New – Amazon SageMaker Ground Truth Now Supports Synthetic Data Generation
Today, I am happy to announce that you can now use Amazon SageMaker Ground Truth to generate labeled synthetic image data.
Building machine learning (ML) models is an iterative process that, at a high level, starts with data collection and preparation, followed by model training and model deployment. And especially the first step, collecting large, diverse, and accurately labeled datasets for your model training, is often challenging and time-consuming.
Let’s take computer vision (CV) applications as an example. CV applications have come to play a key role in the industrial landscape. They help improve manufacturing quality or automate warehouses. Yet, collecting the data to train these CV models often takes a long time or can be impossible.
As a data scientist, you might spend months collecting hundreds of thousands of images from the production environments to make sure you capture all variations in data the model will come across. In some cases, finding all data variations might even be impossible, for example, sourcing images of rare product defects, or expensive, if you have to intentionally damage your products to get those images.
And once all data is collected, you need to accurately label the images, which is often a struggle in itself. Manually labeling images is slow and open to human error, and building custom labeling tools and setting up scaled labeling operations can be time-consuming and expensive. One way to mitigate this data challenge is by adding synthetic data to the mix.
Advantages of Combining Real-World Data with Synthetic Data
Combining your real-world data with synthetic data helps to create more complete training datasets for training your ML models.
Synthetic data itself is created by simple rules, statistical models, computer simulations, or other techniques. This allows synthetic data to be created in enormous quantities and with highly accurate labels for annotations across thousands of images. The label accuracy can be done at a very fine granularity, such as on a sub-object or pixel level, and across modalities. Modalities include bounding boxes, polygons, depth, and segments. Synthetic data can also be generated for a fraction of the cost, especially when compared to remote sensing imagery that otherwise relies on satellite, aerial, or drone image collection.
