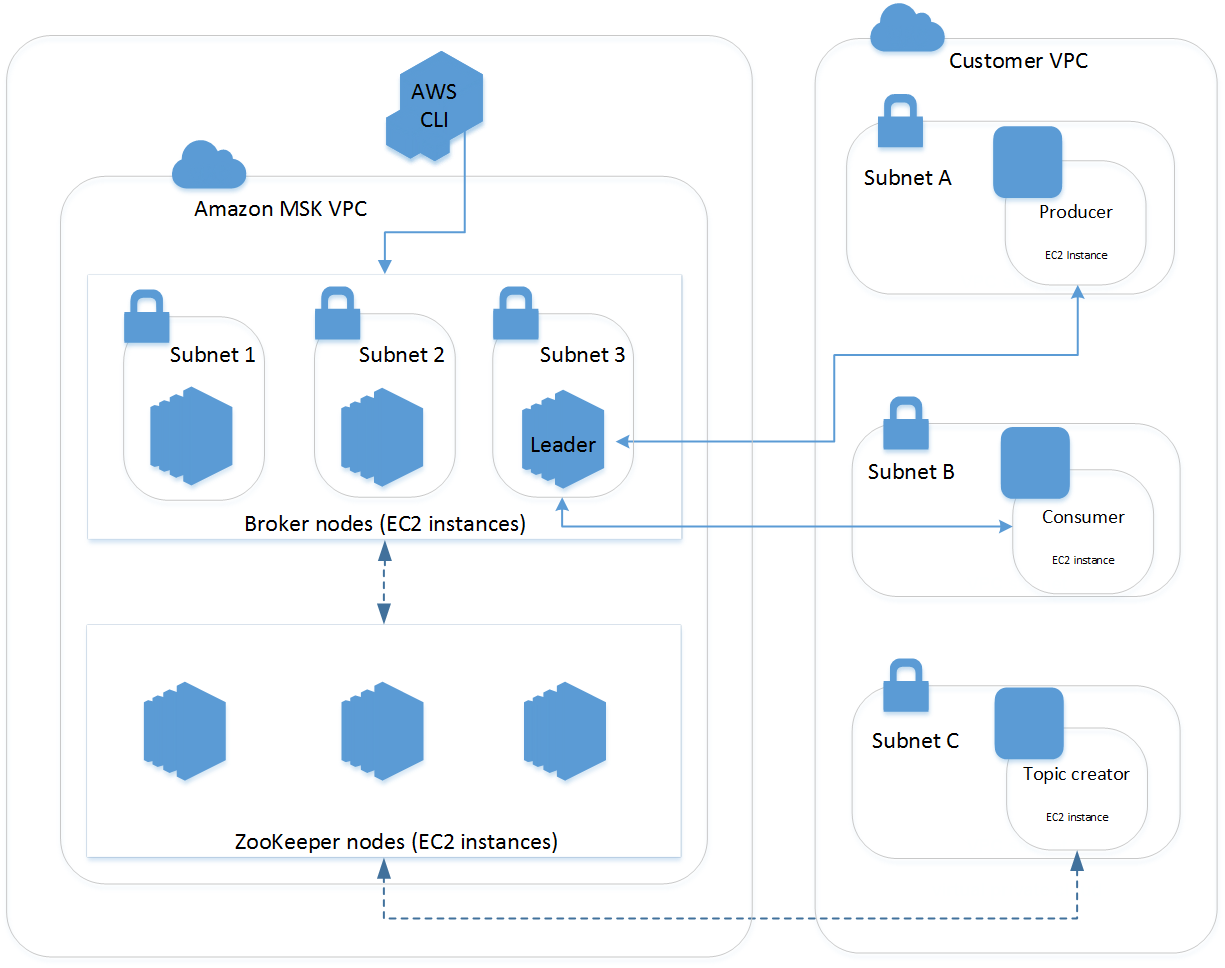
Customers can create a cluster in minutes, use AWS Identity and Access Management (IAM) to control cluster actions, authorize clients using TLS private certificate authorities fully managed by AWS Certificate Manager (ACM), encrypt data in-transit using TLS, and encrypt data at rest using AWS Key Management Service (KMS) encryption keys.
Amazon MSK continuously monitors server health and automatically replaces servers when they fail, automates server patching, and operates highly available ZooKeeper nodes as a part of the service at no additional cost. Key Kafka performance metrics are published in the console and in Amazon CloudWatch. Amazon MSK is fully compatible with Kafka versions 1.1.1 and 2.1.0, so that you can continue to run your applications, use Kafka’s admin tools, and and use Kafka compatible tools and frameworks without having to change your code.
Based on our customer feedback during the open preview, Amazon MSK added may features such as:
- Encryption in-transit via TLS between clients and brokers, and between brokers
- Mutual TLS authentication using ACM private certificate authorities
- Support for Kafka version 2.1.0
- 99.9% availability SLA
- HIPAA eligible
- Cluster-wide storage scale up
- Integration with AWS CloudTrail for MSK API logging
- Cluster tagging and tag-based IAM policy application
- Defining custom, cluster-wide configurations for topics and brokers
AWS CloudFormation support is coming in the next few weeks.
Creating a cluster
Let’s create a cluster using the AWS management console. I give the cluster a name, select the VPC I want to use the cluster from, and the Kafka version.

