AWS Ground Station – Ready to Ingest & Process Satellite Data
Last fall I told you about AWS Ground Station and gave you a sneak preview of the steps that you would take to downlink data from a satellite. I am happy to report that the first two ground stations are now in operation, and that you can start using AWS Ground Station today.
Using AWS Ground Station
As I noted at the time, the first step is to Add satellites to your AWS account by sharing the satellite’s NORAD ID and other information with us:
The on-boarding process generally takes a couple of days. For testing purposes, the Ground Station team added three satellites to my account:
- Terra (NORAD ID 25994) – This satellite was launched in 1999 and orbits at an altitude of 705 km. It carries five sensors that are designed to study the Earth’s surface.
- Aqua (NORAD ID 27424) – This satellite was launched in 2002 and also orbits at an altitude of 705 km. It carries six sensors that are designed to study surface water.
- NOAA-20 (NORAD ID 43013) – This satellite was launched in 2017 and orbits at an altitude of 825 km. It carries five sensors that observe both land and water.
While the on-boarding process is under way, the next step is to choose the ground station that you will use to receive your data. This is dependent on the path your satellite takes as it orbits the Earth and the time at which you want to receive data. Our first two ground stations are located in Oregon and Ohio, with other locations under construction. Each ground station is associated with an adjacent AWS region and you need to set up your AWS infrastructure in that region ahead of time.
I’m going to use the US East (Ohio) Region for this blog post. Following the directions in the AWS Ground Station User Guide, I use a CloudFormation template to set up my infrastructure within my VPC:
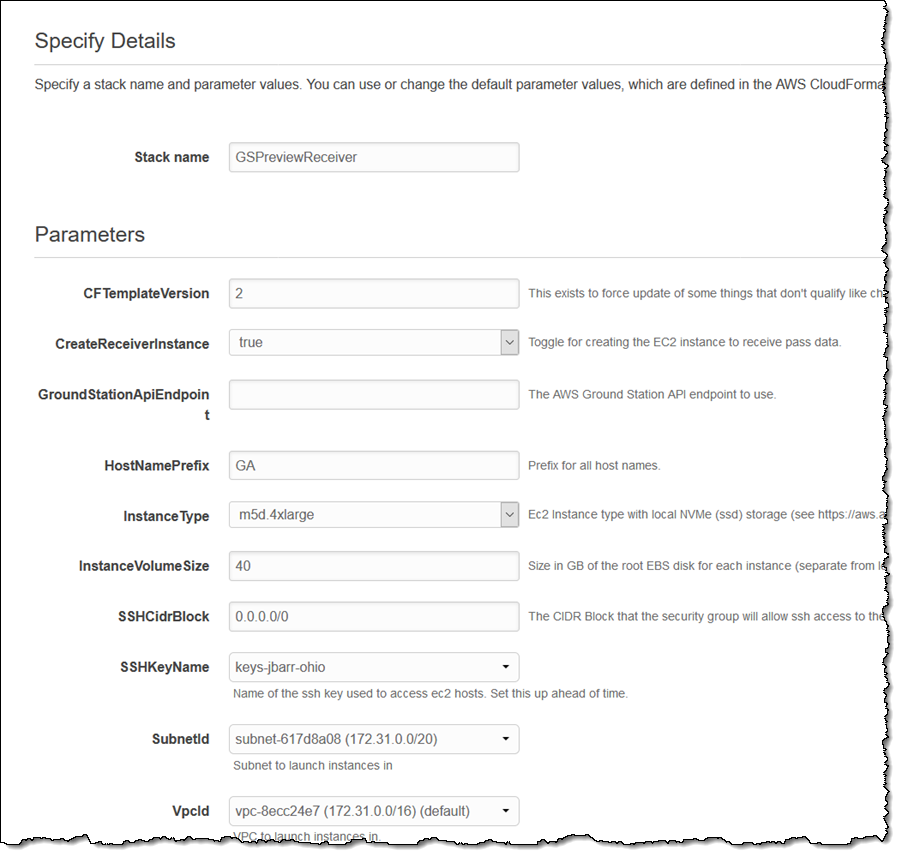
The stack includes an EC2 instance, three Elastic Network Interfaces (ENIs), and the necessary IAM roles, EC2 security groups, and so forth:
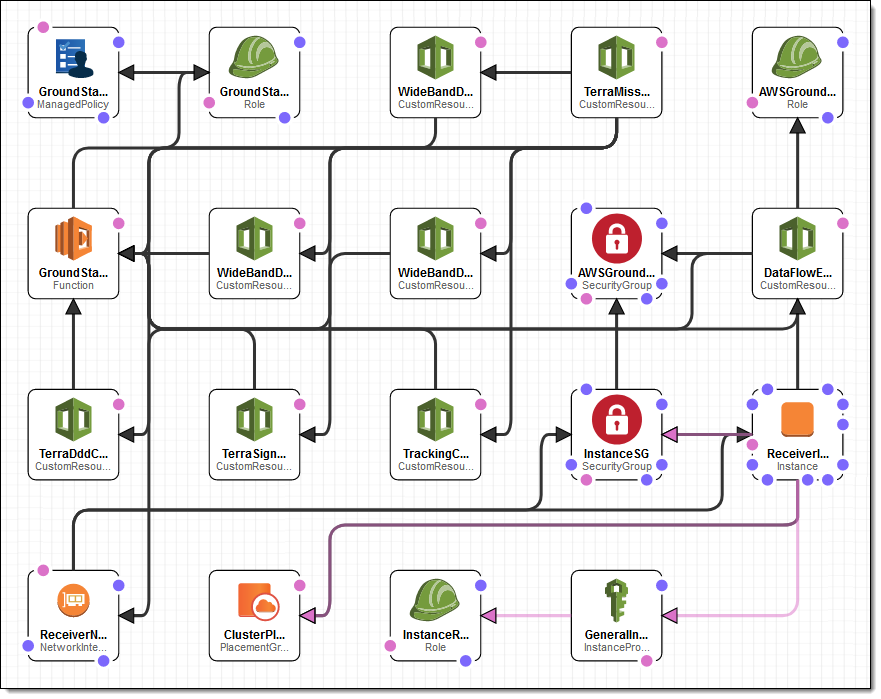
The EC2 instance hosts Kratos DataDefender (a lossless UDP transport mechanism). I can also use the instance to host the code that processes the incoming data stream. DataDefender makes the incoming data stream available on a Unix domain socket at port 55892. My code is responsible for reading the raw data, splitting it in to packets, and then processing each packet.
You can also create one or more Mission Profiles. Each profile outlines the timing requirements for a contact, lists the resources needed for the contact, and defines how data flows during the contact. You can use the same Mission Profile for multiple satellites, and you can also use different profiles (as part of distinct contacts) for the same satellite.