If you combine your real-world data with synthetic data, you can create more complete and balanced data sets, adding data variety that real-world data might lack. With synthetic data, you have the freedom to create any imagery environment, including edge cases that might be difficult to find and replicate in real-world data. You can customize objects and environments with variations, for example, to reflect different lighting, colors, texture, pose, or background. In other words, you can “order” the exact use case you are training your ML model for.
Now, let me show you how you can start sourcing labeled synthetic images using SageMaker Ground Truth.
Get Started on Your Synthetic Data Project with Amazon SageMaker Ground Truth
To request a new synthetic data project, navigate to the Amazon SageMaker Ground Truth console and select Synthetic data.
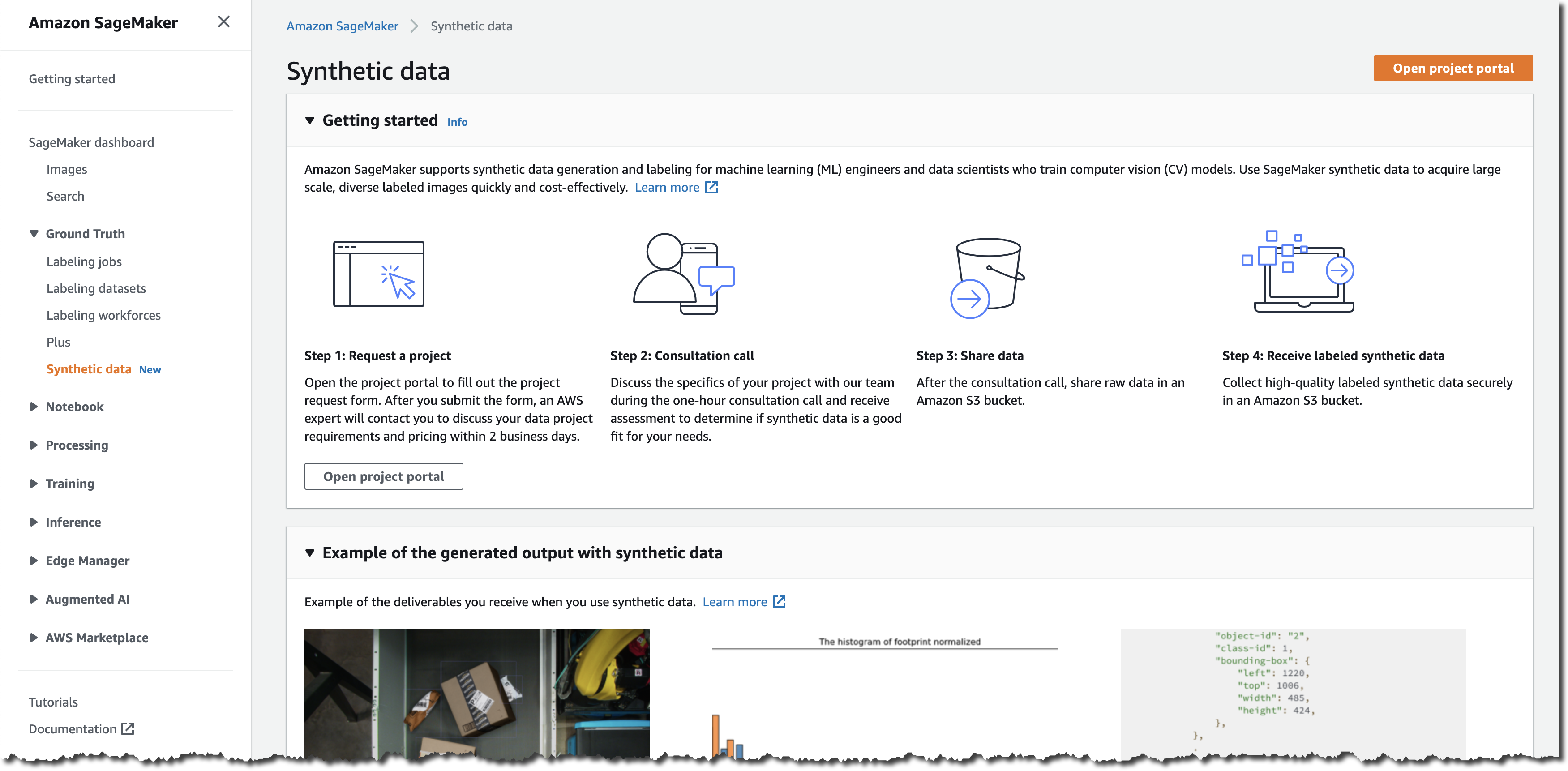
Then, select Open project portal. In the project portal, you can request new projects, monitor projects that are in progress, and view batches of generated images once they become available for review. To initiate a new project, select Request project.
