NoSQL Workbench for Amazon DynamoDB – Available in Preview
I am always impressed by the flexibility of Amazon DynamoDB, providing our customers a fully-managed key-value and document database that can easily scale from a few requests per month to millions of requests per second.
The DynamoDB team released so many great features recently, from on-demand capacity, to support for native ACID transactions. Here’s a great recap of other recent DynamoDB announcements such as global tables, point-in-time recovery, and instant adaptive capacity. DynamoDB now encrypts all customer data at rest by default.
However, switching mindset from a relational database to NoSQL is not that easy. Last year we had two amazing talks at re:Invent that can help you understand how DynamoDB works, and how you can use it for your use cases:
- Amazon DynamoDB Under the Hood: How We Built a Hyper-Scale Database by Jaso Sorenson
- Amazon DynamoDB Deep Dive: Advanced Design Patterns for DynamoDB by Rick Houlihan
To help you even further, we are introducing today in preview NoSQL Workbench for Amazon DynamoDB, a free, client-side application available for Windows and macOS to help you design and visualize your data model, run queries on your data, and generate the code for your application!
The three main capabilities provided by the NoSQL Workbench are:
- Data modeler — to build new data models, adding tables and indexes, or to import, modify, and export existing data models.
- Visualizer — to visualize data models based on their applications access patterns, with sample data that you can add manually or import via a SQL query.
- Operation builder — to define and execute data-plane operations or generate ready-to-use sample code for them.
To see how this new tool can simplify working with DynamoDB, let’s build an application to retrieve information on customers and their orders.
Using the NoSQL Workbench
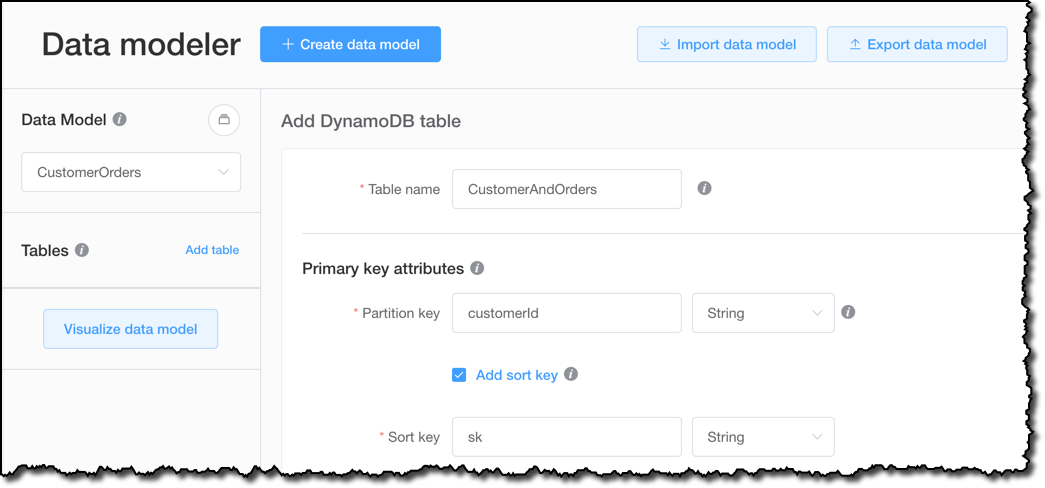
In the Data modeler, I start by creating a CustomerOrders data model, and I add a table, CustomerAndOrders, to hold my customer data and the information on their orders. You can use this tool to create a simple data model where customers and orders are in two distinct tables, each one with their own primary keys. There would be nothing wrong with that. Here I’d like to show how this tool can also help you use more advanced design patterns. By having the customer and order data in a single table, I can construct queries that return all the data I need with a single interaction with DynamoDB, speeding up the performance of my application.
As partition key, I use the customerId. This choice provides an even distribution of data across multiple partitions. The sort key in my data model will be an overloaded attribute, in the sense that it can hold different data depending on the item:
- A fixed string, for example
customer, for the items containing the customer data. - The order date, written using ISO 8601 strings such as
20190823, for the items containing orders.
By overloading the sort key with these two possible values, I am able to run a single query that returns the customer data and the most recent orders. For this reason, I use a generic name for the sort key. In this case, I use sk.
Apart from the partition key and the optional sort key, DynamoDB has a flexible schema, and the other attributes can be different for each item in a table. However, with this tool I have the option to describe in the data model all the possible attributes I am going to use for a table. In this way, I can check later that all the access patterns I need for my application work well with this data model.
