Cross-Account Data Sharing for Amazon Redshift
To be successful in today’s fast-moving world, businesses need to analyze data quickly and take meaningful action. Many of our customers embrace this concept to become data-driven organizations.
Data-driven organizations treat data as an asset and use it to improve their insights and make better decisions. They unleash the power of data by using secure systems to collect, store, and process data and share it with people in their organization. Some even offer their data and analytics as a service, to their customers, partners, and external parties to create new revenue streams.
All stakeholders want to share and consume the same accurate data as a single source of truth. They want to be able to query live views of the data concurrently while experiencing no performance degradation and access the right information exactly when it’s needed.
Amazon Redshift, the first data warehouse built for the cloud, has become popular as the data warehouse component of many of our customers’ data architecture.
Amazon Redshift users can share data with users in an AWS account, but to share and collaborate on data with other AWS accounts, they needed to extract it from one system and load it into another.
There is a lot of manual work involved in building and maintaining the different extract, transform, and load jobs required to make this work. As your data sharing scales and more stakeholders need data, the complexity increases. As a result, it can become hard to maintain the monitoring, compliance, and security best practices required to keep your data safe.
This way of sharing does not provide complete and up-to-date views of the data, either, because the manual processes introduce delays and data inconsistencies that result in stale data, lower-quality business results, and slow responses to customers.
That’s why we created cross-account data sharing for Amazon Redshift.
Introducing Cross-Account Data Sharing for Amazon Redshift
This new feature gives you a simple and secure way to share fresh, complete, and consistent data in your Amazon Redshift data warehouse with any number of stakeholders across AWS accounts. It makes it possible for you to share data across organizations and collaborate with external parties while meeting compliance and security requirements.
Amazon Redshift offers comprehensive security controls and auditing capabilities using IAM integration, system tables and AWS CloudTrail. These allow customers to control and monitor data sharing permissions and usage across consumers and revoke access instantly when necessary.
You can share data at many levels, including databases, schemas, tables, views, columns, and user-defined functions, to provide fine-grained access controls tailored to users and businesses who need access to Amazon Redshift data.