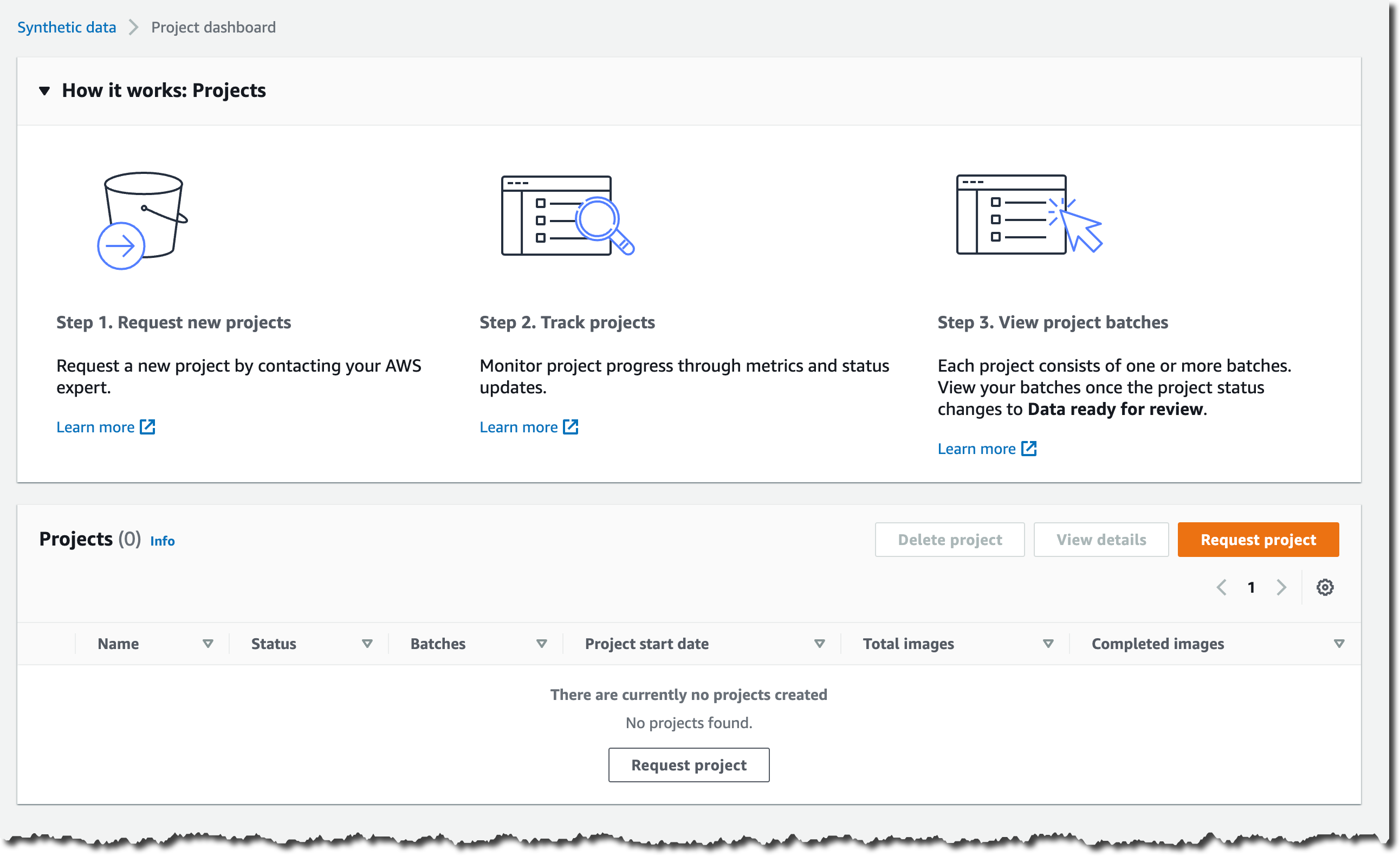
Describe your synthetic data needs and provide contact information.
After you submit the request form, you can check your project status in the project dashboard.
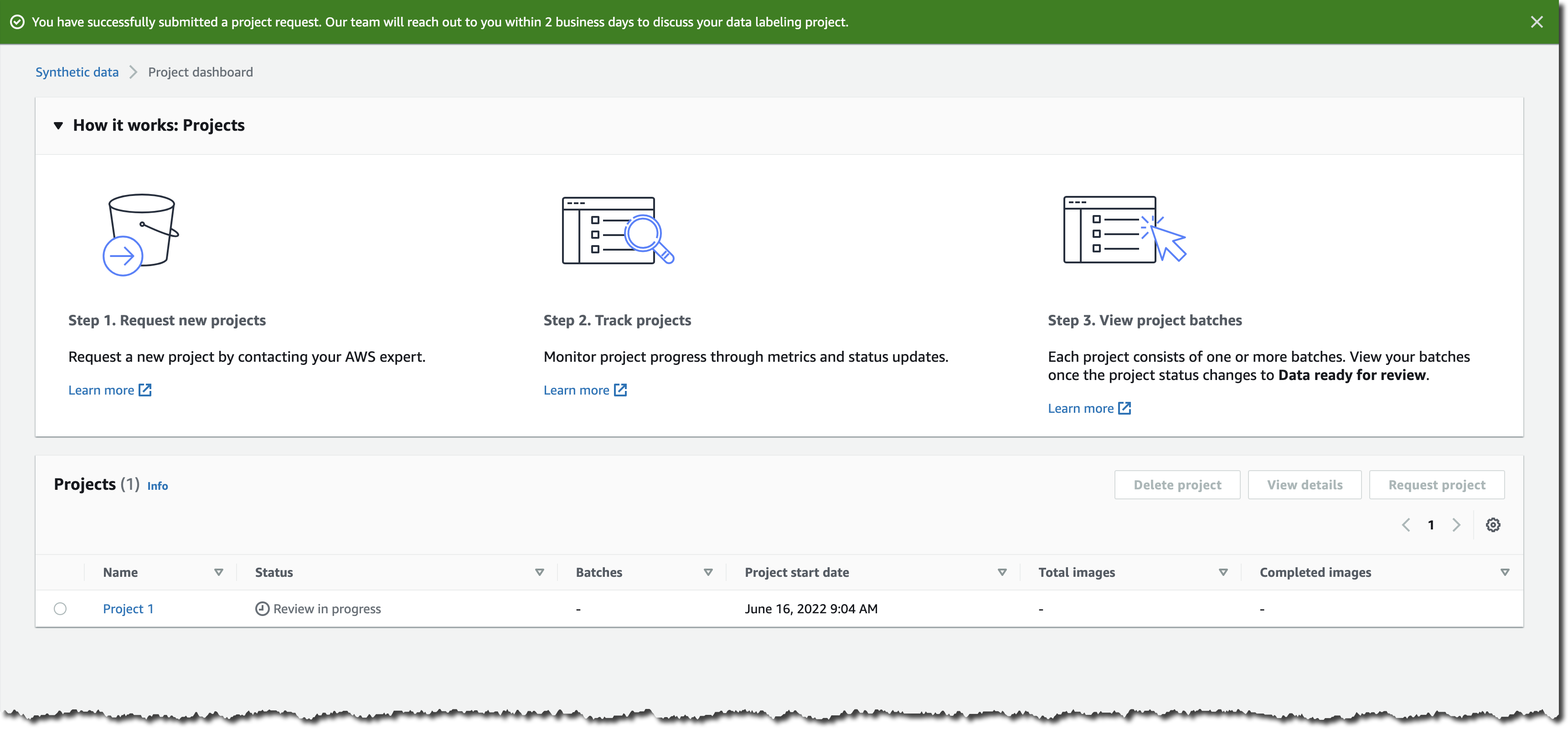
In the next step, an AWS expert will reach out to discuss your project requirements in more detail. Upon review, the team will share a custom quote and project timeline.
If you want to continue, AWS digital artists will start by creating a small test batch of labeled synthetic images as a pilot production for you to review.
They collect your project inputs, such as reference photos and available 2D and 3D assets. The team then customizes those assets, adds the specified inclusions, such as scratches, dents, and textures, and creates the configuration that describes all the variations that need to be generated.
They can also create and add new objects based on your requirements, configure distributions and locations of objects in a scene, as well as modify object size, shape, color, and surface texture.
