New – Data API for Amazon Aurora Serverless
If you have ever written code that accesses a relational database, you know the drill. You open a connection, use it to process one or more SQL queries or other statements, and then close the connection. You probably used a client library that was specific to your operating system, programming language, and your database. At some point you realized that creating connections took a lot of clock time and consumed memory on the database engine, and soon after found out that you could (or had to) deal with connection pooling and other tricks. Sound familiar?
The connection-oriented model that I described above is adequate for traditional, long-running programs where the setup time can be amortized over hours or even days. It is not, however, a great fit for serverless functions that are frequently invoked and that run for time intervals that range from milliseconds to minutes. Because there is no long-running server, there’s no place to store a connection identifier for reuse.
Aurora Serverless Data API
In order to resolve this mismatch between serverless applications and relational databases, we are launching a Data API for the MySQL-compatible version of Amazon Aurora Serverless. This API frees you from the complexity and overhead that come along with traditional connection management, and gives you the power to quickly and easily execute SQL statements that access and modify your Amazon Aurora Serverless Database instances.
The Data API is designed to meet the needs of both traditional and serverless apps. It takes care of managing and scaling long-term connections to the database and returns data in JSON form for easy parsing. All traffic runs over secure HTTPS connections. It includes the following functions:
ExecuteStatement – Run a single SQL statement, optionally within a transaction.
BatchExecuteStatement – Run a single SQL statement across an array of data, optionally within a transaction.
BeginTransaction – Begin a transaction, and return a transaction identifier. Transactions are expected to be short (generally 2 to 5 minutes).
CommitTransaction – End a transaction and commit the operations that took place within it.
RollbackTransaction – End a transaction without committing the operations that took place within it.
Each function must run to completion within 1 minute, and can return up to 1 megabyte of data.
Using the Data API
