New – Accelerate Your Lambda Functions with Lambda SnapStart
Our customers tell me that they love AWS Lambda for many reasons. On the development side they appreciate the simple programming model and ease with which their functions can make use of other AWS services. On the operations side they benefit from the ability to build powerful applications that can respond quickly to changing usage patterns.
As you might know if you are already using Lambda, your functions are run inside of a secure and isolated execution environment. The lifecycle of each environment consists of three main phases: Init, Invoke, and Shutdown. Among other things, the Init phase bootstraps the runtime for the function and runs the function’s static code. In many cases, these operations are completed within milliseconds and do not lengthen the phase in any appreciable way. In the remaining cases, they can take a considerable amount of time, for several reasons. First, initializing the runtime for some languages can be expensive. For example, the Init phase for a Lambda function that uses one of the Java runtimes in conjunction with a framework such as Spring Boot, Quarkus, or Micronaut can sometimes take as long as ten seconds (this includes dependency injection, compilation of the code for the function, and classpath component scanning). Second, the static code might download some machine learning models, pre-compute some reference data, or establish network connections to other AWS services.
Introducing Lambda SnapStart
In order to allow you to put Lambda to use in even more ways, we are introducing Lambda SnapStart today.
After you enable Lambda SnapStart for a particular Lambda function, publishing a new version of the function will trigger an optimization process. The process launches your function and runs it through the entire Init phase. Then it takes an immutable, encrypted snapshot of the memory and disk state, and caches it for reuse. When the function is subsequently invoked, the state is retrieved from the cache in chunks on an as-needed basis and used to populate the execution environment. This optimization makes invocation time faster and more predictable, since creating a fresh execution environment no longer requires a dedicated Init phase.
We are launching with support for Java functions that make use of the Corretto (java11) runtime, and expect to see Lambda SnapStart put to use right away for applications that make use of Spring Boot, Quarkus, Micronaut, and other Java frameworks. Enabling Lambda SnapStart for Java functions can make them start up to 10x faster, at no extra cost.
Using Lambda SnapStart
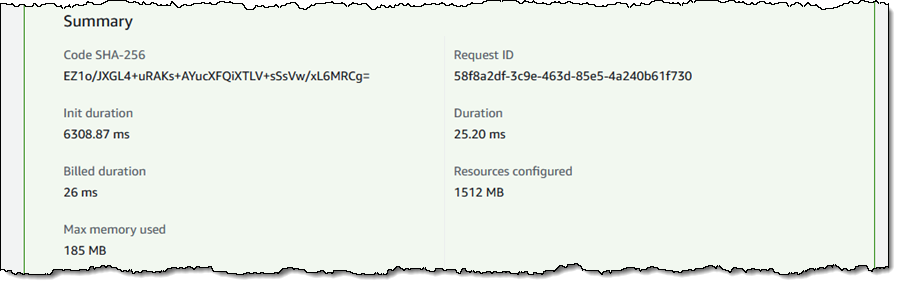
Because my last actual encounter with Java took place in the last century, I used the Serverless Spring Boot 2 example from the AWS Labs repo as a starting point. I installed the AWS SAM CLI and did a test build & deploy to establish a baseline. I invoked the function and saw that the Init duration was slightly more than 6 seconds:
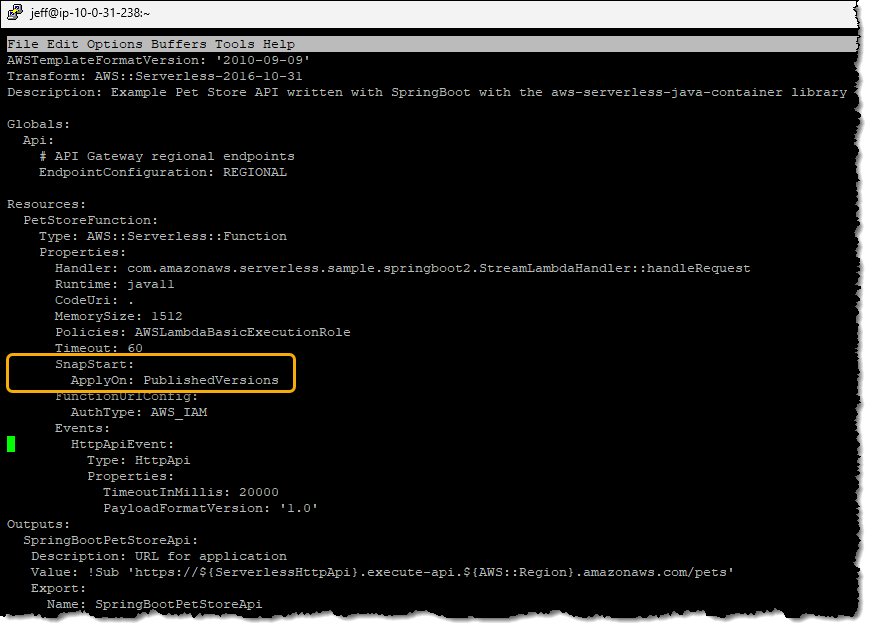
