New – Provisioned Concurrency for Lambda Functions
It’s really true that time flies, especially when you don’t have to think about servers: AWS Lambda just turned 5 years old and the team is always looking for new ways to help customers build and run applications in an easier way.
As more mission critical applications move to serverless, customers need more control over the performance of their applications. Today we are launching Provisioned Concurrency, a feature that keeps functions initialized and hyper-ready to respond in double-digit milliseconds. This is ideal for implementing interactive services, such as web and mobile backends, latency-sensitive microservices, or synchronous APIs.
When you invoke a Lambda function, the invocation is routed to an execution environment to process the request. When a function has not been used for some time, when you need to process more concurrent invocations, or when you update a function, new execution environments are created. The creation of an execution environment takes care of installing the function code and starting the runtime. Depending on the size of your deployment package, and the initialization time of the runtime and of your code, this can introduce latency for the invocations that are routed to a new execution environment. This latency is usually referred to as a “cold start”. For most applications this additional latency is not a problem. For some applications, however, this latency may not be acceptable.
When you enable Provisioned Concurrency for a function, the Lambda service will initialize the requested number of execution environments so they can be ready to respond to invocations.
Configuring Provisioned Concurrency
I create two Lambda functions that use the same Java code and can be triggered by Amazon API Gateway. To simulate a production workload, these functions are repeating some mathematical computation 10 million times in the initialization phase and 200,000 times for each invocation. The computation is using java.Math.Random and conditions (if ...) to avoid compiler optimizations (such as “unlooping” the iterations). Each function has 1GB of memory and the size of the code is 1.7MB.
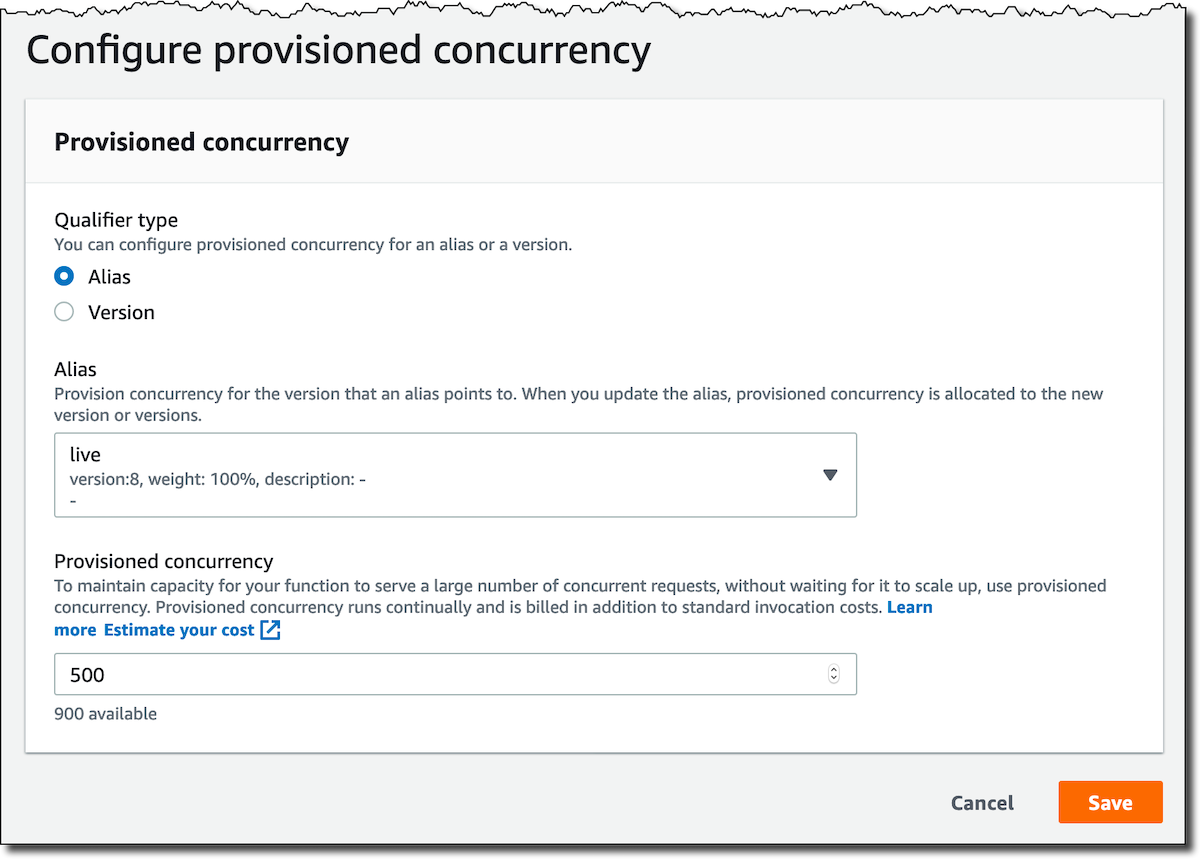
I want to enable Provisioned Concurrency only for one of the two functions, so that I can compare how they react to a similar workload. In the Lambda console, I select one of the functions. In the configuration tab, I see the new Provisioned Concurrency settings.