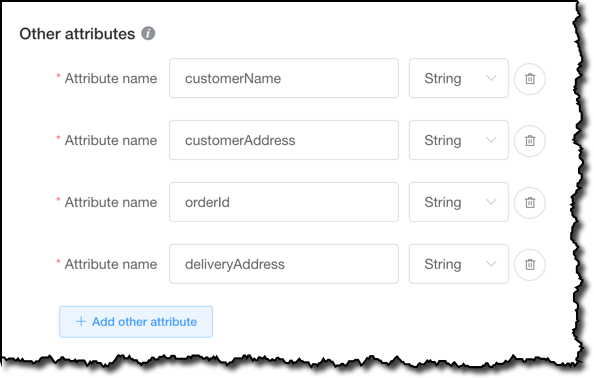
For this table, I add the following attributes:
customerNameandcustomerAddress, for the items in the table containing customer data.orderIdanddeliveryAddress, for the items in the table containing order data.
I am not adding a orderDate attribute, because for this data model the value will be stored in the sk sort key. For a real production use case, you would probably have much more attributes to describe your customers and orders, but I am trying to keep things simple enough here to show what you can do, without getting lost in details.
Another access pattern for my application is to be able to get a specific order by ID. For that, I add a global secondary index to my table, with orderId as partition key and no sort key.

I add the table definition to the data model, and move on to the Visualizer. There, I update the table by adding some sample data. I add data manually, but I could import a few rows from a table in a MySQL database, for example to simplify a NoSQL migration from a relational database.
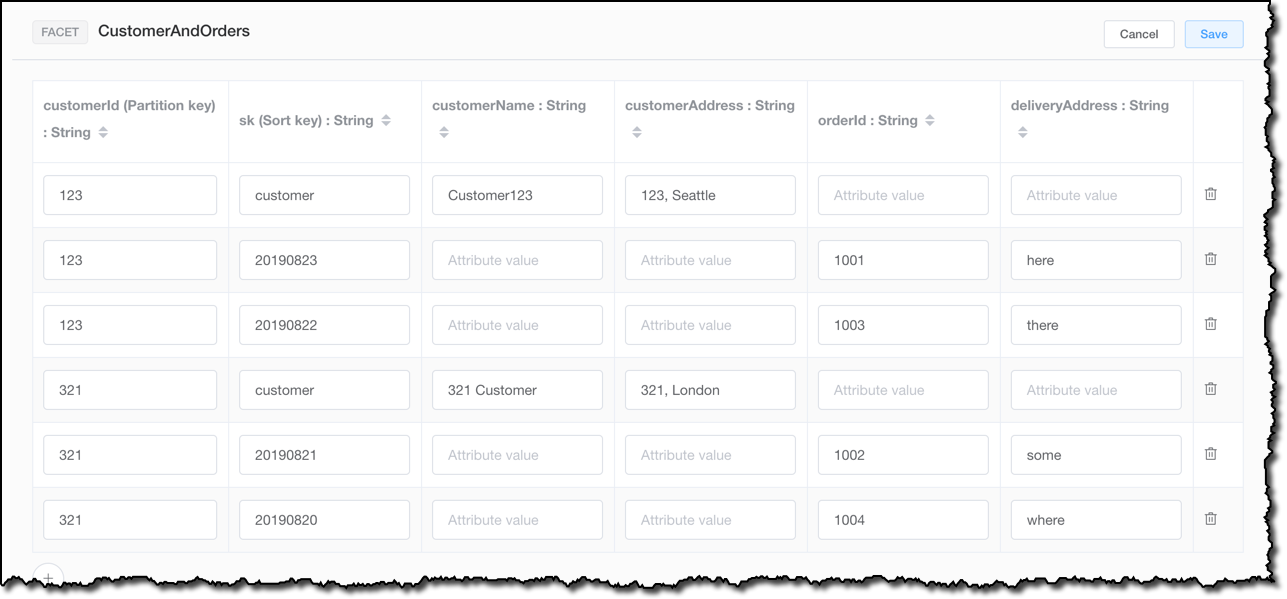
Now, I visualize my data model with the sample data to have a better understanding of what to expect from this table. For example, if I select a customerId, and I query for all the orders greater than a specific date, I also get the customer data at the end, because the string customer, stored in the sk sort key, is always greater that any date written in ISO 8601 syntax.
