Western Digital HDD Simulation at Cloud Scale – 2.5 Million HPC Tasks, 40K EC2 Spot Instances
Earlier this month my colleague Bala Thekkedath published a story about Extreme Scale HPC and talked about how AWS customer Western Digital built a cloud-scale HPC cluster on AWS and used it to simulate crucial elements of upcoming head designs for their next-generation hard disk drives (HDD).
The simulation described in the story encompassed a little over 2.5 million tasks, and ran to completion in just 8 hours on a million-vCPU Amazon EC2 cluster. As Bala shared in his story, much of the simulation work at Western Digital revolves around the need to evaluate different combinations of technologies and solutions that comprise an HDD. The engineers focus on cramming ever-more data into the same space, improving storage capacity and increasing transfer speed in the process. Simulating millions of combinations of materials, energy levels, and rotational speeds allows them to pursue the highest density and the fastest read-write times. Getting the results more quickly allows them to make better decisions and lets them get new products to market more rapidly than before.
Here’s a visualization of Western Digital’s energy-assisted recording process in action. The top stripe represents the magnetism; the middle one represents the added energy (heat); and the bottom one represents the actual data written to the medium via the combination of magnetism and heat:

I recently spoke to my colleagues and to the teams at Western Digital and Univa who worked together to make this record-breaking run a reality. My goal was to find out more about how they prepared for this run, see what they learned, and to share it with you in case you are ready to run a large-scale job of your own.
Ramping Up
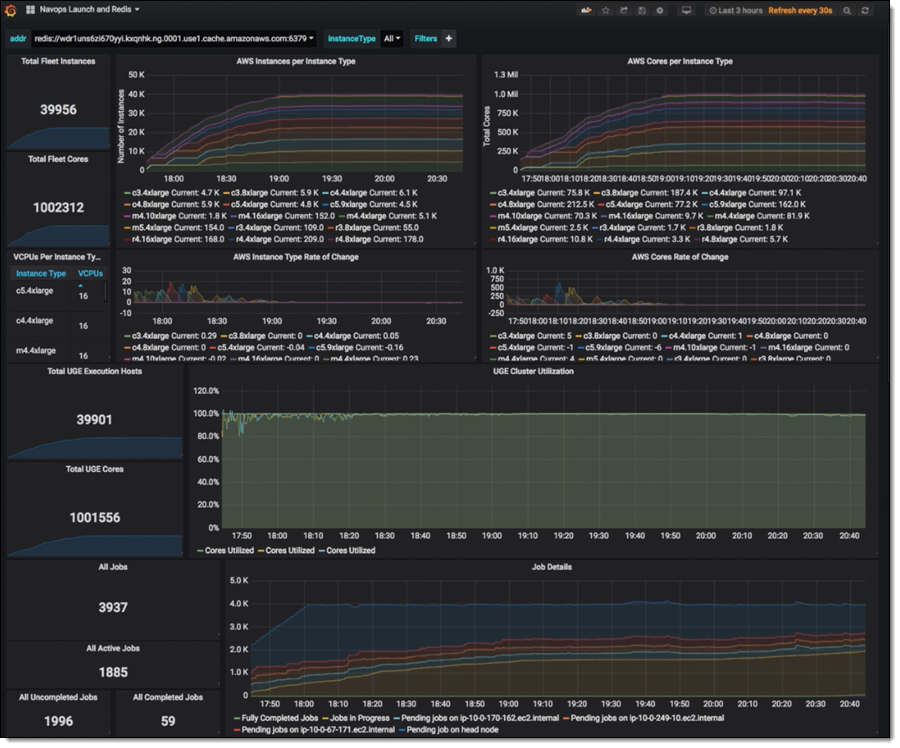
 About two years ago, the Western Digital team was running clusters as big as 80K vCPUs, powered by EC2 Spot Instances in order to be as cost-effective as possible. They had grown to the 80K vCPU level after repeated, successful runs with 8K, 16K, and 32K vCPUs. After these early successes, they decided to shoot for the moon, push the boundaries, and work toward a one million vCPU run. They knew that this would stress and tax their existing tools, and settled on a find/fix/scale-some-more methodology.