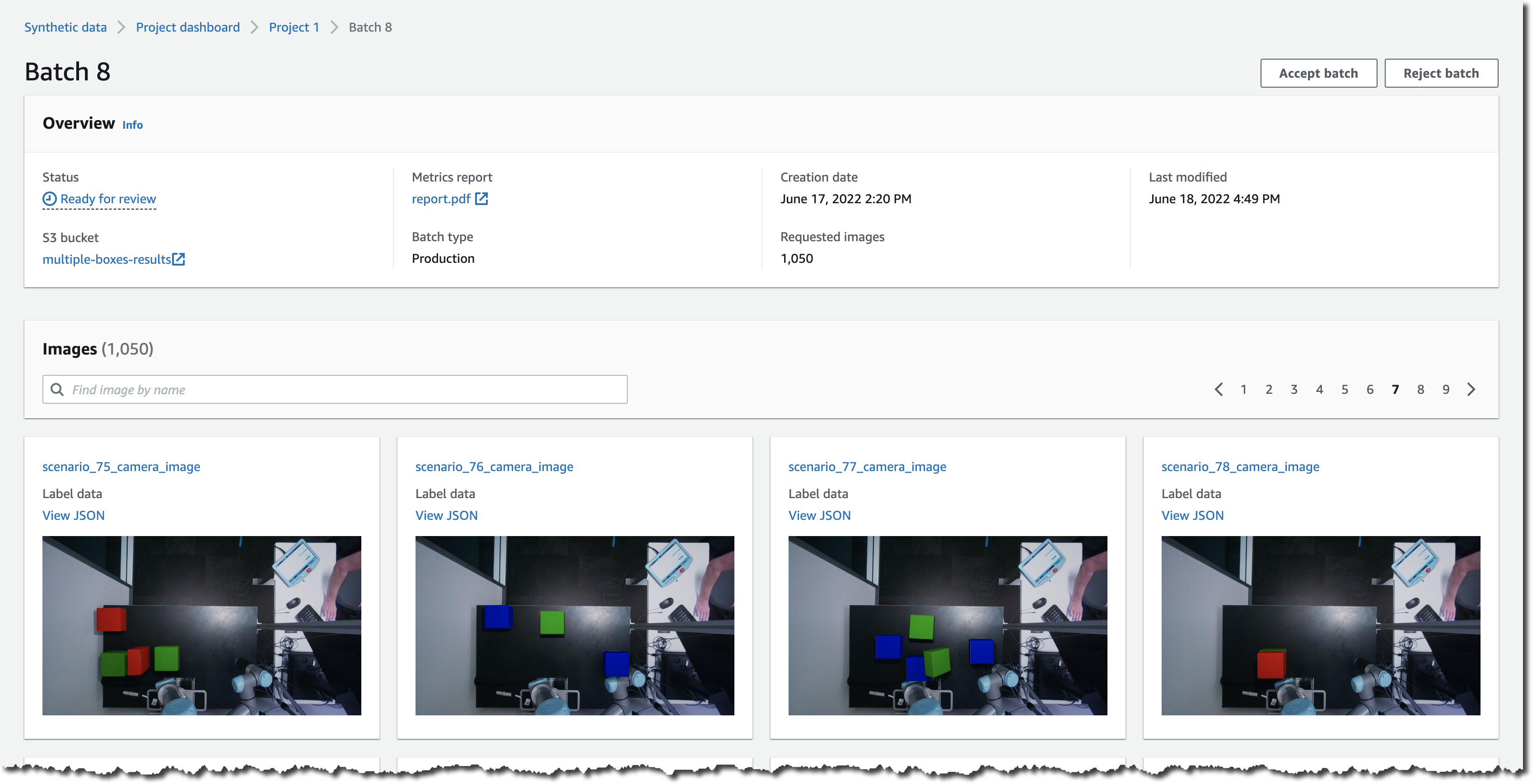
Once the objects are prepared, they are rendered using a photorealistic physics engine, capturing an image of the scene from a sensor that is placed in the virtual world. Images are also automatically labeled. Labels include 2D bounding boxes, instance segmentation, and contours.
You can monitor the progress of the data generation jobs on the project detail page. Once the pilot production test batch becomes available for review, you can spot-check the images and provide feedback for any rework that might be required.
