New – Introducing SageMaker Training Compiler
 Today, we’re pleased to announce Amazon SageMaker Training Compiler, a new Amazon SageMaker capability that can accelerate the training of deep learning (DL) models by up to 50%.
Today, we’re pleased to announce Amazon SageMaker Training Compiler, a new Amazon SageMaker capability that can accelerate the training of deep learning (DL) models by up to 50%.
As DL models grow in complexity, so too does the time it can take to optimize and train them. For example, it can take 25,000 GPU-hours to train popular natural language processing (NLP) model “RoBERTa“. Although there are techniques and optimizations that customers can apply to reduce the time it can take to train a model, these also take time to implement and require a rare skillset. This can impede innovation and progress in the wider adoption of artificial intelligence (AI).
How has this been done to date?
Typically, there are three ways to speed up training:
- Using more powerful, individual machines to process the calculations
- Distributing compute across a cluster of GPU instances to train the model in parallel
- Optimizing model code to run more efficiently on GPUs by utilizing less memory and compute.
In practice, optimizing machine learning (ML) code is difficult, time-consuming, and a rare skill set to acquire. Data scientists typically write their training code in a Python-based ML framework, such as TensorFlow or PyTorch, relying on ML frameworks to convert their Python code into mathematical functions that can run on GPUs, commonly known as kernels. However, this translation from the Python code of a user is often inefficient because ML frameworks use pre-built, generic GPU kernels, instead of creating kernels specific to the code and model of the user.
It can take even the most skilled GPU programmers months to create custom kernels for each new model and optimize them. We built SageMaker Training Compiler to solve this problem.
Today’s launch lets SageMaker Training Compiler automatically compile your Python training code and generate GPU kernels specifically for your model. Consequently, the training code will use less memory and compute, and therefore train faster. For example, when fine-tuning Hugging Face’s GPT-2 model, SageMaker Training Compiler reduced training time from nearly 3 hours to 90 minutes.
Automatically Optimizing Deep Learning Models
So, how have we achieved this acceleration? SageMaker Training Compiler accelerates training jobs by converting DL models from their high-level language representation to hardware-optimized instructions that train faster than jobs with off-the-shelf frameworks. Under the hood, SageMaker Training Compiler makes incremental optimizations beyond what the native PyTorch and TensorFlow frameworks offer to maximize compute and memory utilization on SageMaker GPU instances.
More specifically, SageMaker Training Compiler uses graph-level optimization (operator fusion, memory planning, and algebraic simplification), data flow-level optimizations (layout transformation, common sub-expression elimination), and back-end optimizations (memory latency hiding, loop oriented optimizations) to produce an optimized model that efficiently uses hardware resources. As a result, training is accelerated by up to 50%, and the returned model is the same as if SageMaker Training Compiler had not been used.
But how do you use SageMaker Training Compiler with your models? It can be as simple as adding two lines of code!