Scheduling a Contact
With my satellite configured and my AWS infrastructure in place, I am ready to schedule a contact! I open the Ground Station Console, make sure that I am in the AWS Region that corresponds to the ground station that I want to use, and click Contacts. I review the list of upcoming contacts, select the desired one (If you are not accustomed to thinking in Zulu time, a World Clock / Converter is helpful), and click Reserve contact:
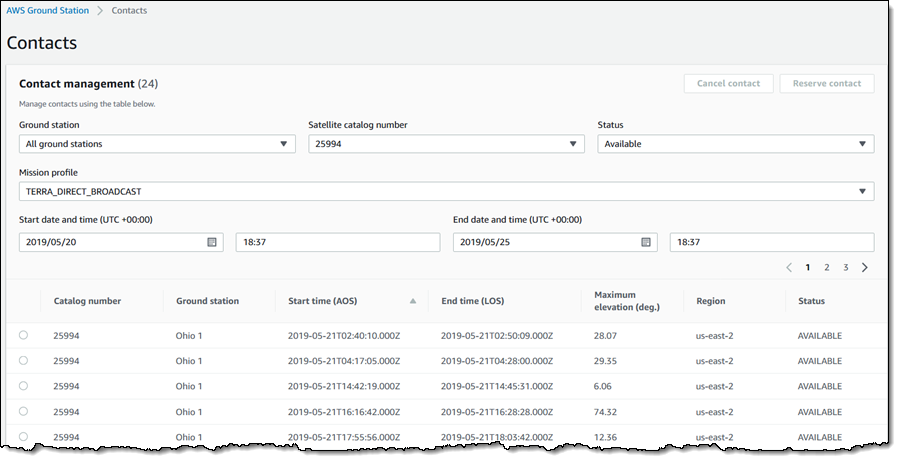
Then I confirm my intent by clicking Reserve:
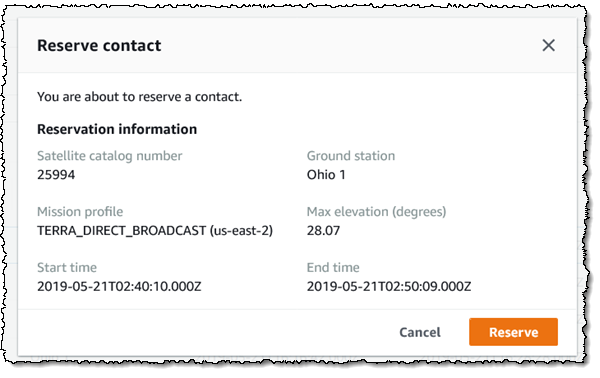
The status of the connection goes to SCHEDULING and then to SCHEDULED, all within a minute or so:
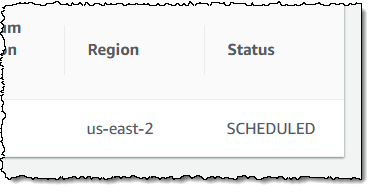
The next step is to wait for the satellite to come within range of the chosen ground station. During this time, I can connect to the EC2 instance in two ways:
SSH – I can SSH to the instance’s IP address, verify that my code is in place and ready to run, and confirm that DataDefender is running:

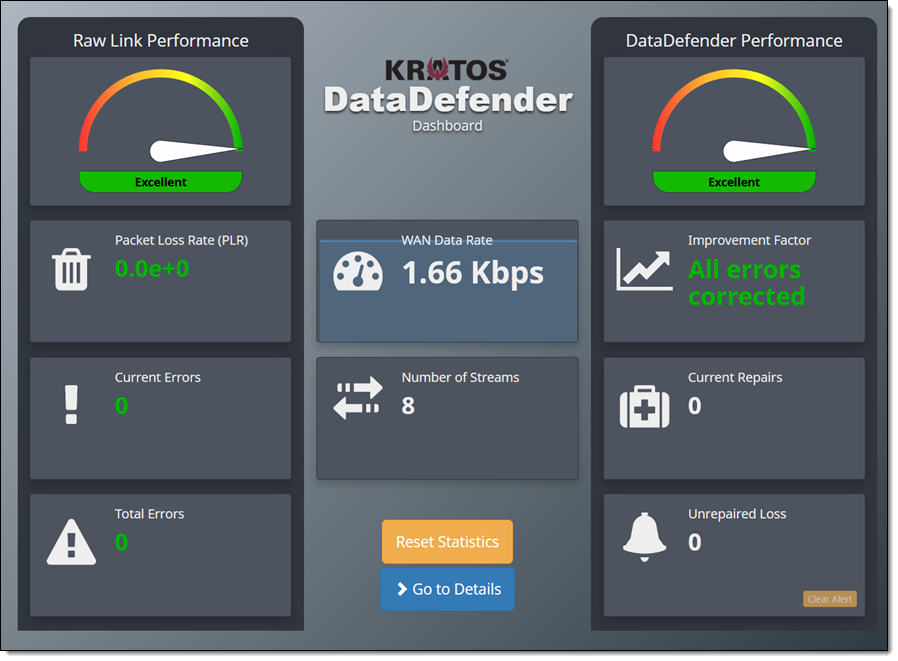
WEB – I can open up a web browser and see the DataDefender web interface:
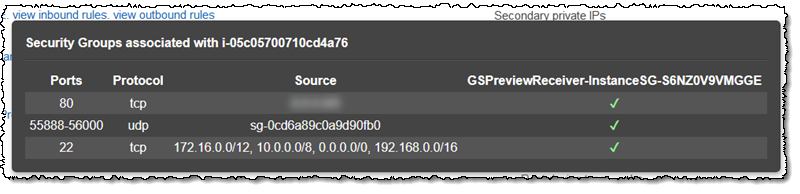
One thing to note: you may need to edit the security group attached to the instance in order to allow it to be accessed from outside of the VPC:
3-2-1 Contact!
