Amazon S3 Update – Three New Security & Access Control Features
A year or so after we launched Amazon S3, I was in an elevator at a tech conference and heard a couple of developers use “just throw it into S3” as the answer to their data storage challenge. I remember that moment well because the comment was made so casually, and it was one of the first times that I fully grasped just how quickly S3 had caught on.
Since that launch, we have added hundreds of features and multiple storage classes to S3, while also reducing the cost to storage a gigabyte of data for a month by almost 85% (from $0.15 to $0.023 for S3 Standard, and as low as $0.00099 for S3 Glacier Deep Archive). Today, our customers use S3 to support many different use cases including data lakes, backup and restore, disaster recovery, archiving, and cloud-native applications.
Security & Access Control
As the set of use cases for S3 has expanded, our customers have asked us for new ways to regulate access to their mission-critical buckets and objects. We added IAM policies many years ago, and Block Public Access in 2018. Last year we added S3 Access Points (Easily Manage Shared Data Sets with Amazon S3 Access Points) to help you manage access in large-scale environments that might encompass hundreds of applications and petabytes of storage.
Today we are launching S3 Object Ownership as a follow-on to two other S3 security & access control features that we launched earlier this month. All three features are designed to give you even more control and flexibility:
Object Ownership – You can now ensure that newly created objects within a bucket have the same owner as the bucket.
Bucket Owner Condition – You can now confirm the ownership of a bucket when you create a new object or perform other S3 operations.
Copy API via Access Points – You can now access S3’s Copy API through an Access Point.
You can use all of these new features in all AWS regions at no additional charge. Let’s take a look at each one!
Object Ownership
With the proper permissions in place, S3 already allows multiple AWS accounts to upload objects to the same bucket, with each account retaining ownership and control over the objects. This many-to-one upload model can be handy when using a bucket as a data lake or another type of data repository. Internal teams or external partners can all contribute to the creation of large-scale centralized resources. With this model, the bucket owner does not have full control over the objects in the bucket and cannot use bucket policies to share objects, which can lead to confusion.
You can now use a new per-bucket setting to enforce uniform object ownership within a bucket. This will simplify many applications, and will obviate the need for the Lambda-powered self-COPY that has become a popular way to do this up until now. Because this setting changes the behavior seen by the account that is uploading, the PUT request must include the bucket-owner-full-control ACL. You can also choose to use a bucket policy that requires the inclusion of this ACL.
To get started, open the S3 Console, locate the bucket and view its Permissions, click Object Ownership, and Edit:
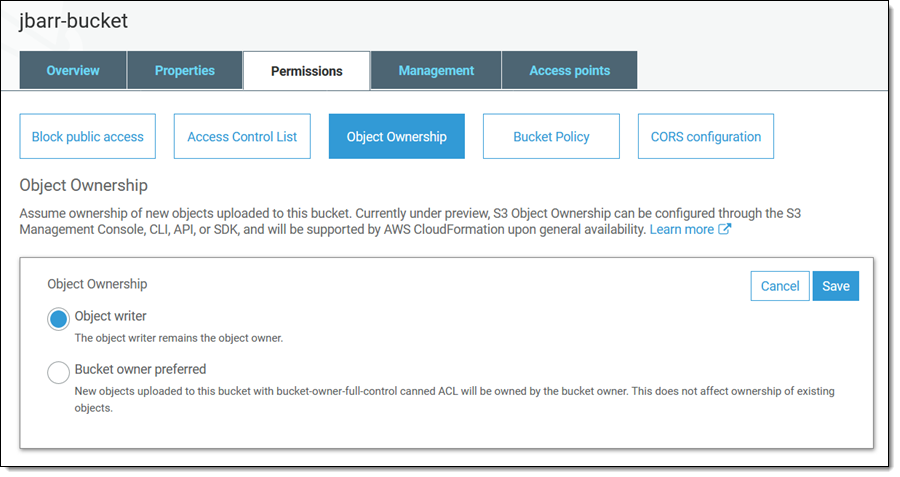
Then select Bucket owner preferred and click Save:
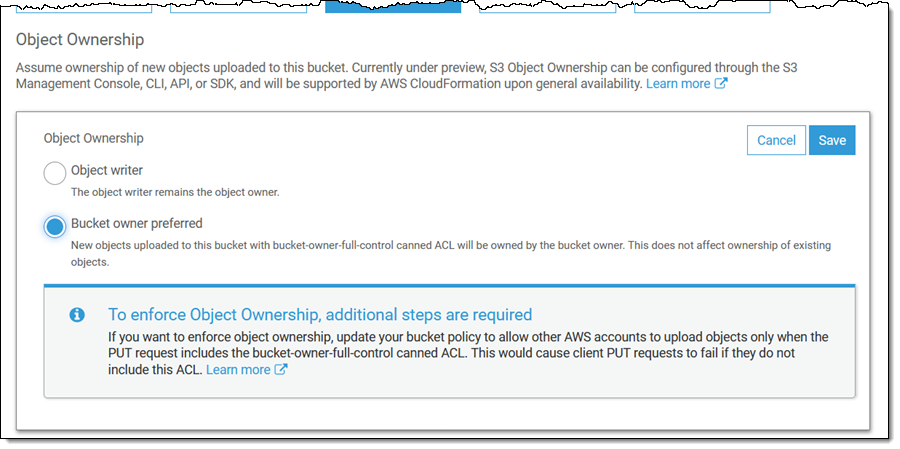
As I mentioned earlier, you can use a bucket policy to enforce object ownership (read About Object Ownership and this Knowledge Center Article to learn more).
Many AWS services deliver data to the bucket of your choice, and are now equipped to take advantage of this feature. S3 Server Access Logging, S3 Inventory, S3 Storage Class Analysis, AWS CloudTrail, and AWS Config now deliver data that you own. You can also configure Amazon EMR to use this feature by setting fs.s3.canned.acl to BucketOwnerFullControl in the cluster configuration (learn more).
Keep in mind that this feature does not change the ownership of existing objects. Also, note that you will now own more S3 objects than before, which may cause changes to the numbers you see in your reports and other metrics.
AWS CloudFormation support for Object Ownership is under development and is expected to be ready before AWS re:Invent.
Bucket Owner Condition
This feature lets you confirm that you are writing to a bucket that you own.
You simply pass a numeric AWS Account ID to any of the S3 Bucket or Object APIs using the expectedBucketOwner parameter or the x-amz-expected-bucket-owner HTTP header. The ID indicates the AWS Account that you believe owns the subject bucket. If there’s a match, then the request will proceed as normal. If not, it will fail with a 403 status code.
To learn more, read Bucket Owner Condition.
Copy API via Access Points
S3 Access Points give you fine-grained control over access to your shared data sets. Instead of managing a single and possibly complex policy on a bucket, you can create an access point for each application, and then use an IAM policy to regulate the S3 operations that are made via the access point (read Easily Manage Shared Data Sets with Amazon S3 Access Points to see how they work).
You can now use S3 Access Points in conjunction with the S3 CopyObject API by using the ARN of the access point instead of the bucket name (read Using Access Points to learn more).
Use Them Today
As I mentioned earlier, you can use all of these new features in all AWS regions at no additional charge.
— Jeff;



Source: AWS News