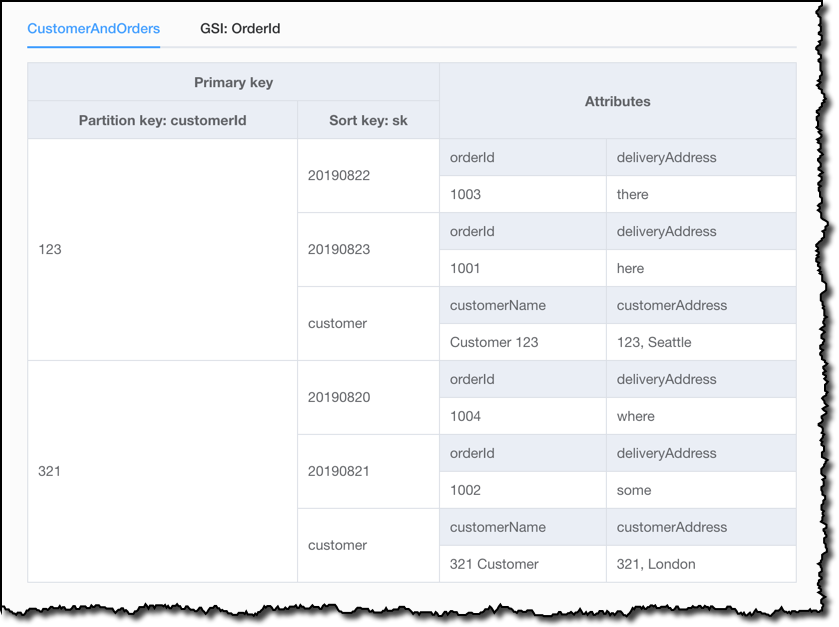
In the Visualizer, I can also see how the global secondary index on the orderId works. Interestingly, items without an orderId are not part of this index, so I get only 4 of the 6 items that are part of my sample data. This happens because DynamoDB writes a corresponding index entry only if the index sort key value is present in the item. If the sort key doesn’t appear in every table item, the index is said to be sparse. Sparse indexes are useful for queries over a subsection of a table.
I now commit my data model to DynamoDB. This step creates server-side resources such as tables and global secondary indexes for the selected data model, and loads the sample data. To do so, I need AWS credentials for an AWS account. I have the AWS Command Line Interface (CLI) installed and configured in the environment where I am using this tool, so I can just select one of my named profiles.
I move to the Operation builder, where I see all the tables in the selected AWS Region. I select the newly created CustomerAndOrders table to browse the data and build the code for the operations I need in my application.

In this case, I want to run a query that, for a specific customer, selects all orders more recent that a date I provide. As we saw previously, the overloaded sort key would also return the customer data as last item. The Operation builder can help you use the full syntax of DynamoDB operations, for example adding conditions and child expressions. In this case, I add the condition to only return orders where the deliveryAddress contains Seattle.

I have the option to execute the operation on the DynamoDB table, but this time I want to use the query in my application. To generate the code, I select between Python, JavaScript (Node.js), or Java.
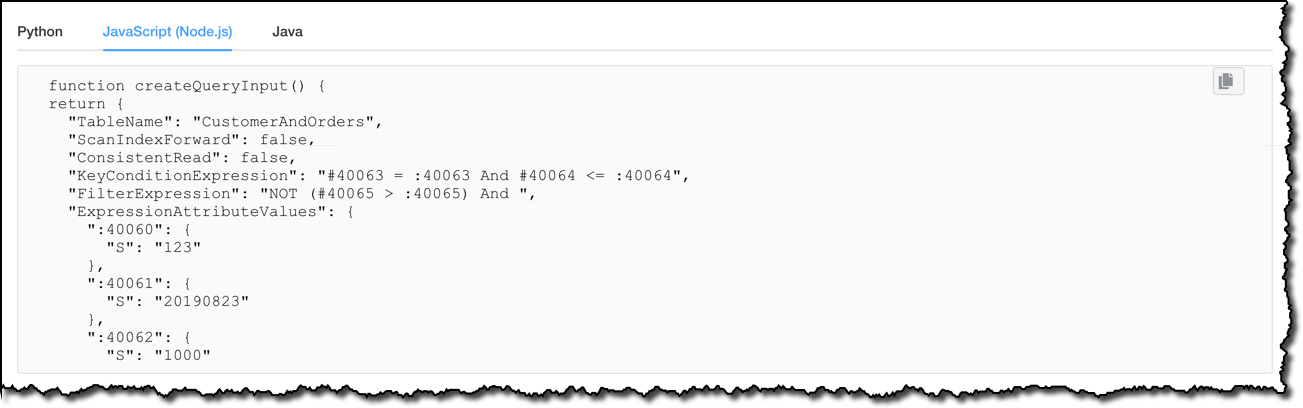
You can use the Operation builder to generate the code for all the access patterns that you plan to use with your application, using all the advanced features that DynamoDB provides, including ACID transactions.
Available Now
You can find how to set up NoSQL Workbench for Amazon DynamoDB (Preview) for Windows and macOS here.
We welcome your suggestions in the DynamoDB discussion forum. Let us know what you build with this new tool and how we can help you more!



Source: AWS News