About two years ago, the Western Digital team was running clusters as big as 80K vCPUs, powered by EC2 Spot Instances in order to be as cost-effective as possible. They had grown to the 80K vCPU level after repeated, successful runs with 8K, 16K, and 32K vCPUs. After these early successes, they decided to shoot for the moon, push the boundaries, and work toward a one million vCPU run. They knew that this would stress and tax their existing tools, and settled on a find/fix/scale-some-more methodology.
Univa’s Grid Engine is a batch scheduler. It is responsible for keeping track of the available compute resources (EC2 instances) and dispatching work to the instances as quickly and efficiently as possible. The goal is to get the job done in the smallest amount of time and at the lowest cost. Univa’s Navops Launch supports container-based computing and also played a critical role in this run by allowing the same containers to be used for Grid Engine and AWS Batch.
One interesting scaling challenge arose when 50K hosts created concurrent connections to the Grid Engine scheduler. Once running, the scheduler can dispatch up to 3000 tasks per second, with an extra burst in the (relatively rare) case that an instance terminates unexpectedly and signals the need to reschedule 64 or more tasks as quickly as possible. The team also found that referencing worker instances by IP addresses allowed them to sidestep some internal (AWS) rate limits on the number of DNS lookups per Elastic Network Interface.
The entire simulation is packed in a Docker container for ease of use. When newly launched instances come online they register their specs (instance type, IP address, vCPU count, memory, and so forth) in an ElastiCache for Redis cluster. Grid Engine uses this data to find and manage instances; this is more efficient and scalable than calling DescribeInstances continually.
The simulation tasks read and write data from Amazon Simple Storage Service (S3), taking advantage of S3’s ability to store vast amounts of data and to handle any conceivable request rate.
Inside a Simulation Task
Each potential head design is described by a collection of parameters; the overall simulation run consists of an exploration of this parameter space. The results of the run help the designers to find designs that are buildable, reliable, and manufacturable. This particular run focused on modeling write operations.
Each simulation task ran for 2 to 3 hours, depending on the EC2 instance type. In order to avoid losing work if a Spot Instance is about to be terminated, the tasks checkpoint themselves to S3 every 15 minutes, with a bit of extra logic to cover the important case where the job finishes after the termination signal but before the actual shutdown.
Making the Run
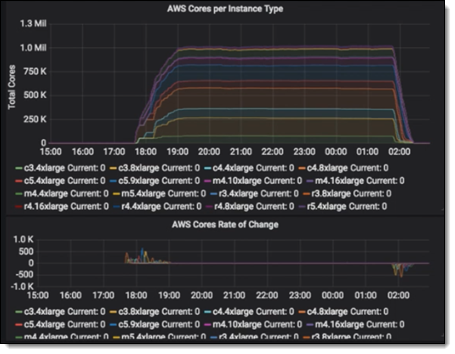