I then choose the Availability Zones (AZs) and the corresponding subnets to use in the VPC. In the next step, I select how many Kafka brokers to deploy in each AZ. More brokers allow you to scale the throughtput of a cluster by allocating partitions to different brokers.

I can add tags to search and filter my resources, apply IAM policies to the Amazon MSK API, and track my costs. For storage, I leave the default storage volume size per broker.
I select to use encryption within the cluster and to allow both TLS and plaintext traffic between clients and brokers. For data at rest, I use the AWS-managed customer master key (CMK), but you can select a CMK in your account, using KMS, to have further control. You can use private TLS certificates to authenticate the identity of clients that connect to your cluster. This feature is using Private Certificate Authorities (CA) from ACM. For now, I leave this option unchecked.

In the advanced setting, I leave the default values. For example, I could have chosen here a different instance type for my brokers. Some of these settings can be updated using the AWS CLI.
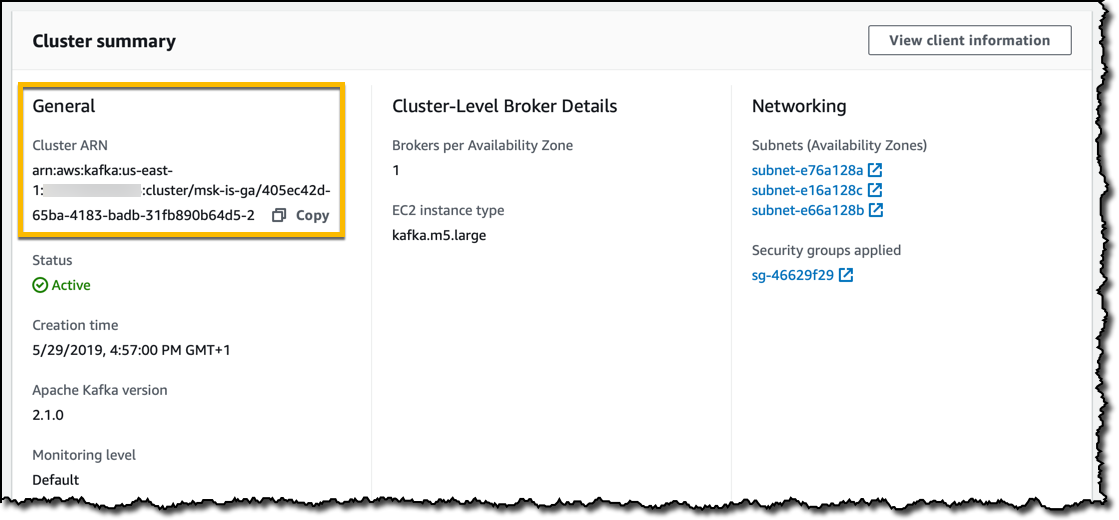
I create the cluster and monitor the status from the cluster summary, including the Amazon Resource Name (ARN) that I can use when interacting via CLI or SDKs.
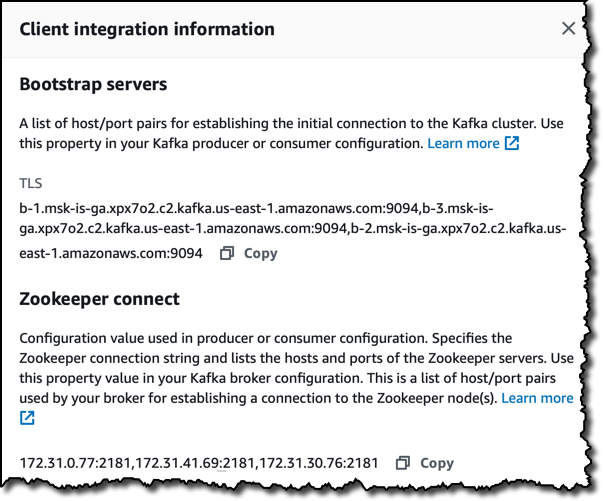
When the status is active, the client information section provides specific details to connect to the cluster, such as:
- The bootstrap servers I can use with Kafka tools to connect to the cluster.
- The Zookeper connect list of hosts and ports.
I can get similar information using the AWS CLI:
aws kafka list-clustersto see the ARNs of your clusters in a specific regionaws kafka get-bootstrap-brokers --cluster-arn <ClusterArn>to get the Kafka bootstrap serversaws kafka describe-cluster --cluster-arn <ClusterArn>to see more details on the cluster, including the Zookeeper connect string
Quick demo of using Kafka