Let’s take a look at how cross-account data sharing works.
Sharing Data Across Two Accounts
Cross-account data sharing is a two-step process. First, a producer cluster administrator creates a datashare, adds objects, and gives access to the consumer account. Second, the producer account administrator authorizes sharing data for the specified consumer. You can do this from the Amazon Redshift console.
To get started, in the Amazon Redshift console, I create an Amazon Redshift cluster and then import some sample data. When the cluster is available, I navigate to the cluster details page, choose the Datashares tab, and then choose Create datashare.
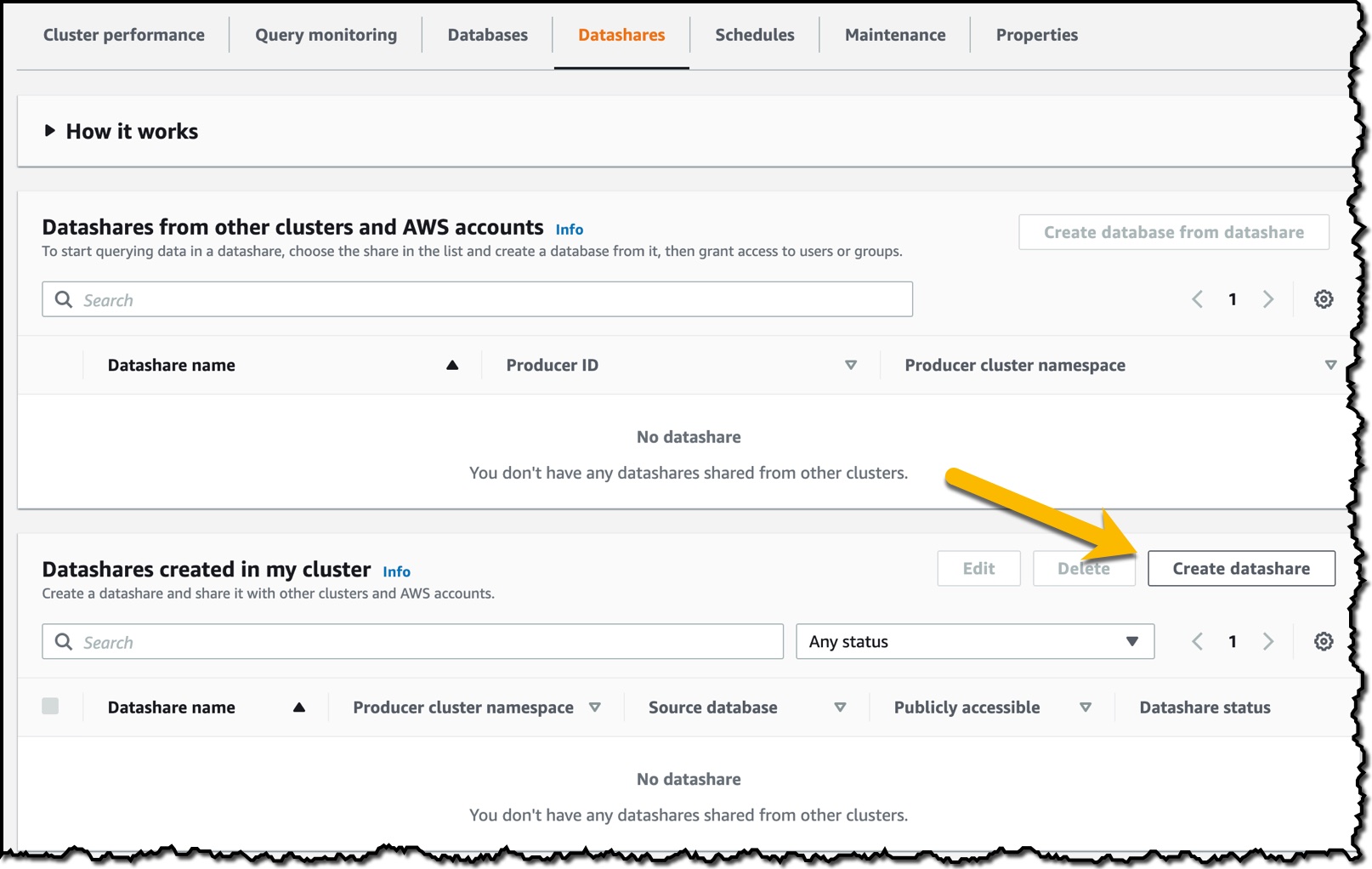
On the Create datashare page, I enter a datashare name and then choose a database. Under Publicly accessible, I choose Enable because I want the datashare to be shared with publicly accessible clusters.
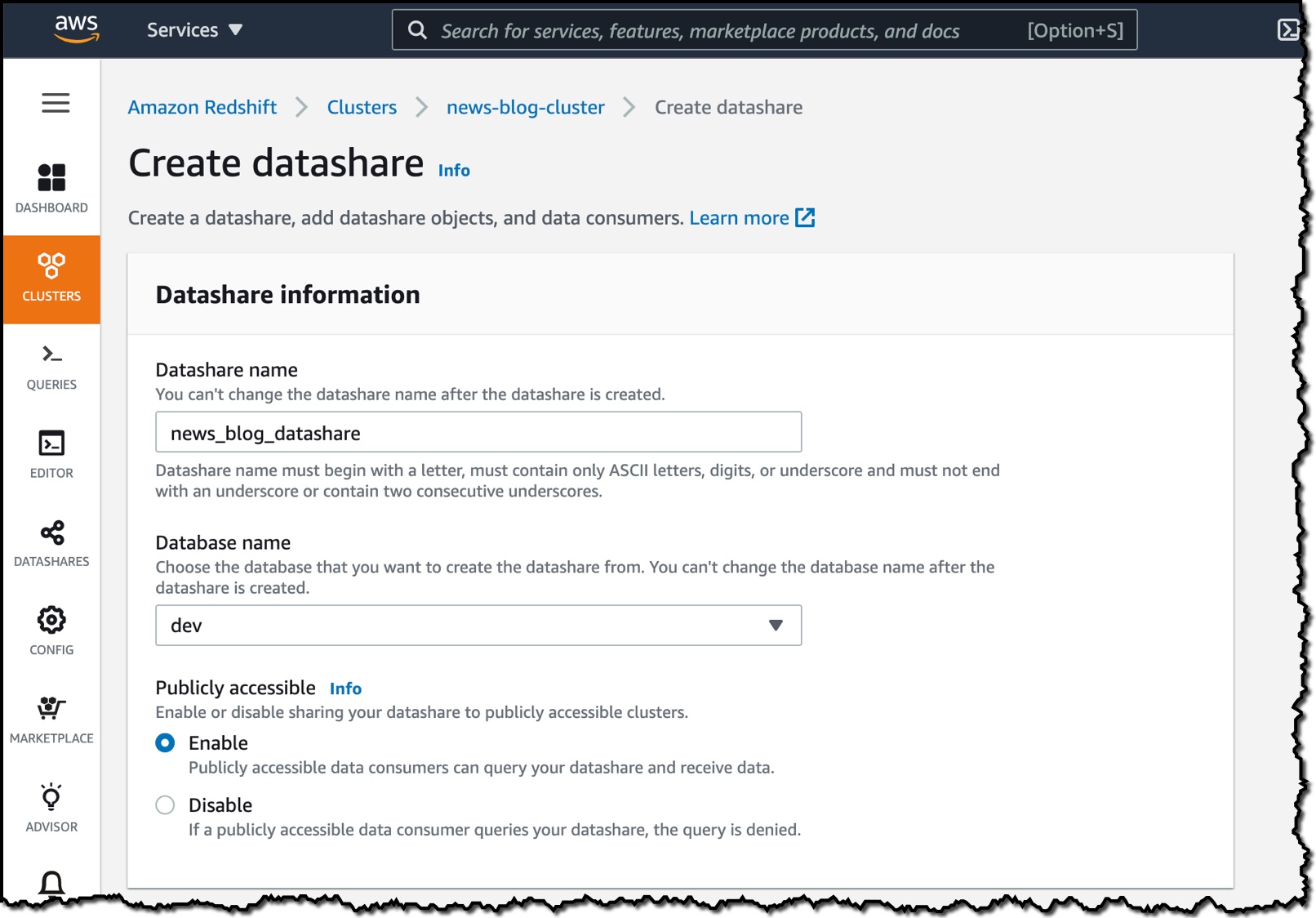
I then choose the objects from the database I want to include in the datashare. I have granular control of what I choose to share with others. For simplicity, I will share all the tables. In practice, though, you might choose one or more tables, views, or user-defined functions.
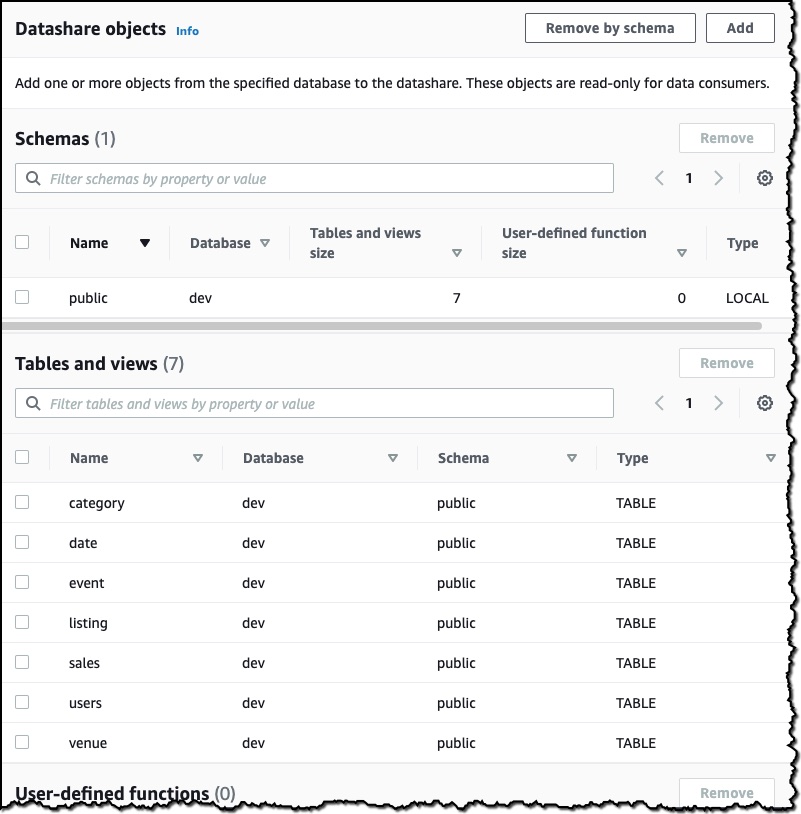
The last thing I need to do is add an AWS account to the datashare. I add my second AWS account ID and then choose Create datashare.