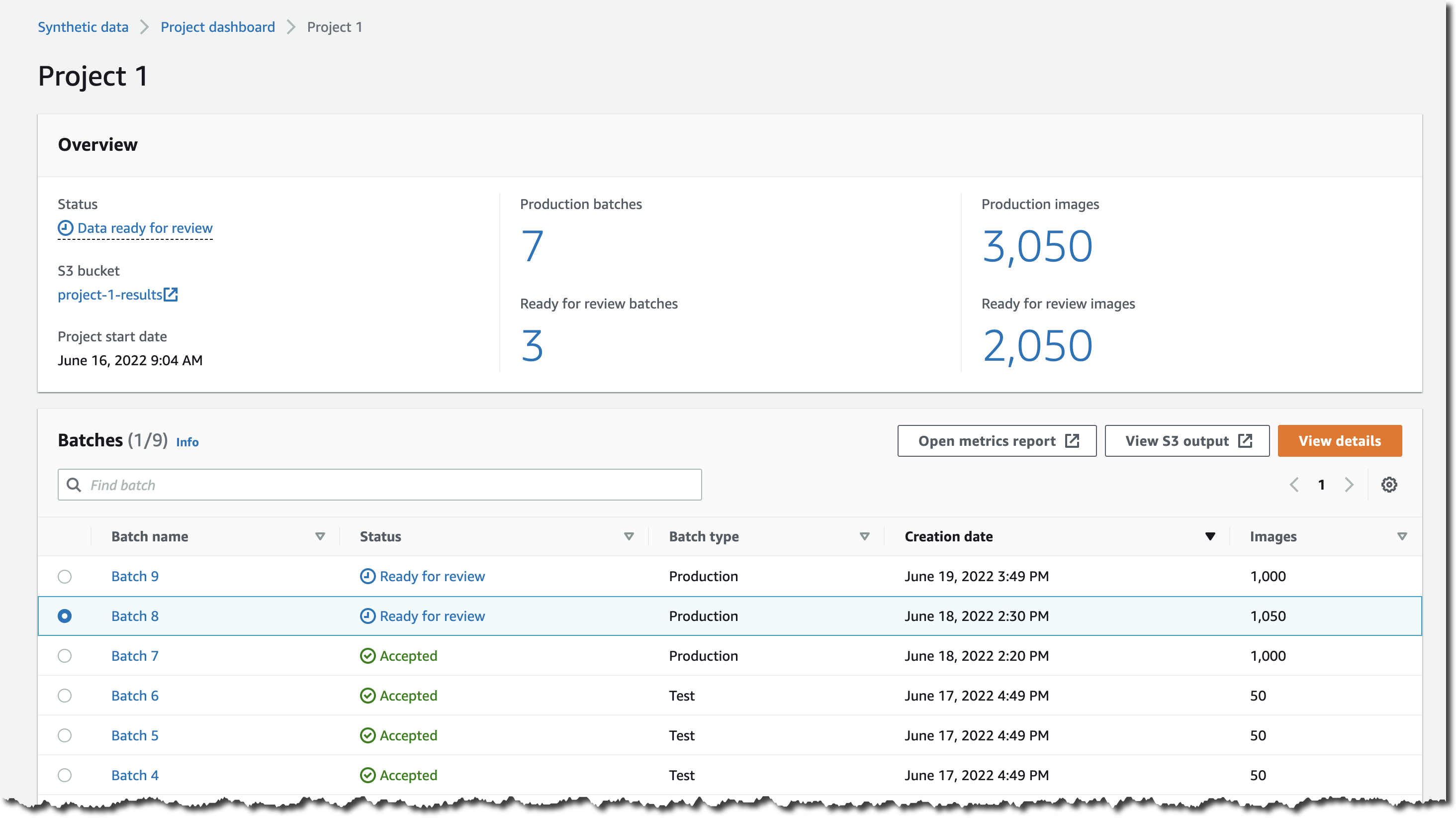
Select the batch you want to review and View details.
{kind=link}
In addition to the images, you will also receive output image labels, metadata such as object positions, and image quality metrics as Amazon SageMaker compatible JSON files.
