New Amazon S3 Storage Class – Glacier Deep Archive
Many AWS customers collect and store large volumes (often a petabyte or more) of important data but seldom access it. In some cases raw data is collected and immediately processed, then stored for years or decades just in case there’s a need for further processing or analysis. In other cases, the data is retained for compliance or auditing purposes. Here are some of the industries and use cases that fit this description:
Financial – Transaction archives, activity & audit logs, and communication logs.
Health Care / Life Sciences – Electronic medical records, images (X-Ray, MRI, or CT), genome sequences, records of pharmaceutical development.
Media & Entertainment – Media archives and raw production footage.
Physical Security – Raw camera footage.
Online Advertising – Clickstreams and ad delivery logs.
Transportation – Vehicle telemetry, video, RADAR, and LIDAR data.
Science / Research / Education – Research input and results, including data relevant to seismic tests for oil & gas exploration.
Today we are introducing a new and even more cost-effective way to store important, infrequently accessed data in Amazon S3.
Amazon S3 Glacier Deep Archive Storage Class
The new Glacier Deep Archive storage class is designed to provide durable and secure long-term storage for large amounts of data at a price that is competitive with off-premises tape archival services. Data is stored across 3 or more AWS Availability Zones and can be retrieved in 12 hours or less. You no longer need to deal with expensive and finicky tape drives, arrange for off-premises storage, or worry about migrating data to newer generations of media.
Your existing S3-compatible applications, tools, code, scripts, and lifecycle rules can all take advantage of Glacier Deep Archive storage. You can specify the new storage class when you upload objects, alter the storage class of existing objects manually or programmatically, or use lifecycle rules to arrange for migration based on object age. You can also make use of other S3 features such as Storage Class Analysis, Object Tagging, Object Lock, and Cross-Region Replication.
The existing S3 Glacier storage class allows you to access your data in minutes (using expedited retrieval) and is a good fit for data that requires faster access. To learn more about the entire range of options, read Storage Classes in the S3 Developer Guide. If you are already making use of the Glacier storage class and rarely access your data, you can switch to Deep Archive and begin to see cost savings right away.
Using Glacier Deep Archive Storage – Console
I can switch the storage class of an existing S3 object to Glacier Deep Archive using the S3 Console. I locate the file and click Properties:
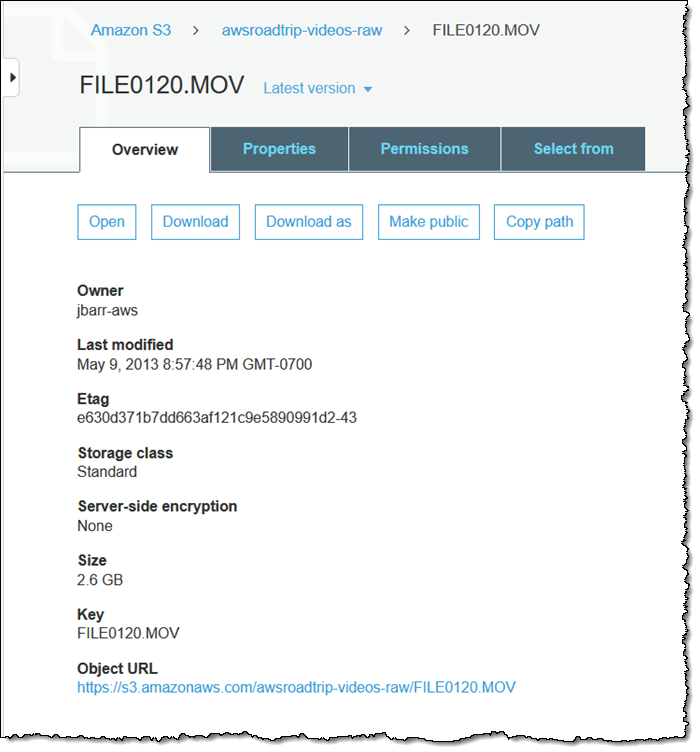
Then I click Storage class:
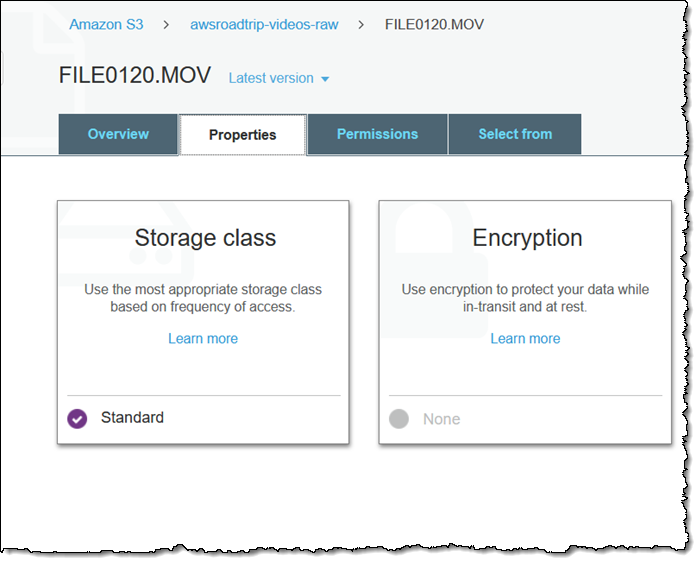
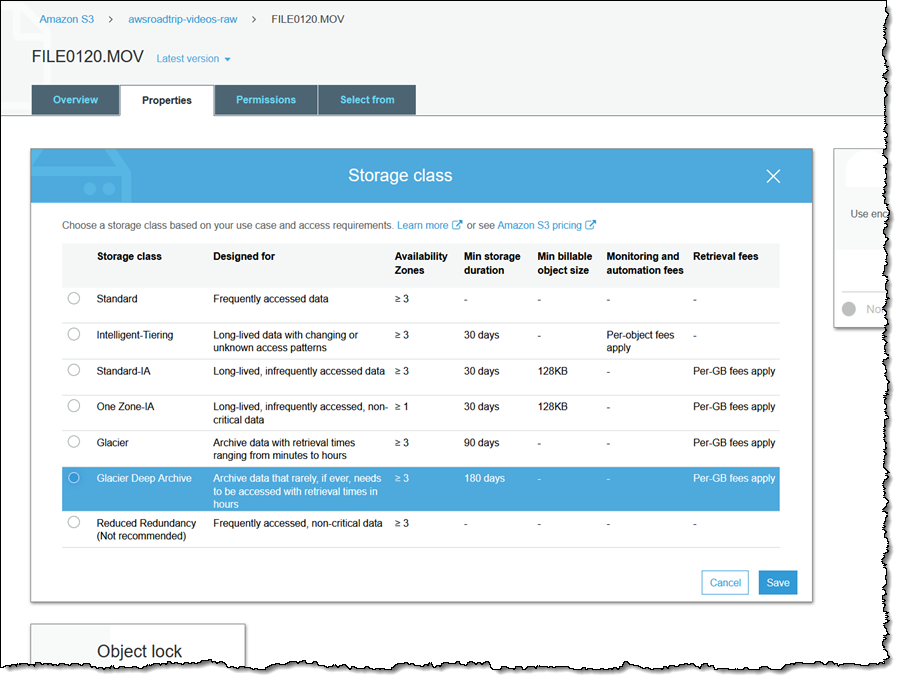
Next, I select Glacier Deep Archive and click Save:
I cannot download the object or edit any of its properties or permissions after I make this change: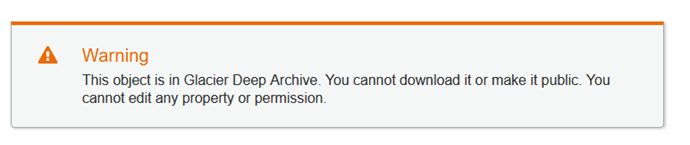
In the unlikely event that I need to access this 2013-era video, I select it and choose Restore from the Actions menu:
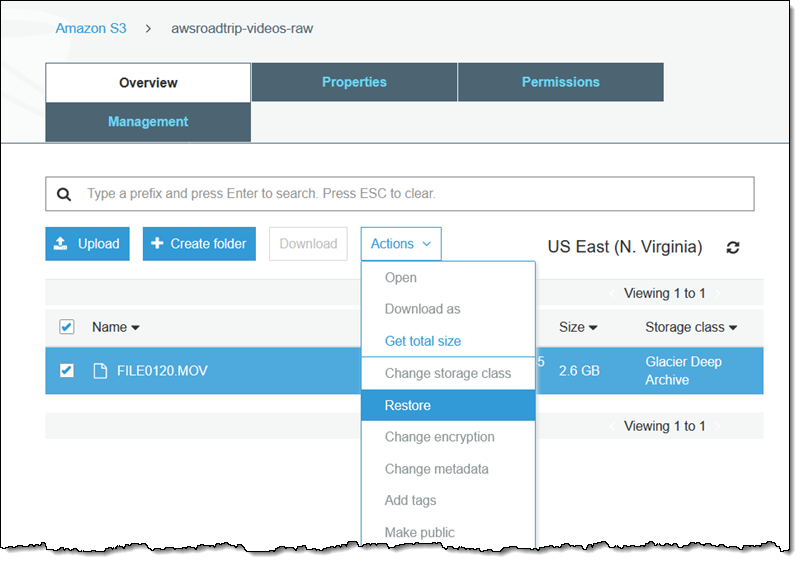
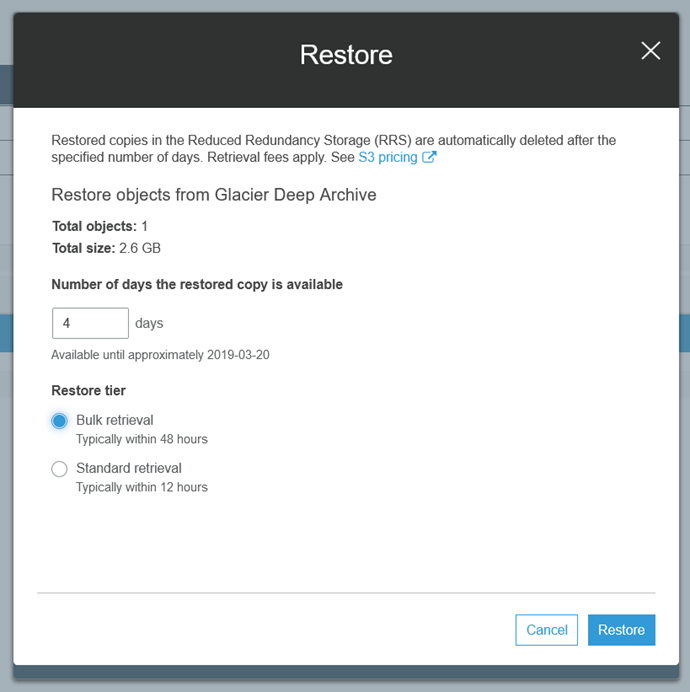
Then I specify the number of days to keep the restored copy available, and choose either bulk or standard retrieval:
Using Glacier Deep Archive Storage – Lifecycle Rules
I can also use S3 lifecycle rules. I select the bucket and click Management, then select Lifecycle:

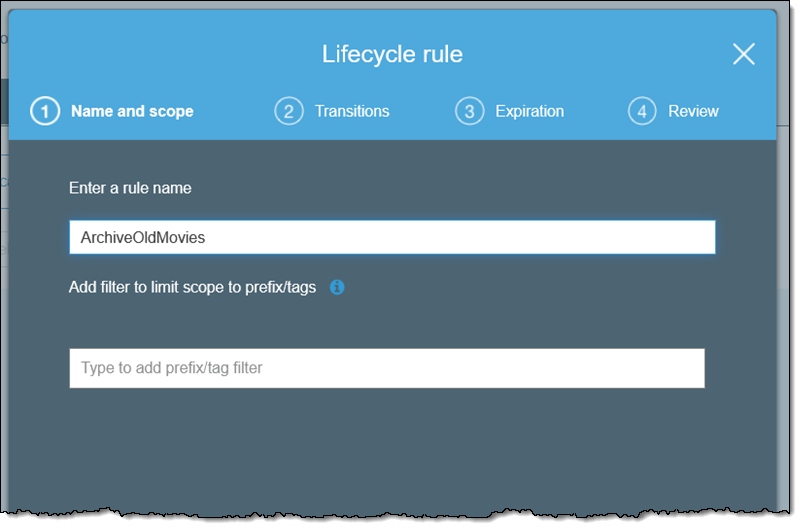
Then I click Add lifecycle rule and create my rule. I enter a name (ArchiveOldMovies), and can optionally use a path or tag filter to limit the scope of the rule:
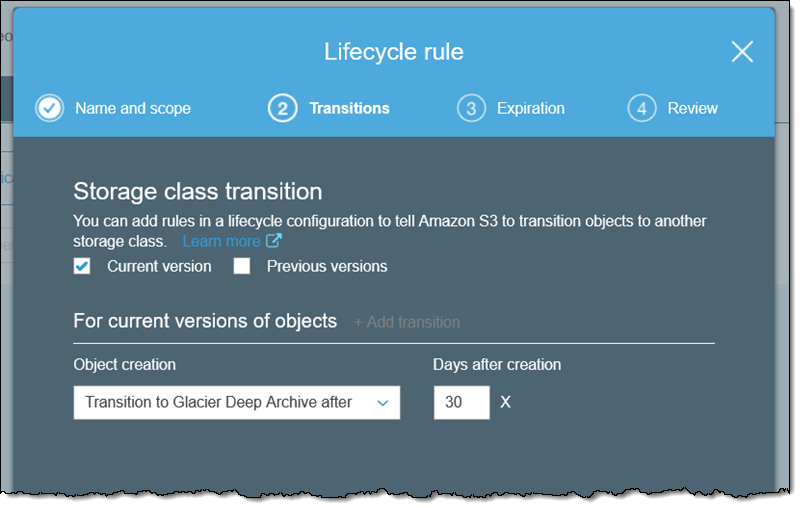
Next, I indicate that I want the rule to apply to the Current version of my objects, and specify that I want my objects to transition to Glacier Deep Archive 30 days after they are created:
Using Glacier Deep Archive – CLI / Programmatic Access
I can use the CLI to upload a new object and set the storage class:
I can also change the storage class of an existing object by copying it over itself:
If I am building a system that manages archiving and restoration, I can opt to receive notifications on an SNS topic, an SQS queue, or a Lambda function when a restore is initiated and/or completed:
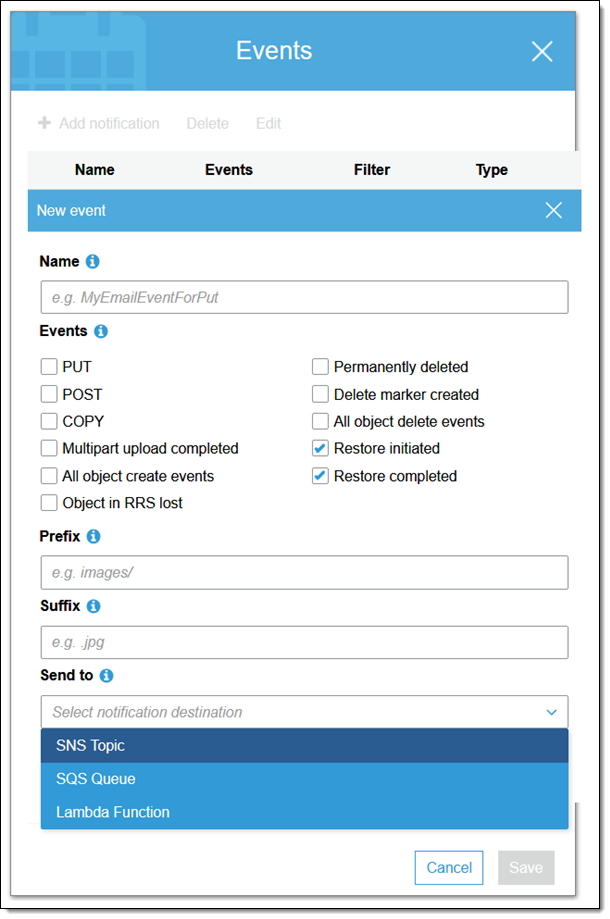
Other Access Methods
You can also use Tape Gateway configuration of AWS Storage Gateway to create a Virtual Tape Library (VTL) and configure it to use Glacier Deep Archive for storage of archived virtual tapes. This will allow you to move your existing tape-based backups to the AWS Cloud without making any changes to your existing backup workflows. You can retrieve virtual tapes archived in Glacier Deep Archive to S3 within twelve hours. With Tape Gateway and S3 Glacier Deep Archive, you no longer need on-premises physical tape libraries, and you don’t need to manage hardware refreshes and rewrite data to new physical tapes as technologies evolve. For more information, visit the Test Your Gateway Setup with Backup Software page of Storage Gateway User Guide.
Now Available
The S3 Glacier Deep Archive storage class is available today in all commercial regions and in both AWS GovCloud regions. Pricing varies by region, and the storage cost is up to 75% less than for the existing S3 Glacier storage class; visit the S3 Pricing page for more information.
— Jeff;



Source: AWS News