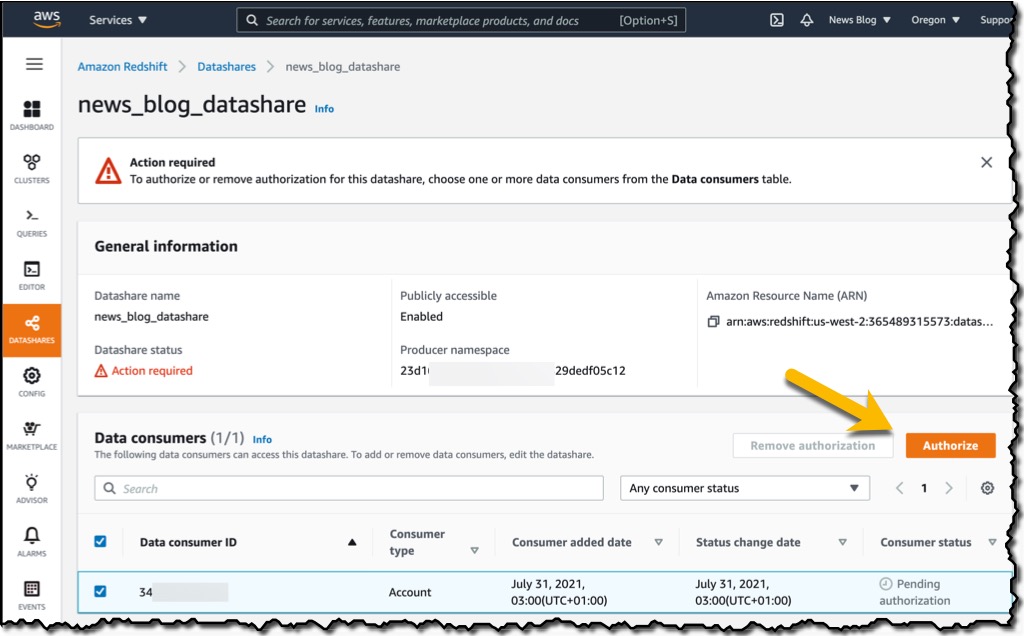
To authorize the data consumer I just created, in the Datashares section of the console, I choose Authorize. The Consumer status will change from Pending authorization to Authorized. Now that the datashare is set up, I’ll switch to my secondary account to show you how to consume the datashare in the consumer AWS account. It’s important to note that I need to use the same Region in the secondary account, as cross-account data sharing does not work across Regions.
Similar to the producer, there is a process for consuming data. First, you need to associate the data share with one or more clusters in the consumer account. You can also associate the data share to the entire consumer account so that the current and future clusters in the consumer account get access to the share.
I sign in to my secondary account and go to the Datashares section of the console. I choose the From other accounts tab and then select the news_blog_datashare that I shared from the producer AWS account. I then choose Associate to associate the datashare with a cluster in my account.