Then I added two lines to template.yml to configure the SnapStart property:
I rebuilt and redeployed, published a fresh version of the function to set up SnapStart, and ran another test:
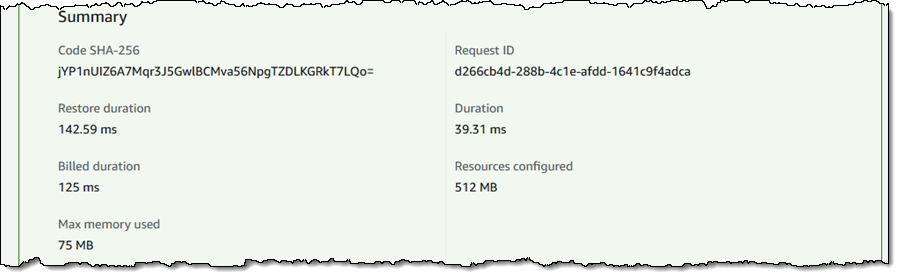
With SnapStart, the initialization phase (represented by the Init duration that I showed you earlier) happens when I publish a new version of the function. When I invoke a function that has SnapStart enabled, Lambda restores the snapshot (represented by the Restore duration) before invoking the function handler. As a result, the total cold invoke with SnapStart is now Restore duration + Duration. SnapStart has reduced the cold start duration from over 6 seconds to less than 200 ms.
Becoming Snap-Resilient
Lambda SnapStart speeds up applications by reusing a single initialized snapshot to resume multiple execution environments. This has a few interesting implications for your code:
Uniqueness – When using SnapStart, any unique content that used to be generated during the initialization must now be generated after initialization in order to maintain uniqueness. If you (or a library that you reference) uses a pseudo-random number generator, it should not be based on a seed that is obtained during the Init phase. We have updated OpenSSL’s RAND_Bytes to ensure randomness when used in conjunction with SnapStart, and we have verified that java.security.SecureRandom is already snap-resilient. Amazon Linux’s /dev/random and /dev/urandom are also snap-resilient.
Network Connections -If your code creates long-term connections to network services during the Init phase and uses them during the Invoke phase, make sure that it can re-establish the connection if necessary. The AWS SDKs have already been updated to do this.
Ephemeral Data – This is effectively a more general form of the above items. If your code downloads or computes reference information during the Init phase, consider doing a quick check to make sure that it has not gone stale during the caching period.
Lambda provides a pair of runtime hooks to help you to maintain uniqueness, as well as a scanning tool to help detect possible issues.
Things to Know
Here are a couple of other things to know about Lambda SnapStart:
Caching – Cached snapshots are removed after 14 days of inactivity. Lambda will automatically refresh the cache if a snapshot depends on a runtime that has been updated or patched.
Pricing – There is no extra charge for the use of Lambda SnapStart.
Feature Compatibility – You cannot use Lambda SnapStart with larger ephemeral storage, Elastic File Systems, Provisioned Concurrency, or Graviton2. In general, we recommend using SnapStart for your general-purpose Lambda functions and Provisioned Concurrency for the subset of those functions that are exceptionally sensitive to latency.
Firecracker – This feature makes use of Firecracker Snapshotting.
Regions – Lambda SnapStart is available in the US East (Ohio, N. Virginia), US West (Oregon), Asia Pacific (Singapore, Sydney, Tokyo), and Europe (Frankfurt, Ireland, Stockholm) Regions.
— Jeff;
Source: AWS News