I can use the Data API from the Amazon RDS Console, the command line, or by writing code that calls the functions that I described above. I’ll show you all three in this post.
The Data API is really easy to use! The first step is to enable it for the desired Amazon Aurora Serverless database. I open the Amazon RDS Console, find & select the cluster, and click Modify:
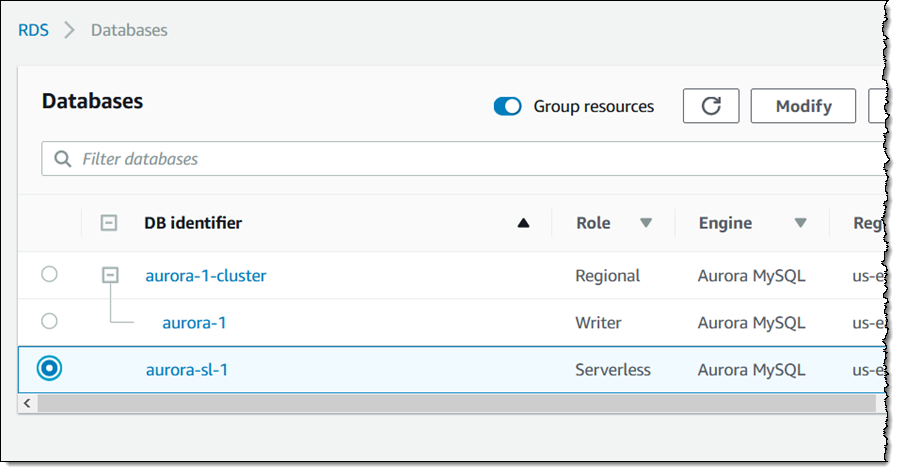
Then I scroll down to the Network & Security section, click Data API, and Continue:
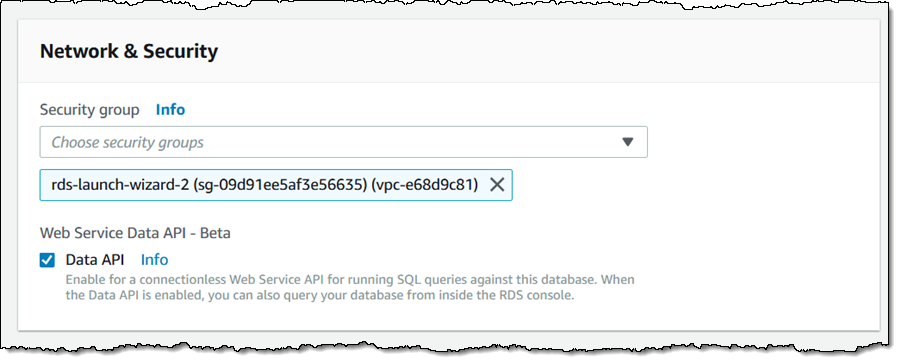
On the next page I choose to apply the settings immediately, and click Modify cluster:
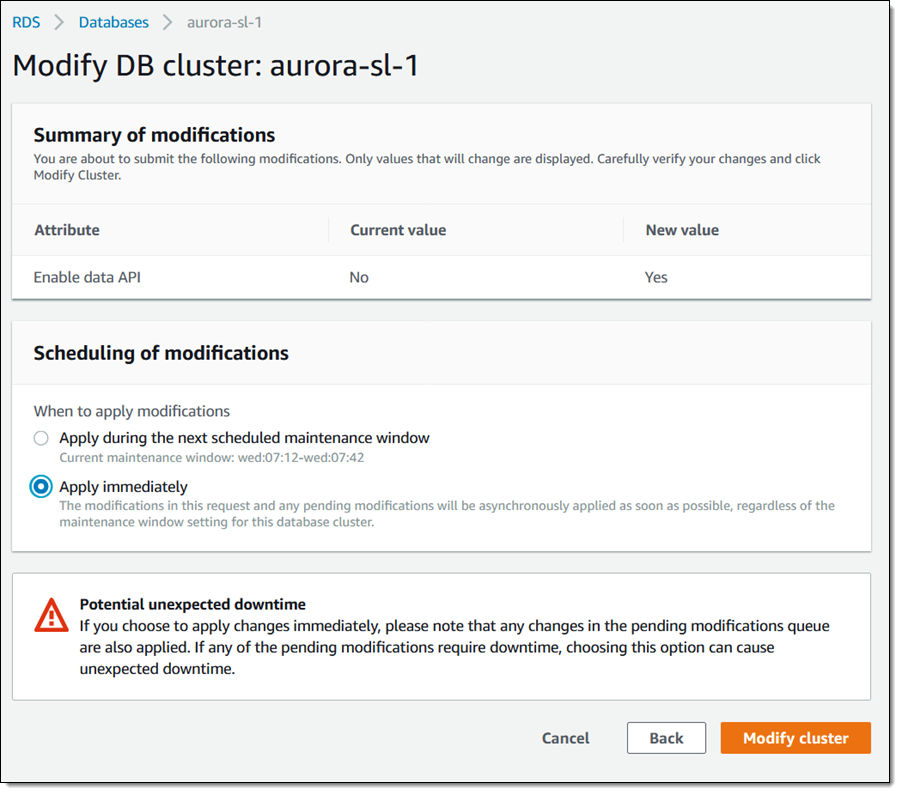
Now I need to create a secret to store the credentials that are needed to access my database. I open the Secrets Manager Console and click Store a new secret. I leave Credentials for RDS selected, enter a valid database user name and password, optionally choose a non-default encryption key, and then select my serverless database. Then I click Next:
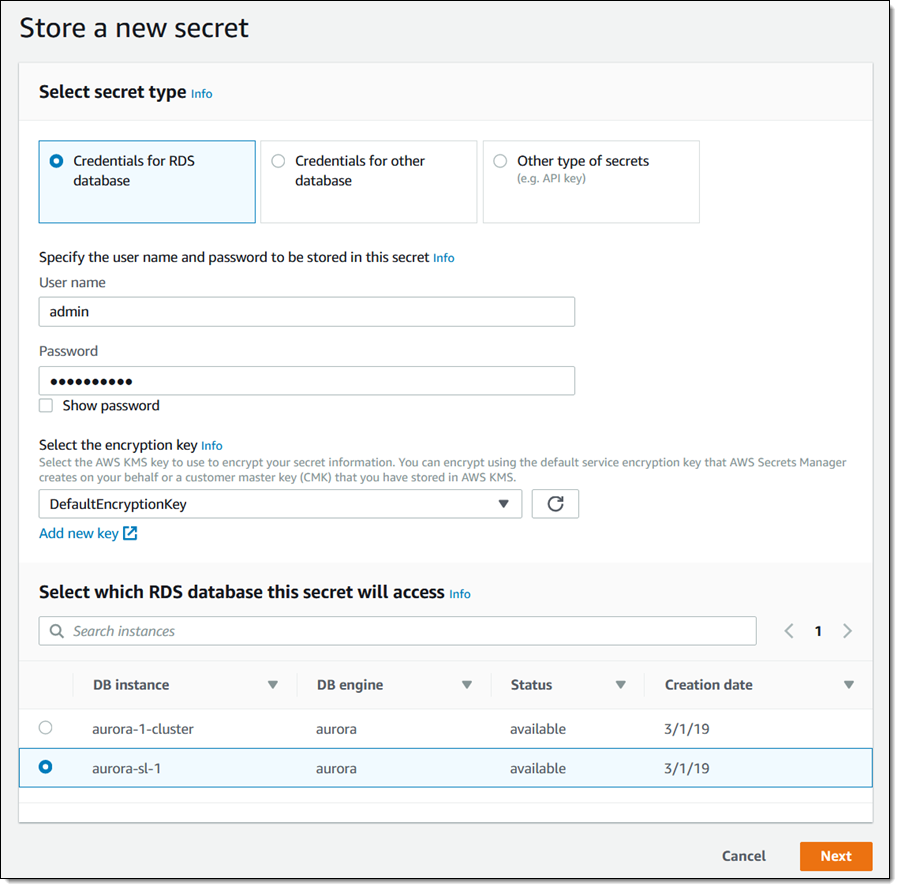
I name my secret and tag it, and click Next to configure it:
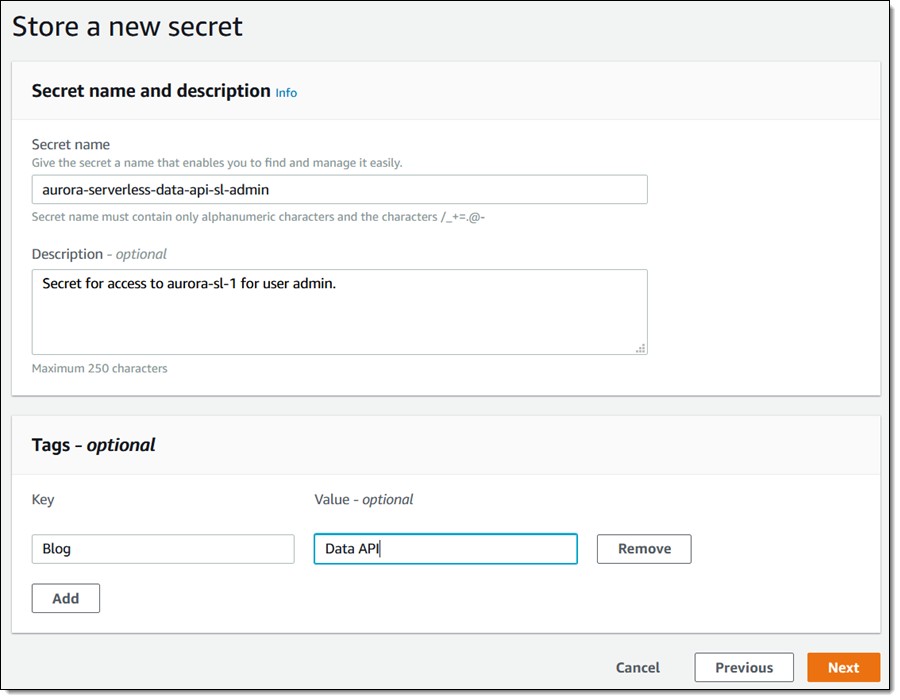
I use the default values on the next page, click Next again, and now I have a brand new secret:
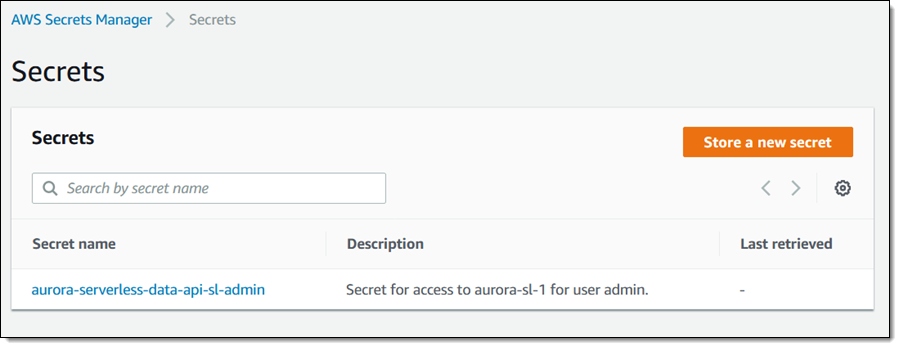
Now I need two ARNs, one for the database and one for the secret. I fetch both from the console, first for the database:
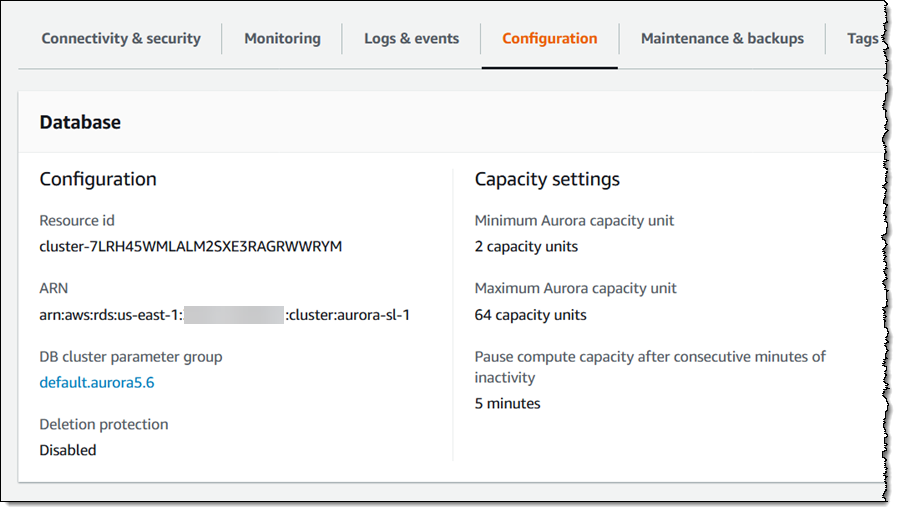
And then for the secret:
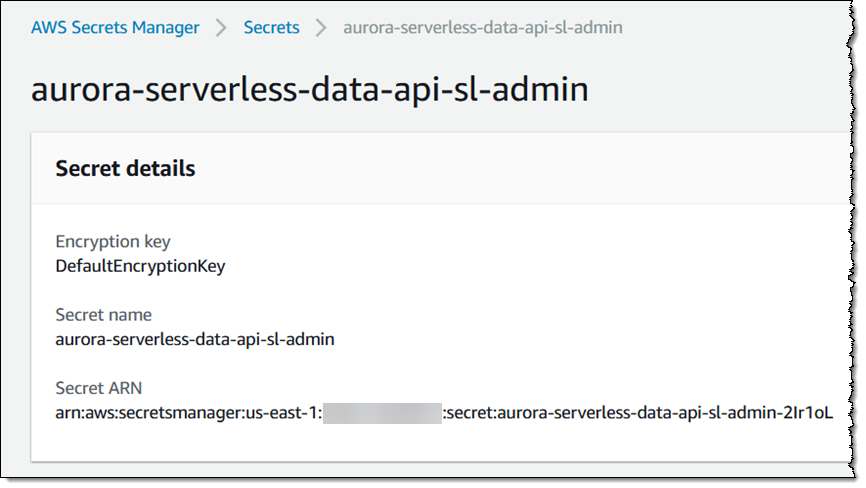
The pair of ARNs (database and secret) provides me with access to my database, and I will protect them accordingly!
Using the Data API from the Amazon RDS Console
I can use the Query Editor in the Amazon RDS Console to run queries that call the Data API. I open the console and click Query Editor, and create a connection to the database. I select the cluster, enter my credentials, and pre-select the table of interest. Then I click Connect to database to proceed:
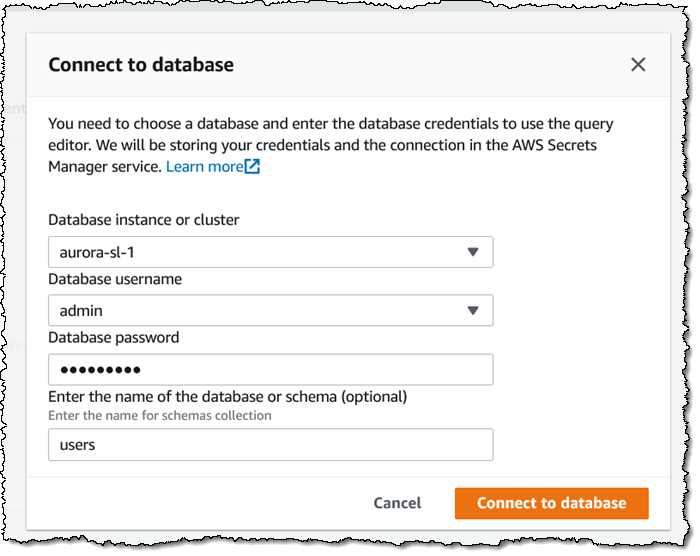
I enter a query and click Run, and view the results within the editor:
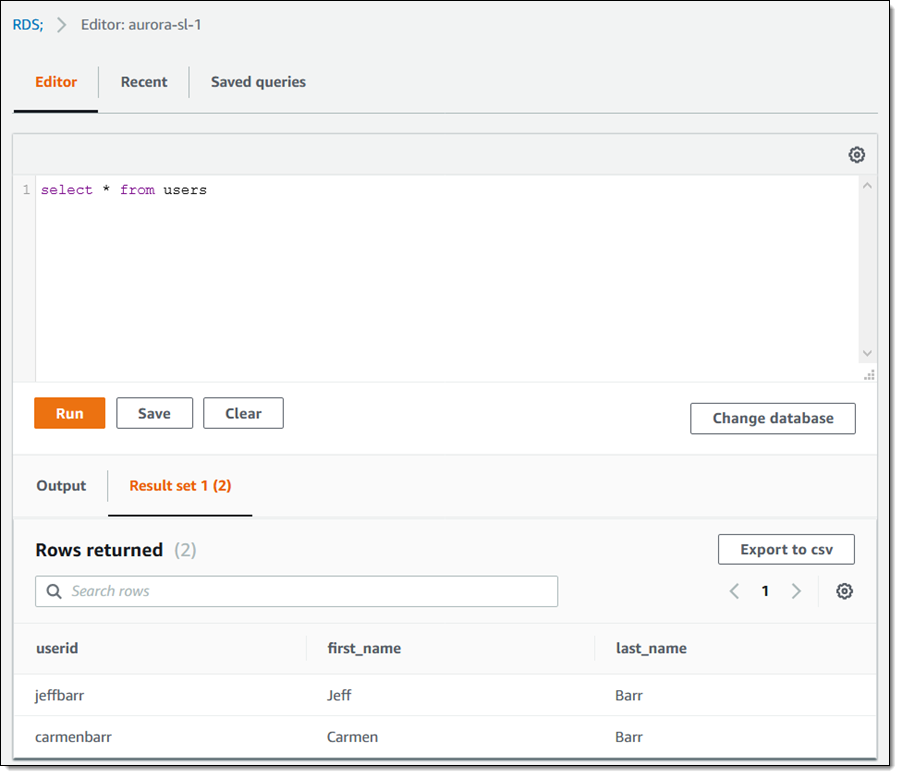
Using the Data API from the Command Line
I can exercise the Data API from the command line:
I can use jq to pick out the part of the result that is of interest to me:
I can query the table and get the results (the SQL statement is "select * from users where userid='jeffbarr'"):