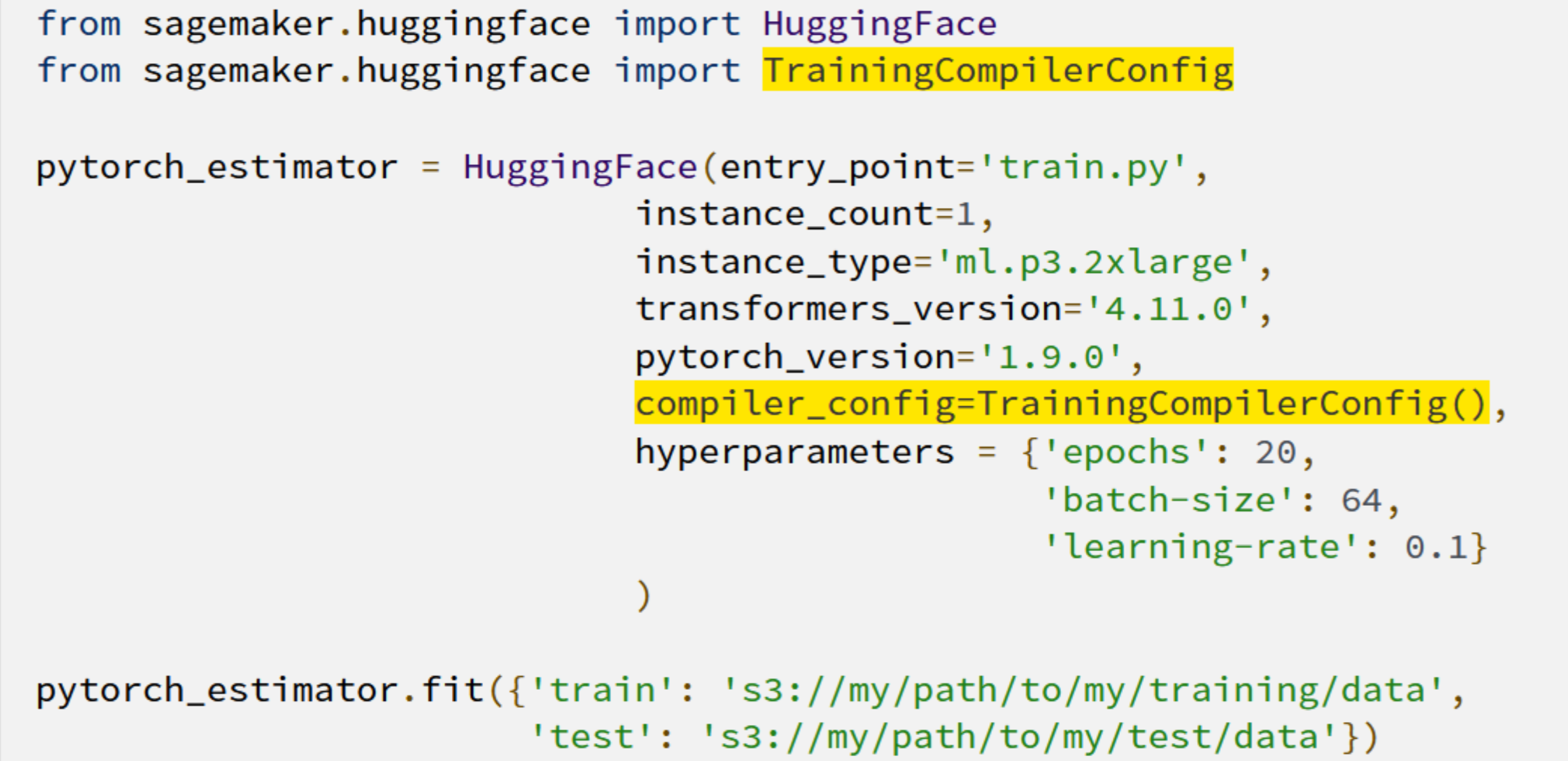
The shortened training times mean that customers gain more time for innovating and deploying their newly-trained models at a reduced cost and a greater ability to experiment with larger models and more data.
Getting the most from SageMaker Training Compiler
Although many DL models can benefit from SageMaker Training Compiler, larger models with longer training will realize the greatest time and cost savings. For example, training time and costs fell by 30% on a long-running RoBERTa-base fine-tuning exercise.
Jorge Lopez Grisman, a Senior Data Scientist at Quantum Health – an organization on a mission to “make healthcare navigation smarter, simpler, and more cost-effective for everyone” – said:
“Iterating with NLP models can be a challenge because of their size: long training times bog down workflows and high costs can discourage our team from trying larger models that might offer better performance. Amazon SageMaker Training Compiler is exciting because it has the potential to alleviate these frictions. Achieving a speedup with SageMaker Training Compiler is a real win for our team that will make us more agile and innovative moving forward.”
Further Resources
To learn more about how Amazon SageMaker Training Compiler can benefit you, you can visit our page here. And to get started see our technical documentation here.



Source: AWS News