To start using Kafka, I create two EC2 instances in the same VPC, one will be a producer and one a consumer. To set them up as client machines, I download and extract the Kafka tools from the Apache website or any mirror. Kafka requires Java 8 to run, so I install Amazon Corretto 8.
On the producer instance, in the Kafka directory, I create a topic to send data from the producer to the consumer:
bin/kafka-topics.sh --create --zookeeper <ZookeeperConnectString>
--replication-factor 3 --partitions 1 --topic MyTopic
Then I start a console-based producer:
bin/kafka-console-producer.sh --broker-list <BootstrapBrokerString>
--topic MyTopic
On the consumer instance, in the Kafka directory, I start a console-based consumer:
bin/kafka-console-consumer.sh --bootstrap-server <BootstrapBrokerString>
--topic MyTopic --from-beginning
Here’s a recording of a quick demo where I create the topic and then send messages from a producer (top terminal) to a consumer of that topic (bottom terminal):

Pricing and availability
Pricing is per Kafka broker-hour and per provisioned storage-hour. There is no cost for the Zookeeper nodes used by your clusters. AWS data transfer rates apply for data transfer in and out of MSK. You will not be charged for data transfer within the cluster in a region, including data transfer between brokers and data transfer between brokers and ZooKeeper nodes.
You can migrate your existing Kafka cluster to MSK using tools like MirrorMaker (that comes with open source Kafka) to replicate data from your clusters into a MSK cluster.
Upstream compatibility is a core tenet of Amazon MSK. Our code changes to the Kafka platform are released back to open source.
Amazon MSK is available in US East (N. Virginia), US East (Ohio), US West (Oregon), Asia Pacific (Tokyo), Asia Pacific (Singapore), Asia Pacific (Sydney), EU (Frankfurt), EU (Ireland), EU (Paris), and EU (London).
I look forward to see how are you going to use Amazon MSK to simplify building and migrating streaming applications to the cloud!



Source: AWS News