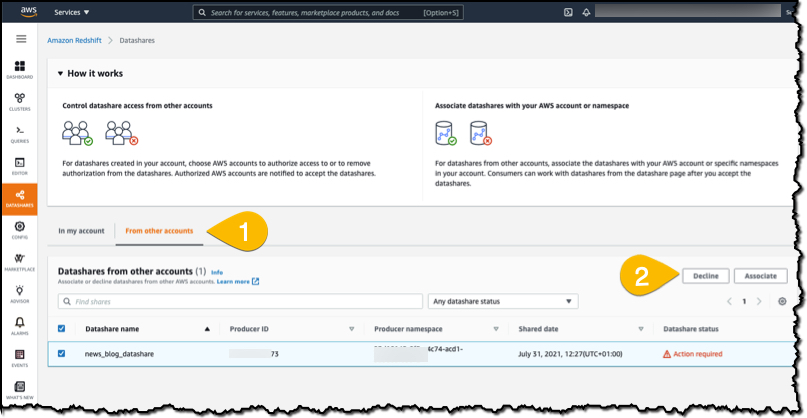
On the details page of the cluster, I choose Create database from datashare and then enter a name for my new database.

In the query editor, I select my database and run queries against all the objects that have been made available as part of the datashare.
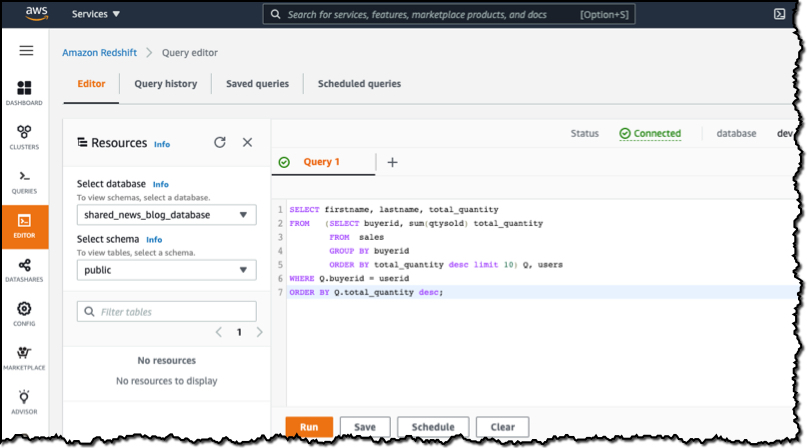
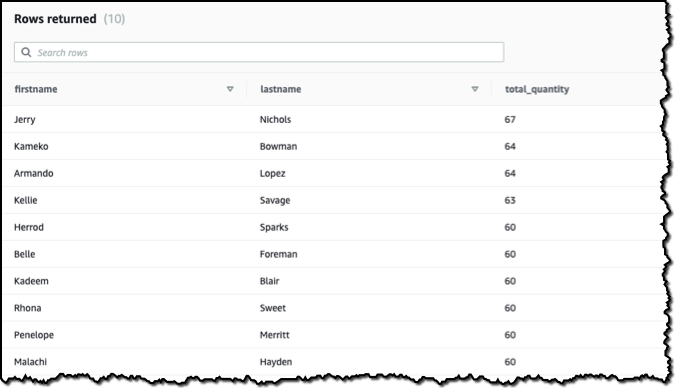
When I choose Run, data is returned from the query. What’s important to remember is that this is a live view of the data. Any changes in the producer database will be reflected in my queries. No copying or manual transfers are required.
Things to Know
Here are a couple of interesting facts about cross-account data sharing:
Security – All of the permissions required for authorization and association are managed with AWS Identity and Access Management (IAM), so you can create IAM policies to control which operations each user can complete. For security considerations, see Controlling access for cross-account datashares.
Encryption – Both the producer and consumer clusters must be encrypted and in the same AWS Region.
Regions – Cross-account data sharing is available for all Amazon Redshift RA3 node types in US East (N. Virginia), US East (Ohio), US West (N. California), US West (Oregon), Asia Pacific (Mumbai), Asia Pacific (Seoul), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Canada (Central), Europe (Frankfurt), Europe (Ireland), Europe (London), Europe (Paris), Europe (Stockholm), and South America (São Paulo).
Pricing – Cross-account data sharing is available across clusters that are in the same Region. There is no cost to share data. Customers just pay for the Redshift clusters that participate in sharing.
Try Cross-Account Data Sharing for Amazon Redshift today.
This new feature is available right now so why not create a cluster and take cross-account data sharing for a spin? For information about how to get started, see Sharing data across AWS accounts. Don’t forget to let me know how you get on.
Happy sharing!



Source: AWS News