I select Add configuration. Provisioned Concurrency can be enabled for a specific Lambda function version or alias (you can’t use $LATEST). You can have different settings for each version of a function. Using an alias, it is easier to enable these settings to the correct version of your function. In my case I select the alias live that I keep updated to the latest version using the AWS SAM AutoPublishAlias function preference. For the Provisioned Concurrency, I enter 500 and Save.
Now, the Provisioned Concurrency configuration is in progress. The execution environments are being prepared to serve concurrent incoming requests based on my input. During this time the function remains available and continues to serve traffic.

After a few minutes, the concurrency is ready. With these settings, up to 500 concurrent requests will find an execution environment ready to process them. If I go above that, the usual scaling of Lambda functions still applies.

To generate some load, I use an Amazon Elastic Compute Cloud (EC2) instance in the same region. To keep it simple, I use the ab tool bundled with the Apache HTTP Server to call the two API endpoints 10,000 times with a concurrency of 500. Since these are new functions, I expect that:
- For the function with Provisioned Concurrency enabled and set to 500, my requests are managed by pre-initialized execution environments.
- For the other function, that has Provisioned Concurrency disabled, about 500 execution environments need to be provisioned, adding some latency to the same amount of invocations, about 5% of the total.
One cool feature of the ab tool is that is reporting the percentage of the requests served within a certain time. That is a very good way to look at API latency, as described in this post on Serverless Latency by Tim Bray.
Here are the results for the function with Provisioned Concurrency disabled:
Percentage of the requests served within a certain time (ms)
50% 351
66% 359
75% 383
80% 396
90% 435
95% 1357
98% 1619
99% 1657
100% 1923 (longest request)
Looking at these numbers, I see that 50% the requests are served within 351ms, 66% of the requests within 359ms, and so on. It’s clear that something happens when I look at 95% or more of the requests: the time suddenly increases by about a second.
These are the results for the function with Provisioned Concurrency enabled:
Percentage of the requests served within a certain time (ms)
50% 352
66% 368
75% 382
80% 387
90% 400
95% 415
98% 447
99% 513
100% 593 (longest request)
Let’s compare those numbers in a graph.

As expected for my test workload, I see a big difference in the response time of the slowest 5% of the requests (between 95% and 100%), where the function with Provisioned Concurrency disabled shows the latency added by the creation of new execution environments and the (slow) initialization in my function code.
In general, the amount of latency added depends on the runtime you use, the size of your code, and the initialization required by your code to be ready for a first invocation. As a result, the added latency can be more, or less, than what I experienced here.
The number of invocations affected by this additional latency depends on how often the Lambda service needs to create new execution environments. Usually that happens when the number of concurrent invocations increases beyond what already provisioned, or when you deploy a new version of a function.
A small percentage of slow response times (generally referred to as tail latency) really makes a difference in end user experience. Over an extended period of time, most users are affected during some of their interactions. With Provisioned Concurrency enabled, user experience is much more stable.
Provisioned Concurrency is a Lambda feature and works with any trigger. For example, you can use it with WebSockets APIs, GraphQL resolvers, or IoT Rules. This feature gives you more control when building serverless applications that require low latency, such as web and mobile apps, games, or any service that is part of a complex transaction.
Available Now
Provisioned Concurrency can be configured using the console, the AWS Command Line Interface (CLI), or AWS SDKs for new or existing Lambda functions, and is available today in the following AWS Regions: in US East (Ohio), US East (N. Virginia), US West (N. California), US West (Oregon), Asia Pacific (Hong Kong), Asia Pacific (Mumbai), Asia Pacific (Seoul), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Canada (Central), Europe (Frankfurt), Europe (Ireland), Europe (London), Europe (Paris), and Europe (Stockholm), Middle East (Bahrain), and South America (São Paulo).
You can use the AWS Serverless Application Model (SAM) and SAM CLI to test, deploy and manage serverless applications that use Provisioned Concurrency.
With Application Auto Scaling you can automate configuring the required concurrency for your functions. As policies, Target Tracking and Scheduled Scaling are supported. Using these policies, you can automatically increase the amount of concurrency during times of high demand and decrease it when the demand decreases.
You can also use Provisioned Concurrency today with AWS Partner tools, including configuring Provisioned Currency settings with the Serverless Framework and Terraform, or viewing metrics with Datadog, Epsagon, Lumigo, New Relic, SignalFx, SumoLogic, and Thundra.
You only pay for the amount of concurrency that you configure and for the period of time that you configure it. Pricing in US East (N. Virginia) is $0.015 per GB-hour for Provisioned Concurrency and $0.035 per GB-hour for Duration. The number of requests is charged at the same rate as normal functions. You can find more information in the Lambda pricing page.
This new feature enables developers to use Lambda for a variety of workloads that require highly consistent latency. Let me know what you are going to use it for!
— Danilo



Source: AWS News