Ok, now I need to wait for Terra to come within range of the ground station that I selected. While not necessary, it can be fun (and educational) to use a real-time satellite tracker such as the one at n2yo.com:
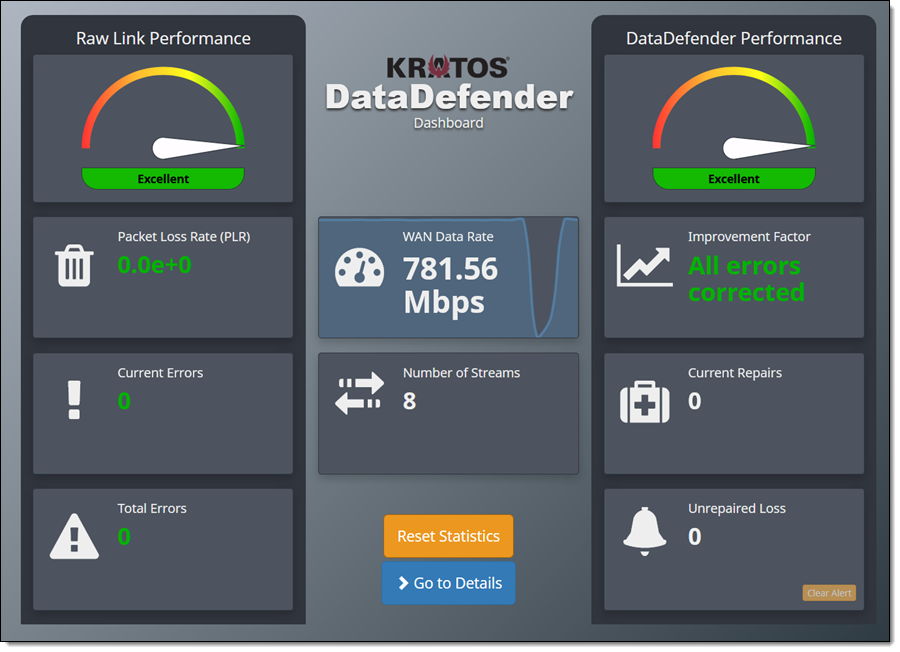
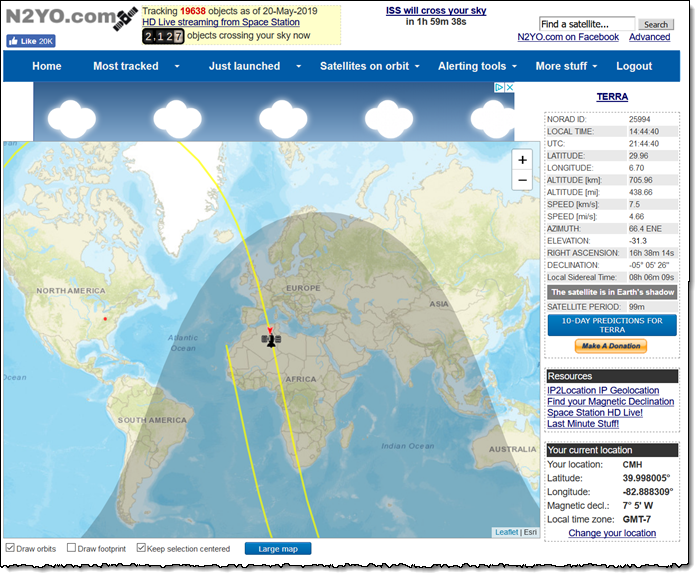 When my satellite comes in to range, DataDefender shows me that the data transfer is under way (at an impressive 781 Mbps), as indicated by the increased WAN Data Rate:
When my satellite comes in to range, DataDefender shows me that the data transfer is under way (at an impressive 781 Mbps), as indicated by the increased WAN Data Rate:
As I noted earlier, the incoming data stream is available within the instance in real time on a Unix domain socket. After my code takes care of all immediate, low-level processing, it can route the data to Amazon Kinesis Data Streams for real-time processing, store it in Amazon S3 for safe-keeping or further analysis, and so forth.
Customer Perspective – Spire
 While I was writing this blog post I spoke with Robert Sproles, a Program Manager with AWS customer Spire to learn about their adoption of Ground Station. Spire provides data & analytics from orbit, and runs the space program behind it. They design and build their own cubesats in-house, and currently have about 70 in orbit. Collectively, the satellites have more sensors than any of Spire’s competitors, and collect maritime, aviation, and weather data.
While I was writing this blog post I spoke with Robert Sproles, a Program Manager with AWS customer Spire to learn about their adoption of Ground Station. Spire provides data & analytics from orbit, and runs the space program behind it. They design and build their own cubesats in-house, and currently have about 70 in orbit. Collectively, the satellites have more sensors than any of Spire’s competitors, and collect maritime, aviation, and weather data.
Although Spire already operates a network of 30 ground stations, they were among the first to see the value of (and to start using) AWS Ground Station. In addition to being able to shift from a CapEx (capital expense) to OpEx (operating expense) model, Ground Station gives them the ability to collect fresh data more quickly, with the goal of making it available to their customers even more rapidly. Spire’s customers are wide-ranging and global, but can all benefit from rapid access to high-quality data. Their LEMUR (Low Earth Multi-Use Receiver) satellites go around the globe every 90 minutes, but this is a relatively long time when the data is related to aviation or weather. Robert told me that they can counter this by adding additional satellites in the same orbit or by making use of additional ground stations, all with the goal of reducing latency and delivering the freshest possible data.
Spire applies machine learning to the raw data, with the goal of going from a “lump of data” to actionable insights. For example, they use ML to make predictions about the future positions of cargo ships, using a combination of weather and historical data. The predicted ship positions can be used to schedule dock slots and other scarce resources ahead of time.
Now Available
You can get started with AWS Ground Station today. We have two ground stations in operation, with ten more in the works and planned for later this year.
— Jeff;



Source: AWS News