After just 6 weeks of planning and prep (including multiple large-scale AWS Batch runs to generate the input files), the combined Western Digital / Univa / AWS team was ready to make the full-scale run. They used an AWS CloudFormation template to start Grid Engine and launch the cluster. Due to the Redis-based tracking that I described earlier, they were able to start dispatching tasks to instances as soon as they became available. The cluster grew to one million vCPUs in 1 hour and 32 minutes and ran full-bore for 6 hours:
When there were no more undispatched tasks available, Grid Engine began to shut the instances down, reaching the zero-instance point in about an hour. During the run, Grid Engine was able to keep the instances fully supplied with work over 99% of the time. The run used a combination of C3, C4, M4, R3, R4, and M5 instances. Here’s the overall breakdown over the course of the run:
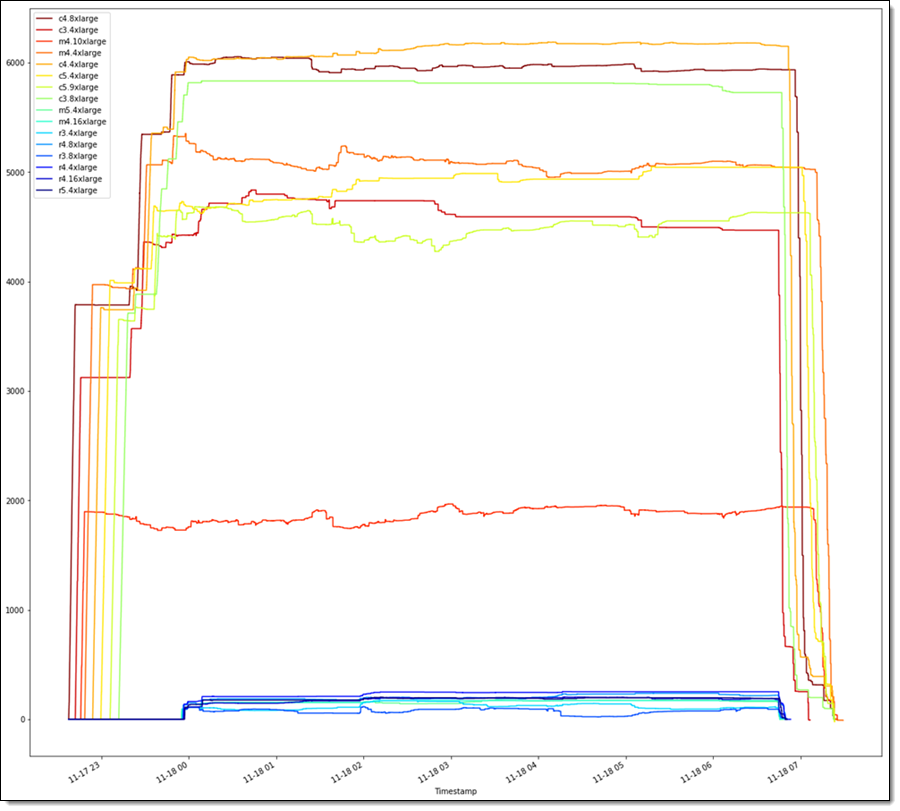
The job spanned all six Availability Zones in the US East (N. Virginia) Region. Spot bids were placed at the On-Demand price. Over the course of the run, about 1.5% of the instances in the fleet were terminated and automatically replaced; the vast majority of the instances stayed running for the entire time.
And That’s That
This job ran 8 hours and cost $137,307 ($17,164 per hour). The folks I talked to estimated that this was about half the cost of making the run on an in-house cluster, if they had one of that size!
Evaluating the success of the run, Steve Phillpott (CIO of Western Digital) told us:
 “Storage technology is amazingly complex and we’re constantly pushing the limits of physics and engineering to deliver next-generation capacities and technical innovation. This successful collaboration with AWS shows the extreme scale, power and agility of cloud-based HPC to help us run complex simulations for future storage architecture analysis and materials science explorations. Using AWS to easily shrink simulation time from 20 days to 8 hours allows Western Digital R&D teams to explore new designs and innovations at a pace un-imaginable just a short time ago.”
“Storage technology is amazingly complex and we’re constantly pushing the limits of physics and engineering to deliver next-generation capacities and technical innovation. This successful collaboration with AWS shows the extreme scale, power and agility of cloud-based HPC to help us run complex simulations for future storage architecture analysis and materials science explorations. Using AWS to easily shrink simulation time from 20 days to 8 hours allows Western Digital R&D teams to explore new designs and innovations at a pace un-imaginable just a short time ago.”
The Western Digital team behind this one is hiring an R&D Engineering Technologist; they also have many other open positions!
A Run for You
If you want to do a run on the order of 100K to 1M cores (or more), our HPC team is ready to help, as are our friends at Univa. To get started, Contact HPC Sales!
— Jeff;



Source: AWS News