If I specify --include-result-metadata, the query also returns data that describes the columns of the result (I’ll show only the first one in the interest of frugality):
The Data API also allows me to wrap a series of statements in a transaction, and then either commit or rollback. Here’s how I do that (I’m omitting --secret-arn and --resource-arn for clarity):
If I decide not to commit, I invoke rollback-transaction instead.
Using the Data API with Python and Boto
Since this is an API, programmatic access is easy. Here’s some very simple Python / Boto code:
And the output:
Genuine, production-quality code would reference the table columns symbolically using the metadata that is returned as part of the response.
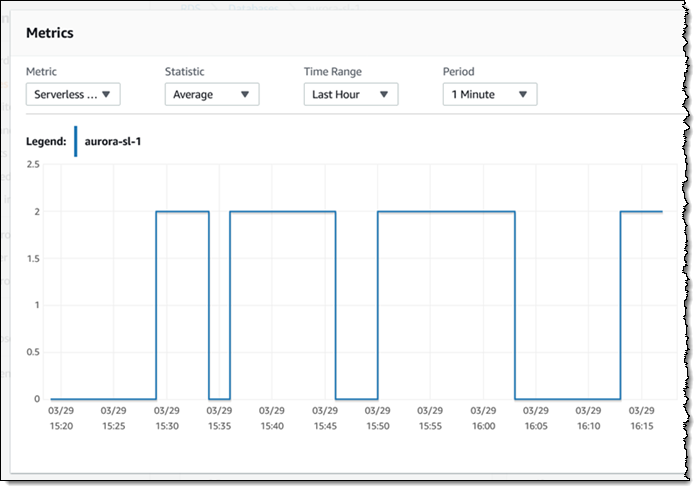
By the way, my Amazon Aurora Serverless cluster was configured to scale capacity all the way down to zero when not active. Here’s what the scaling activity looked like while I was writing this post and running the queries:
Now Available
You can make use of the Data API today in the US East (N. Virginia), US East (Ohio), US West (Oregon), Asia Pacific (Tokyo), and Europe (Ireland) Regions. There is no charge for the API, but you will pay the usual price for data transfer out of AWS.
— Jeff;



Source: AWS News