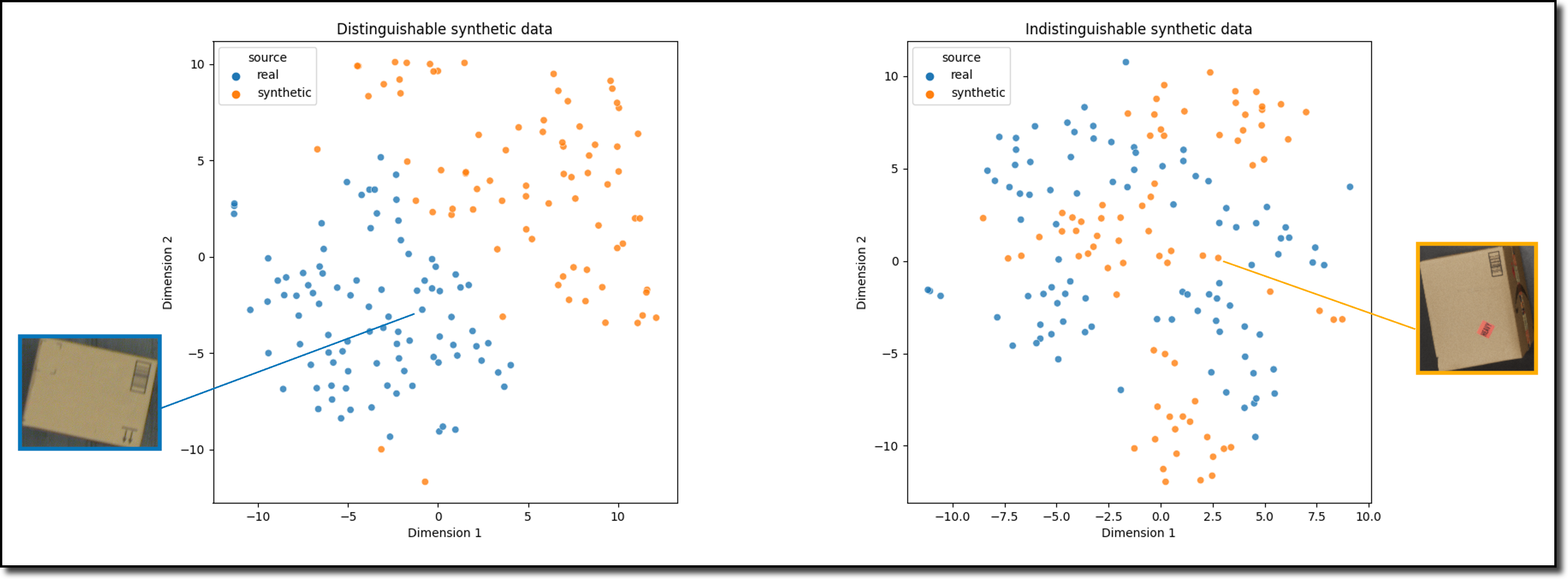
Synthetic Image Fidelity and Diversity Report
With each available batch of images, you also receive a synthetic image fidelity and diversity report. This report provides image and object level statistics and plots that help you make sense of the generated synthetic images.
The statistics are used to describe the diversity and the fidelity of the synthetic images and compare them with real images. Examples of the statistics and plots provided are the distributions of object classes, object sizes, image brightness, and image contrast, as well as the plots evaluating the indistinguishability between synthetic and real images.
Once you approve the pilot production test batch, the team will move to the production phase and start generating larger batches of labeled synthetic images with your desired label types, such as 2D bounding boxes, instance segmentation, and contours. Similar to the test batch, each production batch of images will be made available for you together with the image fidelity and diversity report to spot-check, accept, or reject.
All images and artifacts will be available for you to download from your S3 bucket once final production is complete.
Availability
Amazon SageMaker Ground Truth synthetic data is available in US East (N. Virginia). Synthetic data is priced on a per-label basis. You can request a custom quote that is tailored to your specific use case and requirements by filling out the project requirement form.
Learn more about SageMaker Ground Truth synthetic data on our Amazon SageMaker Data Labeling page.
Request your synthetic data project through the Amazon SageMaker Ground Truth console today!
— Antje



Source: AWS News